
OpenAI o1はどう作るのか(詳細編)

1. はじめに
前回、OpenAI o1をどう作るかについて概要レベルで議論しました。
OpenAI o1が新しい強化学習手法を用いて強化されたモデルであることは確実であり、具体的にどういうロジックで学習されているか考えていきたいと思います。
強化学習について間違った理解があればご指摘ください。(一応学習はしたものの普段使いしているわけではないので忘れているところもあると思います。)
2. 強化学習の手法
一般的に強化学習において、最終的な目標は方策モデル(方策関数)の性能を高めることにあると思います。
方策モデルとは、ある環境においてエージェントがどう動くのかを決定するモデル・アルゴリズムです。
迷路探索タスクにおいては次のステップの移動先を上下左右のマスから決定するアルゴリズムを指しますし、言語生成タスクにおいては文章を生成する主体であるLLM自体が方策モデルです。
方策モデルは、環境や報酬モデルから行動(選択)による長期的な価値の期待値を予測し、行動を決定します。
(長期的な価値を計算する機構を価値関数といいます。)
このような仕組みから、強化学習では方策改善のアプローチとして3つのパターンがあります。
価値ベースの手法(Value-Based Methods):価値関数を学習させ間接的に方策の精度を高める
方策ベースの手法(Policy-Based Methods):方策モデル自体を学習
Actor-Critic手法(Actor-Critic Methods):方策と価値関数のどちらも継続的に学習(価値ベース+方策ベース)
では、OpenAI o1の強化学習はどのアプローチなのでしょうか。RLHFをベースに考えていきます。
2.1 RLHFのアプローチ
以下はOpenAIのページから持ってきたRLHFの説明図です。
RLHFではStep 2で報酬モデルを作り、Step 3でLLM(方策モデル)を学習させます。Step 3では報酬モデルは基本的には固定され、報酬を返す関数として動作しているのでRLHFのアプローチは方策ベースの強化学習と言えそうです。
報酬モデルを学習している点で、価値+報酬ベースのActor-Criticのようにも見えますが、報酬モデルはあくまで環境の代替である点・報酬モデルは継続的な学習が行わない点で、Actor-Criticとは異なります。(報酬モデル≠価値関数)

Step 3のPPOでは以下を繰り返します。
方策モデル(LLM)によってInputに対する複数のOutputが出力されます。
Inputに対する各Outputの評価を報酬モデルが行います。
報酬が高いOutputを出力しやすいように方策モデル(LLM)の重みが更新(学習)されます。
この時、サンプリングされる学習データ(s, a, r, s')は、
s: 入力プロンプト
a: 生成されたテキスト全体
r: テキスト全体に対する単一の報酬
s': 入力プロンプ+生成されたテキスト全体
となります。RLHFは毎回1ステップで1施行が完了するタスクの強化学習と見做せるため、s'は使用されないみたいです。
* 一般的に強化学習ではs: 現在の状態, a: 取った行動, r: 得られた報酬, s': 次の状態 をサンプリングします。
具体的なPPOのワークフローを図にすると以下になります。

2.2 Google DeepMindの論文のアプローチ
Google DeepMindの論文 "Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters"のアプローチはどうでしょうか。振り返ってみます。
これは強化学習とは言えないと思います。
なぜなら報酬モデルの学習には人間からの評価を用いており、これは単なる教師あり学習です。また、方策モデル自体は重みが更新されていません。(学習されていない。)
3. OpenAI o1のアプローチ
3.1 方策ベースの手法
では上記のRLHFとDeepMind論文のアプローチをもとにOpenAI o1の強化学習方法を考えてみたいと思います。
少なくともDeepMind論文のアプローチは強化学習ではなく、考え方は似つつもここからさらに発展させたものであるものだと思われます。
手法としては、やはりRLHFを発展させた方法が最も自然に考えられます。(方策ベース)
つまり、Step 2で本来作られる報酬モデル(Inputに対してOutput全体が人間の嗜好にそうかどうかを評価するモデル)を作っていたのを、DeepMind論文のPRM(プロセス報酬モデル:Inputに対して思考ステップ毎、つまり1行毎の正確性・有用性を評価するモデル)を利用します。
PPOにおけるOutputの報酬計算をPRMを用いて行います。
この方法はさらに2つに分けられます。
各ステップの報酬の累計(+回答の正しさ)を報酬として、1施行毎に1サンプリングとする。(現行のRLHFのPPOに近い)
1ステップ毎に即時報酬を計算し、サンプリングする。(通常のPPOに近い)
1の場合は、サンプリングされる学習データ(s, a, r, s')は、
s: 入力プロンプト
a: 生成されたテキスト全体
r: 各ステップの報酬の累計(+回答の正しさ)が単一の報酬
s': 入力プロンプ+生成されたテキスト全体
となります。この(s, a, r)を使って、RLHFのPPOのように学習します。
2の場合は、サンプリングされる学習データ(s, a, r, s')は、
s: 入力プロンプト (+これまでに生成された行)
a: 新しく生成された行
r: その行に対する報酬
s': 入力プロンプト (+ これまでに生成された行) + 新しく生成された行
となります。この(s, a, r, s')を使って、通常のPPOのように学習します。
実装の難易度的には 1 < 2 であり、効果的には 1 > 2なのではないかと思います。(1は既存のTRLなどのライブラリを一部使い回せそうなため)
2を先ほどのPPOのワークフローに当てはめると以下のようになります。(1のワークフロー自体は既存RLHFのPPOと同様になると思います。)
各ステップ毎にPolicy Optimizationのデータとなります。(文字が小さくて恐縮です。)

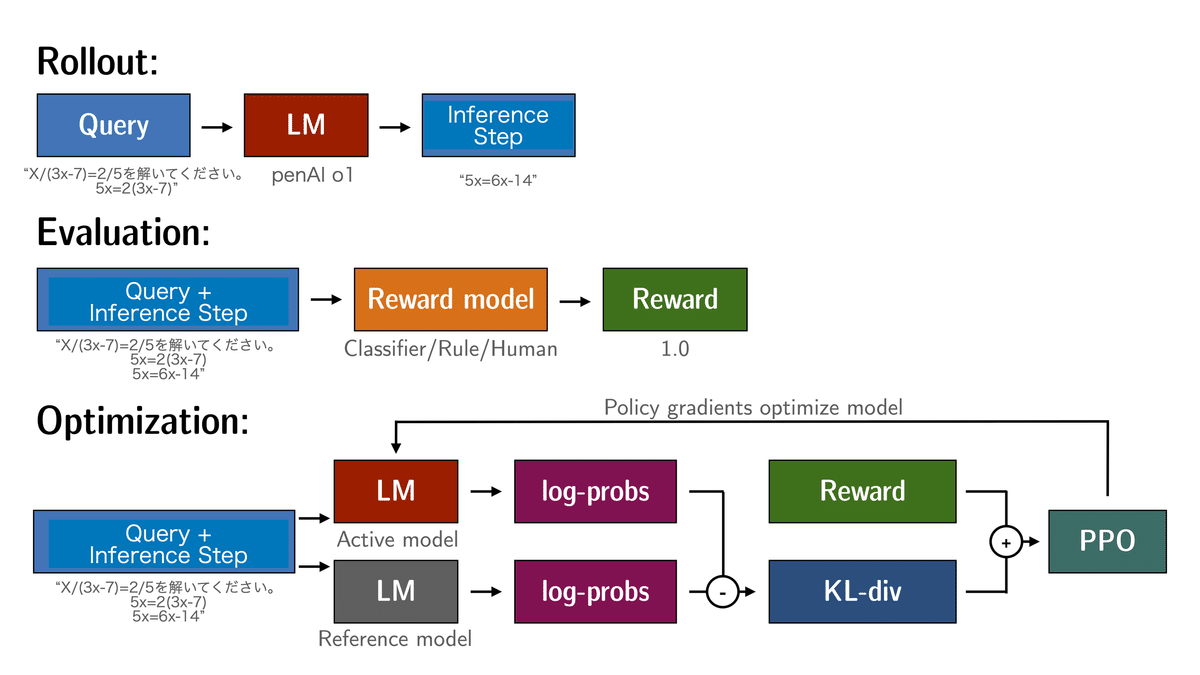
効果的にもOpenAI o1は2のパターンを実施しているのではないかと考えます。
3.2 価値ベースの手法
では、価値ベースの強化学習の可能性はあるのでしょうか。
PRMを使うことを前提に考えると、PRM+報酬を元にした探索アルゴリズムを価値関数と捉えると可能ではあると思います。
ざっくり考えると、
(DeepMindの手法で)PRMを作る
LLMにPRM+探索アルゴリズムを使って推論させる
正解に辿り着いたかどうかでその推論ステップ全体を評価。(PRMの重みを更新)
を繰り返すことでPRMを学習させていくことはできそうです。
ただし、正解があるデータでしか学習できないこと、良い推論ステップがあっても後半に悪い推論ステップが入ることで悪く評価されることへの懸念があります。
(正解がないデータに対しても、正解不正解を通常のRLHFの報酬モデルにつけさせればできるかも??)
3.3 Actor-Critic手法
Actor-Critic手法に関しても学習の不安定性が課題になると思います。
試すにしても方策ベースでの成果が得られてからになるのではないでしょうか。
3.4 疑問と可能性
上記の通り、方策ベースの強化学習を行なっている可能性が高いと思います。ただし、それだと下記2点で疑問が残ります。
① 方策ベースで学習した場合、推論時にはそこまでOpenAI o1のようにたくさんのステップを踏んで推論するようになるのか?
→ 理論の飛躍がPRMによって低評価を受けるためたくさんのステップを踏むようになるのはないか。
② たくさんのステップを踏んで推論するようになるとして、それでも20-30秒程度も出力に時間がかかるのか?
→ トークンの探索を行うように、1行毎の推論ステップの探索も推論時に行なっているのではないか。
それには上記のように考えました。
4. まとめ
前回の概要レベルの話から、強化学習の手法、サンプリングデータについて考えてみました。(前回同様、私の知識不足からくる間違えやミスリードが含まれる可能性があることに注意してください。)
結論としては、2つの方策ベースの強化学習が有力だと考えます。
そのうちの特に『1ステップ毎に即時報酬を計算し、サンプリングする』が採用されていると思います。
ただし、疑問が残る点もあるため、Anthoropicなどによって検証が進んでいくと良いなと思います。
日本勢がOpenAI o1に追随する手助けになると良いと思います。議論のたたきとして利用してくだされば幸いです。
何か議論や感想があればNoteやX(Twitter)でコメント・ご教示いただけると助かります。
私自身新たな気づきがあれば追記していこうと思います。
X: https://twitter.com/CurveWeb
目を通していただきありがとうございました。
関連
参照
この記事が気に入ったらサポートをしてみませんか?