
ユーザーに合った学習コースを届けるための第一歩・・・グロービス学び放題のコース情報のembeddingをVertex AI Custom Training Jobで作成する。

はじめに
こんにちは!グロービスデジタルプラットフォーム部門データサイエンスチームの機械学習エンジニアの田邊です。
グロービスデジタルプラットフォーム部門では、ここ数年でデータ基盤の整備を着々と進めており、データを活用した価値提供という観点での動きを促進するための取り組みを行なっています。
その一環として、現在私はグロービス学び放題において機械学習を活用したレコメンドエンジン改善プロジェクトに取り組んでいます。
今回はこれまで取り組んできた内容の一部である、グロービス学び放題のコース情報を定量的に扱うためのembedding(埋め込み表現)というものを作成する取り組みと、Google Cloud PlatformのVertex AIというサービスを活用して運用していく流れについてご紹介できればと思います。
グロービス学び放題の学習コンテンツはパワーアップしているが・・・
グロービス学び放題はビジネススキルを身につけたい社会人向けに、様々なカテゴリーの学習動画コンテンツ(コース)を提供しているサービスです。グロービスの提供する学習サービスの中でも最もお手軽に始められるものとなっており、コースの数もここ数ヶ月で200件近く増えてバリエーションも多彩になってきているので、より多くの人々にとって役に立つサービスへと進化しつつあります。
しかし学習コンテンツのボリュームが増えるほど、ユーザーはどこから学習を始めたら良いのか判断しづらくなり、せっかくその人にとって良い学習コンテンツがあっても、そのコンテンツに巡り会えず学習が続かないといったことも発生しやすくなります。
そこでユーザーにとって最適な学習を提供する仕組みを整えていくことが求められるのですが、そこに一役買って出てくれるのがレコメンドエンジンです。
ユーザーにとって最適なコースをレコメンドするには
グロービス学び放題の中には現在2種類のレコメンド機能が実装されています。
1つ目はトップ画面に表示のある「おすすめのコース」

2つ目はコース詳細ページにある「関連コース」
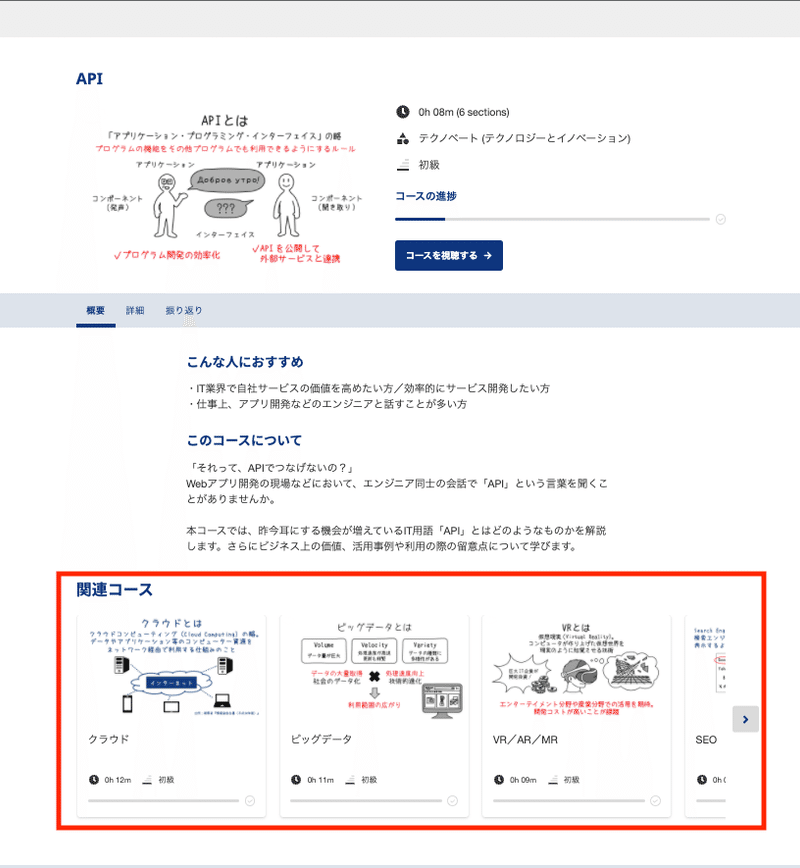
です。
いずれも全ユーザーの視聴履歴データのみをベースに抽出されるようなシンプルなものとなっており、ユーザーにとって一定の効果は期待できるものの、以下のような課題があります。
ユーザー全体の視聴履歴のみしか考慮できておらず、普遍的なものに止まってしまっているため変わり映えしない。
コースの内容を考慮したものになっていないため、関連性の低いコースがおすすめされているケースもある。特にまだ視聴履歴データの少ない新着コースに対しては顕著である。
これらの課題を解決しなければ、一人一人のユーザーに合ったコースをレコメンドするのは難しい状況です。
ではどうすれば良いでしょうか。
ユーザーに合ったコースをピックアップするためには、それぞれのコースの内容に関する情報を考慮することは欠かせません。
グロービス学び放題のデータ基盤上にはユーザーやコースに関する情報や行動ログのデータも整えられていますが、その中でもまだ有効活用できていないデータや属性などが多く存在しています。
それらを活用することで、まずはコースの内容を考慮できるようにし、ユーザーが視聴したコースに対してより関連度の高いものが表示されるような仕組みを導入していくことにしました。
コース情報をどのようにコンピュータに理解させるか
コースの内容を考慮する場合、主にその内容が記述されたテキストデータを活用することになります。 人間であればテキストを読めば内容を理解することはできますが、コンピュータにその内容を理解させるには何らかの方法で数値情報に変換し、定量的に表現する方法を考える必要があります。
いくつか方法は考えられますが、今回は単語の分散表現を活用したコースのembeddingを獲得するという方針で取り組むことにしました。
単語の分散表現とはテキストデータを数値として表現する方法の一つで、テキスト中の単語に対しその前後関係から当てはまる単語を予測するタスクをモデルに課し、学習結果として得られた単語ごとに対応する高次元ベクトル表現のことを指します。
また、embeddingとは高次元の密なベクトルによって表現されたデータで、埋め込み表現とも呼ばれますが、形式的には分散表現と同じものになります。embedding(埋め込み表現)というワードを今回使っているのは、レコメンドモデルや関連コース抽出アルゴリズムにおいて「コースごとの特徴を実数空間に埋め込んで表現しているもの」として活用したい意図があるためです。
具体的な方法は後述しますが、以下のような流れでコースのテキストデータからembeddingを作成し、最終的に得られたembeddingによって、コース同士の関連度の算出等、コースの情報を定量的に扱えるようにしていきます。

データの準備
まずデータの準備ですが、コースの内容として今回新たに以下の項目にあるテキスト情報を活用することにしました。
コースタイトル
コース詳細ページの概要などの記述
ユーザーのコース振り返りコメント
コース情報を加味するのであればコースタイトルや概要の記述のみで十分なのではないかと思われるかもしれませんが、それだけだと情報量が少なすぎたため、ユーザーによって記述された各コースに対する振り返りコメントもコースの内容を表すものとして一部活用することにしました。
データの前処理
コースごとのテキストデータ全てをそのまま扱うとコースの内容とは直接関係のない不要な部分が含まれてしまい、数値情報に変換する際のノイズや処理コスト増加につながり得るため、まずは事前に不要な部分を除去していきます。
例えば、「知見録Premium」というカテゴリの一部コースには概要の記述に以下のような文言が含まれています。
'※本動画は出演者への事前許諾のもと、GLOBIS知見録より転載させて頂いています。ご協力頂き感謝申し上げます。'この文言自体はコースの内容に直接関係のあるものではないと考えられるため、前処理の段階で除去するようにしています。
次にテキストに対して不要な記号の除去や形態素解析といった処理を経て、コースごとにその内容を色濃く反映しているであろう単語のみを抽出します。
例えば「クリティカル・シンキング(論理思考編)」のコース情報から形態素解析によって名詞のみ抽出すると、以下のような単語一覧を得ることができます。
クリティカルシンキング, 論理, 思考, 編, 業種, 職種, 役職, ビジネスパーソン, ・・・しかし、このままではテキスト内で出てきた順に並んでいるだけなので、どの単語がこのコースを色濃く反映する特徴的な単語なのかまでははっきりとは分かりません。
そこで、さらに抽出した単語の中から、そのコース情報に特徴的な単語を見極めるためTF-IDFによるスコアも算出しておきます。
詳細はここでは割愛しますが、TF-IDFによって全コース情報に現れる単語の出現頻度とそれぞれのコース情報に現れる単語の出現頻度を考慮したスコアリングを行うことができるようになり、各コースの特徴をより捉えた単語に注目しやすくなります。
「クリティカル・シンキング(論理思考編)」の単語一覧をTF-IDFによるスコアの高い順=特徴的である順に並び替えると以下のようになります。
イシュー, クリティカルシンキング, ピラミッド, ストラクチャー, 帰納法, 演繹法, ・・・実際に「クリティカル・シンキング(論理思考編)」の内容に沿った特徴的な単語が先頭に出てきており、コース内容を表すのに重要な単語の抽出に繋がっているように見受けられます。
単語を分散表現に変換し、それらを統合してコース情報を表すembeddingを作成する
単語の分散表現獲得のため、今回はFastTextと呼ばれるモデルを活用しています。
FastTextは単語よりもさらに小さなサブワードと呼ばれる分割単位による分散表現を獲得するモデルで、未知語対応などにおいてメリットが挙げられます。
また、公式サイトに言語別のWebのクローリングデータやWikipediaのデータで学習済みのモデルが公開されており、既に大量のテキストコーパスから獲得した分散表現をそのまま使えるようになっているので、非常に導入しやすい形になっています。
TF-IDFによるスコアリングを適用した「クリティカル・シンキング(論理思考編)」の単語一覧を例に、それぞれの単語に対してFastTextの日本語学習済みモデルによる分散表現への変換を行い、さらにそれらを統合してコースのembeddingを作成する処理の流れを組むと以下のようになります。
import numpy as np
import fasttext
# コースのテキストデータから抽出した単語一覧
sample_course_tokens = ["イシュー", "クリティカルシンキング", "ピラミッド", "ストラクチャー", "帰納法", "演繹法"]
# 単語一覧に対するtfidfスコアの重み
sample_tfidf_score_weights = [0.99995186, 0.81079066, 0.78523159, 0.77025113, 0.62211252, 0.57767591]
# 日本語学習済みFastTextのモデルをロード
ft = fasttext.load_model('cc.ja.300.bin')
# コースのテキストデータから抽出した単語一覧を分散表現に変換
vectors = [ft.get_word_vector(token) for token in sample_course_tokens]
# 各単語を分散表現に変換したものを平均
sample_course_embedding = np.average(vectors, axis=0, weights=sample_tfidf_score_weights)
各単語を分散表現に変換すると、300次元のベクトルとして表されるので、一つのコース情報からは300次元のベクトルが抽出された単語の数だけ得られます。 それらの平均をとってコースの情報を表す1個のベクトル=embeddingと見なすのですが、コース内容を表す特徴的な単語を計算上重要視したいため、データの前処理のところで算出したTF-IDFスコアの値を活用して重みつき平均を取る形にしています。
以上の方法で全てのコースに対してembeddingを作成するのですが、実際にコースの内容をうまく反映できているのかどうかを、embedding空間上での分布を可視化して確認してみます。
獲得したコースembeddingはコースの内容をうまく表すものとなっているのか?
上で作成したコースのembeddingは単語の分散表現と同じ300次元のベクトルとなっていますが、これを平面上で可視化するには次元圧縮と呼ばれる手法によって次元数を落とす必要があります。
次元圧縮についてもここでは深入りしませんが、高次元で表されているデータに対して情報をなるべく維持しつつ次元数を落とすというもので、データの分布の特徴をプロットして目で把握したいといった場合などに役立ちます。
ここでは2次元平面上にプロットして確認をするため、300次元→2次元の圧縮をUMAPという手法によって実施しました。
コース全体のembeddingを2次元に圧縮したものをコースのカテゴリ別に色分けしてプロットした結果が下の図になります。
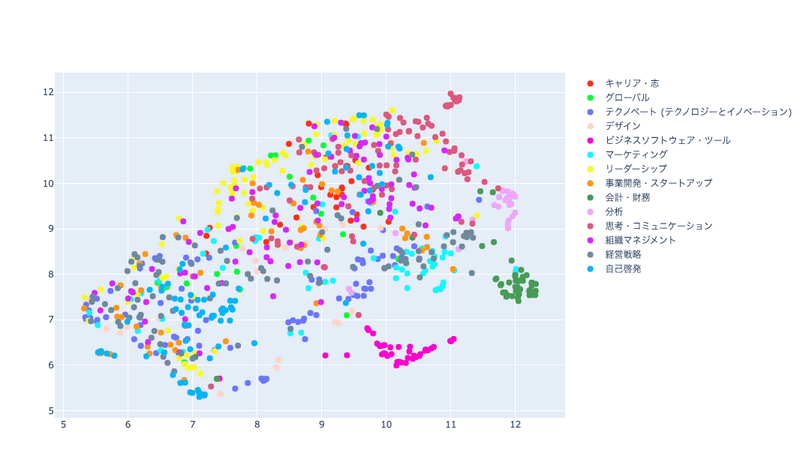
「分析」「ビジネスソフトウェア・ツール」「会計・財務」といったある程度専門的な内容のカテゴリーについては他のコースと比べて一箇所にまとまって分布しているように見受けられます。
一方「キャリア・志」「マーケティング」といった内容的にも専門領域の枠組みに囚われないようなカテゴリーについては広い範囲に渡って横断的に分布していたり、同カテゴリの中でも小さな群をなすものもあったりします。
このようにカテゴリーごとに見比べると、全体としてカテゴリーの性質に沿った形での分布になっていそうな印象があり、良い感じにコースのembeddingが作られていそうな気がします。
ではコース一つ一つにより注目して見るとどうでしょうか。 コース情報を定量的に表すことで、内容に関連性のあるコースや似ているコース同士がプロット上も近くに分布し、そうでないコース同士は遠くに分布してくれることが期待されるのですが、実際どうなっているのか、プロット図を拡大して確かめてみることにします。
以下は「意思決定」に関するコースが「思考・コミュニケーション」「経営戦略」「分析」の3種類のカテゴリにまたがって関連度の高いコースとして近くに分布している例で、これは非常に良い結果となっているのではないかと捉えられます。

しかしながら上記のように良い感じの分布になっていないケースもあり、例えば以下の図において「【耳で復習】学んでみたけど?~MECE~」というコースに注目すると、周りにはあまり関連性の高そうなコースは見受けられません。MECEに関するコースは他にもいくつか存在していますが、それらは近くには分布していない結果となっています。

ここまで単語の分散表現を活用したコースembeddingの作成についてご紹介してきましたが、この結果をグロービス学び放題のアプリやコンテンツ開発に関わっている社内の関係者にも定性的に評価していただいたところ好印象を持っていただけました。
改善の余地はまだ大いにあるものの、定性的にはレコメンドや関連コース検索などにおいて活用する分にはそれなりに機能してくれそうだという期待が持てるものになっているのではないかと思います。
日々追加・更新されるコースにキャッチアップするために
冒頭でも述べたように、グロービス学び放題の学習コースは日々新しいものが増えている状況で、それに合わせてコースのembeddingも遅れを取らないよう定期的に更新をかけて行かなければなりません。
そのためコースembedding作成のスクリプトをバッチで定期実行する仕組みを導入する必要があります。
以前のテックマガジン記事においてもご紹介させていただいたように、グロービスのデータ基盤ではGoogle Cloud Platform(GCP)のBigQueryを利用したデータ活用を行っています。そのためBigQueryとの連携のしやすさであったり、将来的にはレコメンドモデルの継続的な運用を想定したMLOpsの構築に繋げられるものという観点から、同プラットフォーム上の機械学習モデル開発・運用向けのサービスであるVertex AIを使って実装していくことにしました。
Vertex AIの紹介
Vertex AIはデータ準備から特徴量エンジニアリング、モデル学習、評価、推論エンドポイントのデプロイまで一貫したサポート機能を提供してくれる、機械学習モデルの開発・運用に特化したプラットフォームサービスです。
モデル開発においてはデータ形式に応じて自動でモデル構築を行ってくれるAutoMLを使うことも可能ですし、自前で実装する場合でも学習用コードを含んだコンテナをビルドしてレジストリへPushしておき、カスタムトレーニングジョブとしてVertex AI環境上で実行することも可能で、幅広いユースケースに対応できる仕様となっています。
また、学習済みモデルのオンライン予測エンドポイントをサービングしてくれる機能も存在し、トレーニングジョブの結果として生成されるモデルアーティファクトと呼ばれるファイル一式の保存先と予測用のコンテナイメージを指定することで、トレーニングジョブと連動した予測機能のサービングを自動で担ってくれるようなパイプラインを構築することも可能です。
その他にも特徴量のリポジトリとしてのFeature Storeや、モデルの管理・モニタリングをサポートしてくれる機能が提供されており、機械学習モデルを運用する上で非常に有益な機能が備わっています。

カスタムトレーニングジョブでコースembeddingを作成する
今回はVertex AIのカスタムトレーニングジョブを活用してコースのembeddingを作成する流れを構築しました。
カスタムトレーニングジョブというと、主に機械学習モデルの学習を行うジョブとしての利用が想定されますが、実際は任意のPythonスクリプトを機械学習向けの計算リソース上で実行できるようになっているため、よりざっくりと「カスタムバッチ処理を実行するためのジョブ」として活用の幅を広げて捉えることができます。
実装においてはトレーニングコードの要件に沿った形を取る必要がありますが、今回はコースembedding作成を行うカスタムコンテナイメージを用意し、Google Container RegistryにPushしたものを呼び出す以下のような構成としました。

イメージのビルドに必要なDockerfileではカスタムトレーニングジョブとして実行される際に走らせるコマンドをENTRYPOINT として設定しておきます。下記の例ではsrc/trainer/train.py がカスタムトレーニングジョブで実行されるスクリプトとして指定されています。
FROM python:3.9
WORKDIR /app
COPY requirements.txt .
RUN pip install -r requirements.txt
# Copy scripts to the container
COPY . /app
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "src.trainer.train"]
スクリプトに対して更新や修正があった場合にイメージの方も自動で更新されるよう、GitHub Actionsのワークフローを用いてビルドとデプロイの自動化を行います。
ワークフローではイメージのバージョン管理のため日付情報をベースとしたタグと、運用時にカスタムトレーニングジョブが参照するリリースバージョンのタグをそれぞれ用意し、イメージタグとして付与させてビルド後GCRへPushします。
name: Build and Push Course Embedding Model
on:
...
env:
IMAGE_NAME: <イメージ名>
PROJECT_PATH: <ソースコードが置かれているディレクトリへのパス>
RELEASE_TAG_NAME: <リリースバージョンのタグ名>
GCP_PROJECT_ID: <GCPのプロジェクトID>
jobs:
build:
runs-on: ubuntu-latest
steps:
- name: checkout
uses: actions/checkout@v2
- name: auth
uses: google-github-actions/auth@v0
with:
credentials_json: <環境変数などに設定したクレデンシャルファイルの情報>
- id: datetime
name: Get datetime (Asia/Tokyo)
run: echo "::set-output name=DATETIME_TAG::$(TZ='Asia/Tokyo' date '+%Y%m%d-%H%M%S')"
- name: Configure Docker
run: |
gcloud auth configure-docker
- name: Build Docker Image
run: |
docker build \\
-t gcr.io/$GCP_PROJECT_ID/$IMAGE_NAME:${{ steps.datetime.outputs.DATETIME_TAG }} \\
-t gcr.io/$GCP_PROJECT_ID/$IMAGE_NAME:$RELEASE_TAG_NAME \\
.
working-directory: ${{ env.PROJECT_PATH }}
- name: Push Docker Image to GCR
run: |
docker push -a gcr.io/${GCP_PROJECT_ID}/${IMAGE_NAME}
イメージをGCR上へPushできたら、Vertex AIカスタムトレーニングジョブとして定期実行するため、カスタムトレーニングジョブ作成のAPIリクエストを行うタスクを含むDAGをCloud Composerへ追加します。
実装としては下記の通りカスタムトレーニングジョブを作成するための方法としていくつか選択肢があるので、環境に応じて適切なものを採用すると良いでしょう。
Google Cloudが提供するカスタムジョブ実行方法一覧
Airflow Hookから実行する場合
シンプルですが、ひとまずこれでコースのembeddingが定期的に作成・更新されるよう設計することができました。
今後の展望
ここまででグロービス学び放題のコース情報のデータから、自動で定期的にそれぞれのコース情報を定量的に表現したembeddingを作成する仕組みが出来上がり、各コースに対して関連性の高いものを算出するロジックと統合したり、レコメンドエンジンのコアとなる推論モデルの特徴量や候補抽出のために活用する準備が出来ました。
プロジェクトの今後の展望としては主に以下の2点を考えています。
コースembeddingを活用した関連コース一覧表示の改善
直近の視聴コース情報を加味したユーザーにとって最適化されたおすすめコースの表示
1.についてはユーザーの視聴履歴のデータも考慮した関連コース一覧の作成という形で実装が進んでおり、現在第一弾リリースに向けたオンライン検証実施準備が行われています。
ただ、テキストデータの前処理の改善やTransformerベースのモデルを活用したembeddingの作成など、アプローチにおいては改善の余地がまだまだ残されている状況で、アップデート頻度をさらに高めて改善サイクルを回していかなければなりません。
また、2.については機械学習の推論モデルを活用したアプローチになるため、今回のコースembedding作成ジョブと連動したデータセット作成、特徴量エンジニアリング、モデル学習・評価、そしてデプロイのパイプラインの構築に取り組む必要があります。
総じて、レコメンドエンジンを開発・運用するためのMLOps構築というところが大きな目標となっており、機械学習モデルの開発とその運用に必要な下記コンポーネントを整備していくことが課題となります。
CI/CD
ワークフロー制御
再現性の確立
データ、モデル、コードのバージョニング
コラボレーション機能
継続的なモデル学習・評価を行う機能
メタデータの管理
継続的なモニタリング
フィードバックループ
(参考)
Machine Learning Operations(MLOps): Overview, Definition, and Architecture
最後に
今回はグロービス学び放題のレコメンドエンジン改善プロジェクトの取り組みの一部として、コースの情報を定量的に扱うためのembedding作成と、それを運用に乗せるための仕組みとしてのVertex AI活用について簡単にご紹介させていただきました。
まだまだ技術的にもたくさん出来ることはあり、ユーザーにとって最適な学習を提供するためのレコメンドエンジンに仕上げていくにはこれからも多くの課題に取り組む必要があります。
現在グロービスのデータサイエンスチームでは個々のユーザーにとってより良い学習機会を提供し、新たな一歩を踏み出すきっかけに少しでも繋げられるようなサービスを一緒に作り上げていく仲間を募集しています。
この記事をきっかけに少しでも興味を持たれた方がいらっしゃったら、ぜひお気軽にご連絡ください!
この記事が気に入ったらサポートをしてみませんか?