Salesforce謹製AIのEinstein(予測ビルダー)の使い方をプロダクトマネージャーに直接教えてもらった一部始終の記録とその結果

2019.10.3 続編書きました
リバネスの吉田丈治です。
これまで何度か、AIを使って業務効率を上げる必要性について書いてきました。参考
ここでは、以前予告した通り、実際にAIをどのようにして実務に活かしていくのかについて、具体的な方法を記しながら説明していきたいと思います。2ヶ月半に渡って教えてもらいながら試行錯誤してきた全記録になります。
使用するプラットフォーム:Salesforce Einstein Prediction Builder
また、こちらの記事の執筆に当たり、Salesforce Einstein Senior Product ManagerのEdward Sandovalさんの協力を得ています。
Salesforceの予測ビルダーについては、こちらの「Salesforce予測ビルダーでタイタニックのデータを分析してみた」を目にした人がいるかも知れません。こちらの記事では、サンプルを使ってサクサクと答えまでたどり着いているのが分かります。理想的なデータを使うことによって、高精度に結果が得られるという可能性が示唆されています。
しかし、これを実務でやろうとするとそう簡単には行きません。実際にはデータセットを準備し、モデルを作成し、試行錯誤を経てできる限り理想的なモデルにたどり着くというプロセスをたどることになります。
こちらの記事に書かれていなかった、デバッグの方法、結果をどのように考えたら良いのか、更にブラッシュアップするにはどうすべきかといったことについて興味があれば、最後まで読んでみてください。
Einstein予測ビルダーについてのTrailheadはこちらにあります。
データセットを作成する
今回は、タイタニックの記事と同様に、人に関するデータをカスタムオブジェクトに格納しようと思います。
弊社リバネスでは、リバネスIDというカスタムオブジェクトに、個人に関するデータを全て集約しています。
今回想定するストーリー
こちらでは、弊社の企画であるリバネス研究費に申請する可能性を予測しようと思います。
その他に想定され得るデータセット例
実務でいうと色々考えられるのですが、こんなパターンがあり得るでしょうか
・商談
・どの商談が獲得確立が高いのかを予測する。こちらはSales Cloud Einsteinがやってくれるので予測ビルダーの出番はなさそうです
・炎上可能性を予測する。プロジェクトの進捗データが商談に紐付いていれば、予測できる可能性があります
・リード:どのリードが商談に繋がりそうなのかを予測する。こちらについても上記同様Sales Cloud Einsteinがやってくれます。
・名刺オブジェクト:読み込んだ名刺が格納されたカスタムオブジェクトがあれば、Sales Cloud Einstein的な実装可能性が考えられます
・ユーザ:最近流行りの離職可能性を予測するようなことができるかもしれません
・採用オブジェクト:人材情報が格納されており、関連データがそこに紐付いていれば、入社する可能性を予測できるかもしれません
データセットを検討する
それではデータセットを作成していきましょう。
必要データの中には以下の3つが含まれている必要があります。
・すでに答えが出ている既存のデータ
・トレーニングデータ
・答え合わせ用のデータ
・予測したいデータ
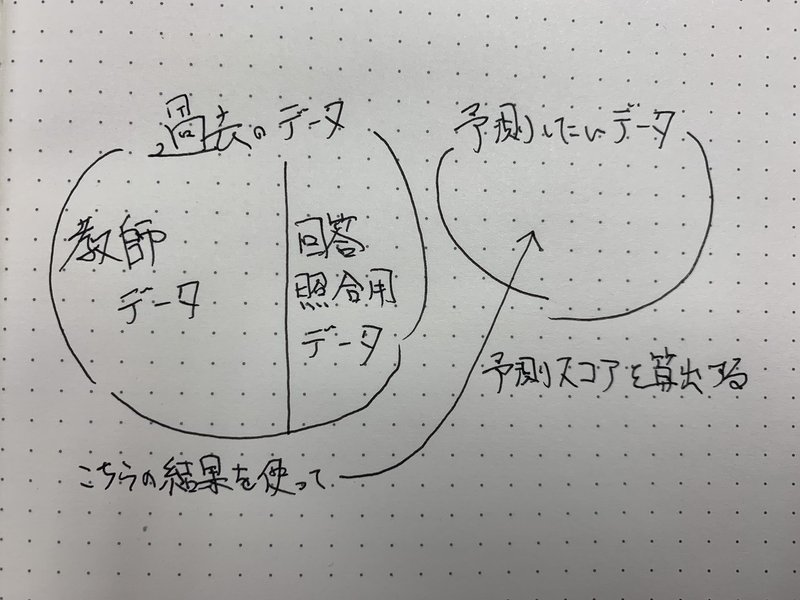
すでに答えが出ている既存のデータというのは、端的に言えば過去のデータです。
例えば、先日の参議院選挙の投票を例に上げると、投票に行った(True/False)が分かるデータのことをイメージしてください。
これを機械学習のトレーニングに使うのですが、全て使ってしまうと、結果の正しさがわからなくなってしまいます。
ランダムピックアップで答え合わせ用のデータを抜き出しましょう。答え合わせ用のデータには、チェックボックス項目で答え合わせフラグというカスタム項目を作ってTrueにしておけば予測ビルダーで使えます。
トレーニングには、最低でもTrue/Falseが各100ずつ必要です。教師データは多いほどよいとTrailheadに書いてありました。
ここまで準備が出来たら、カスタムオブジェクトにデータを投入して、予測モデルの作成をやっていきます。
現実的にはすでにあるデータを活用する事が多いと思いますので、データの投入は必要無いかもしれませんが、その場合は答え合わせ用のデータのフラグを立てる作業のみが発生すると思います。
更に予測分析データの最適化を行う場合は、こちらのページに公式コンテンツがあるので参照してみてください。
予測ビルダーでモデルを作成してみる
ここから試行錯誤の旅が始まります。
予測ビルダー画面から「新しい予測」ボタンを押します。
予測名は日本語が使えますが、予測ビルダー画面の一覧の名前部分にはAPI参照名しか表示されず、スコアカードの設定タブを見ないと確認できないのであまり意味がありません。英数字でわかりやすい名前を付けましょう。(こちらについてはユーザビリティイシューとして伝えてありますので、近いうちに予測名が表示されるようになるかもしれません)
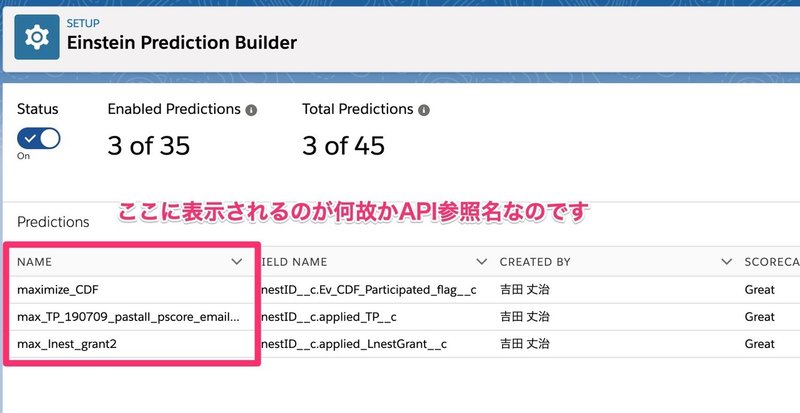
分かりやすい名前とは、データセットをどうやって作ったのかとか、サンプルはどのような条件のものを使ったのかが端的に分かるものが良いと思います。現状の予測ビルダーでは、どんな設定をしたのかを確認するには、作ったモデルをコピーして中身を確認するしあ方法が無いので、名前の工夫を推奨します。
予測するオブジェクトを選択する
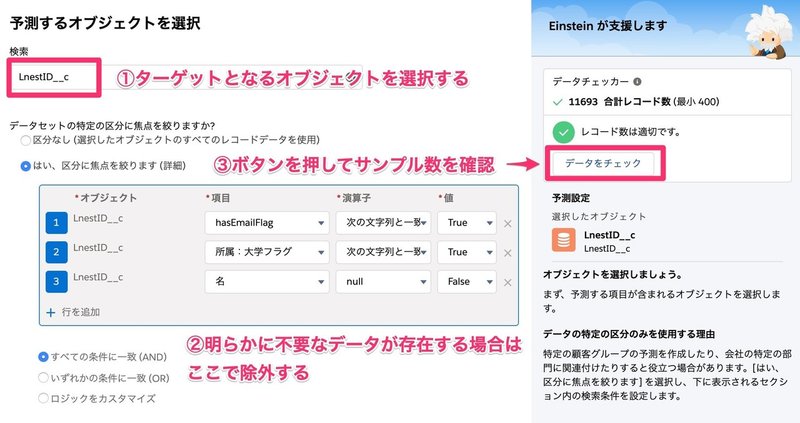
画像のような画面になります。
①の部分で、予測モデルを構築する対象となるオブジェクトを選択します。これはカスタムオブジェクトでも構いません。
②もし、データセットに、明らかに不要なデータが混ざっている場合は、ここでフィルタリングしましょう。今回はメールアドレスが存在しており、所属が大学であり、名が空欄ではないレコード11693を対象としてモデルを構築していきます。それ以外のレコードについては、データの不備が多く、分析に適さないだろうと判断して除外しました。
③のボタンは、これ以降の画面に全て出てくるのですが、レコード数が簡単に確認できるので非常に便利です。条件を変えたらこのボタンを押して逐一チェックします。
サンプルデータを定義します
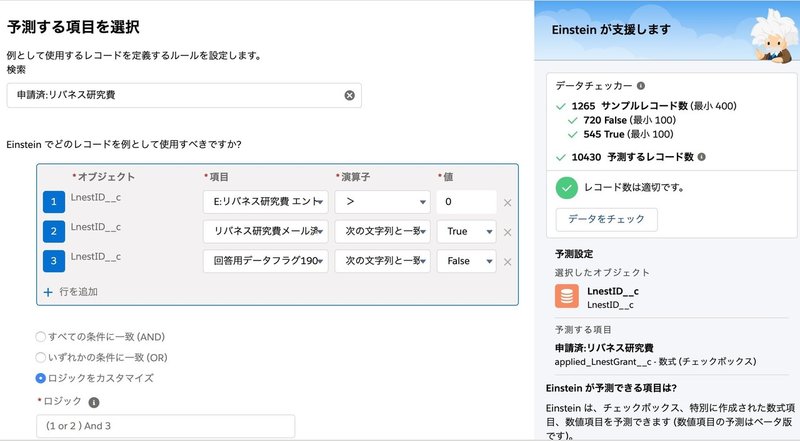
・リバネス研究費にすでに申請したことがある人
もしくは
・リバネス研究費に関する勧誘メールを送ったことがある人
のうち、回答用データフラグがFALSEになっている人を学習用データとして使います。
データをチェックボタンを押して、サンプルレオード数が足りていれば、レコード数は適切ですという表示になります。
回答用データフラグは、Excelでrand()関数を使ってソートし、目的の数のレコードにTRUEを立てるという処理になります。
リバネス研究費勧誘メールを送った人は、過去にPardotで利用したリストから抽出して、リバネスIDと照合をかけています。
モデル構築に使う項目を選択します
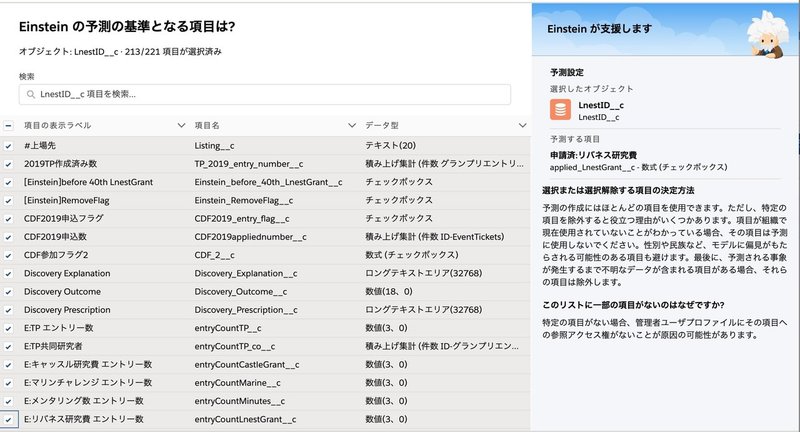
こんな画面になります。最初は全項目にチェックがついています。
この中から、明らかに予測モデルの邪魔になるデータは削除してください。
明らかに不要なデータとは、例えばリバネスIDにリバネス研究費申請済みフラグというものが存在したとすると(存在するのですが)、そのデータはイコール答えですので、削除します。他にも削除すべき項目が表示されていますが、そこは指示に従いましょう。
結果を保存するカスタム項目を作る
ここは簡単です。最初に設定したターゲットとなるオブジェクト上に、予測ビルダーがスコアを格納するためのカスタム項目を作成します。
名前は任意です。ここでは「リバネス研究費申請可能性」とでもしておきましょう。
あとは、最後にデータをチェックして予測を構築ボタンを押してしばらく待ちます。
予測モデルが完成した…と思ったらしてなかった
最初に出てくるハードルは、「予測品質は高すぎる可能性があります」というメッセージです。
以下はスコアカードの画像です。スコアカードについてのTrailheadはこちら。
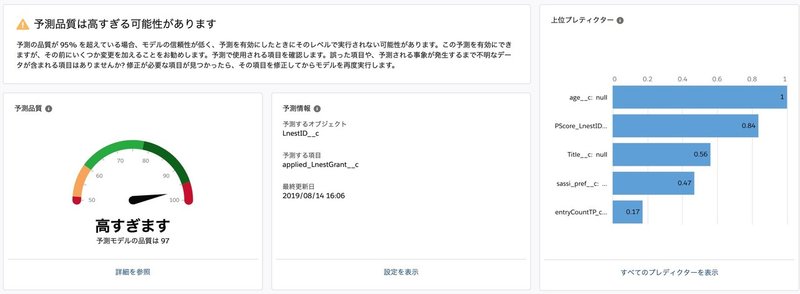
これが出た場合は、ある特定の項目が、モデルに影響を与えすぎている可能性があるということを示しています。
「誤った項目や、予測される事象が発生するまで不明なデータが含まれる項目はありませんか? 修正が必要な項目が見つかったら、その項目を修正してからモデルを再度実行します。」と書かれていることからも分かる通り、使用する項目についての精査が必要です。
スコアカードを表示し、詳細タブを開きましょう。
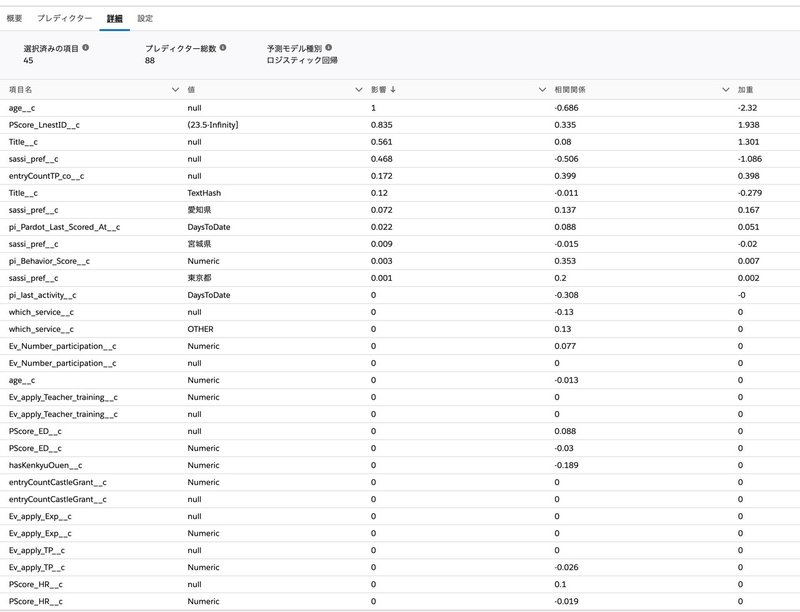
たくさんの項目があっても大丈夫です。落ち着いて、まずは影響度でソートしましょう。
影響度が高い項目の中で、データリーカーになりうる項目はありませんか。例えば、数式等で加工してあるけれど、リバネス研究費の申請済みフラグを参照している項目などがあれば、それが原因の可能性が高いです。
これらのデータのことを、後知恵バイアス(Data Leaker)と言います。Trailhead参照
今回除外した項目はこちらです。
リバネスIDオブジェクトには、過去のリバネス研究費申請数という数値項目が1以上の時にTRUEを返す項目があります。
リバネス研究費申請済みフラグという項目なのですが、この項目は、そのまま予測項目の答えとなりますので除外しました。
ついにデータモデルが出来た!
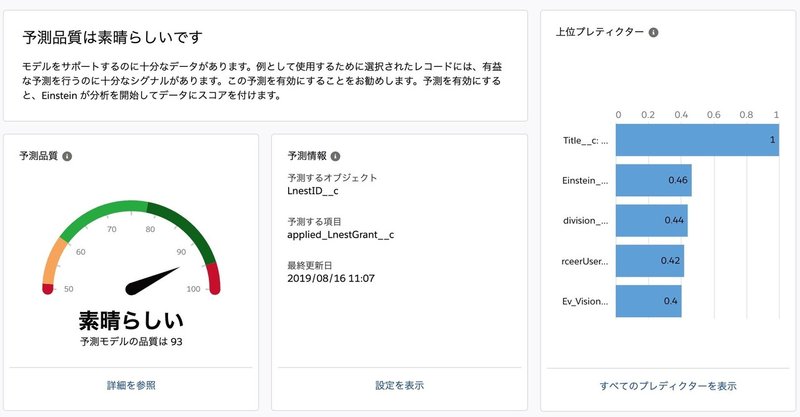
データセットの調整が終わると、スコアカードがこのような形に表示されます。
このデータモデルを有効化すると、予測する項目で指定したカスタム項目にスコアが入っていきます。
データの反映まで少し時間がかかるので、その間に別の作業をしましょう。
スコアのしきい値を決めるためにレポートを作る
スコアのしきい値って何?
予測ビルダーで予測モデルを作り、適用すると、先程設定したカスタム項目に0〜100までの数値でスコアが入力されます。
この数値は、リバネス研究費に申請する可能性を数値化したものです。
我々は、この点数がある得点以上の場合に、リバネス研究費を申請してくれるはずだというスコアを決めなくてはなりません。
では、それはどうやってやるのでしょう。実際に、決めていく方法は以下の通りです。
まず最初に、ターゲットのオブジェクトに一つ数式項目を加えてください。
ここでいうとリバネスIDオブジェクトに数式を追加します。
ラベルは予測評価項目_yyyymmdd
のような名前で良いと思います。何でも構いません。ここでは lvgrant_prediction_190815__c を予測評価項目としました。
数式の中身は、スコアのしきい値調整のための式になります。
entryCountLnestGrant__c が、過去のリバネス研究費の申請数
lvgrant_prediction_190815__c が今回作った予測スコアだとすると、以下のような式になります。
IF( AND( lvgrant_prediction_190815__c > 43 , entryCountLnestGrant__c >0 ) , 'True-Positive', /* スコアがしきい値以上 AND 申請済 正解 */
IF( AND( lvgrant_prediction_190815__c <= 43 , entryCountLnestGrant__c >0) , 'False-Positive', /* スコアがしきい値以下 AND 申請済 不正解*/
IF( AND( lvgrant_prediction_190815__c > 43 , entryCountLnestGrant__c = 0 ) , 'True-Negative', /* スコアがしきい値over AND 申請無 不正解*/
IF( AND( lvgrant_prediction_190815__c <= 43 , entryCountLnestGrant__c = 0 ) , 'False-Negative', /* スコアがしきい値以下 AND 申請無 正解 */
'N/A' /* その他 */
)
)
)
)43 はしきい値の初期値です。
先程使ったSAMPLEデータを見ると
TRUE:545(43%)
FALSE:720(56.9%)
という配分になりました。
今回はTRUEを特定する予測なので、43を初期値とすると良いとEdwardが教えてくれました。
ここから調整をかけていきましょう。
上述の数式で何をしているかというと、
予測値( lvgrant_prediction_190815__c ) が、任意のしきい値(これでいえば43)より上になっている場合をTrue
逆に、43以下の場合はFalseと定義します。
entryCountLnestGrant__c 過去のリバネス研究費の申請数が1以上の場合はPositive
逆に、これまで申請書を書いたことがない場合はNegativeという判定にします。
予測ビルダーがはじき出したスコアの中で、任意のしきい値以上の人は、申請をするという仮定をします。
こちらのTrailheadにデータについて書かれていますので参照してみてください。
Einsteinが申請をしてくれると判定しているのに、実際は申請してくれなかった場合を疑陽性といいます。
Einsteinが申請しないと判定したのに、実際はしてくれた場合を偽陰性といいます。
今回は、このスコアを元に申請してくれそうな人に対して、メールで申請を促すというアクションを行う予定です。
持っている連絡先全てに連絡入れれば良いと考えがちですが、色々なチャンスを使って作り上げてきた優良な関係性は、一つの迷惑メールで破綻してしまう可能性があるため、安易に実行するのはおすすめできません。
そこで、できるだけ申請可能性が高い人に絞ってメールを送りたいというニーズがあるとします。
そう考えると、スコアのしきい値を下げていくと、低いスコアでも申請してくれた人のデータは入りますが、それと同時に申請してくれない人のデータが増えていくことになります。これは先程言った、全体に送るのと変わりない行為といえます。
逆に、スコアのしきい値を上げていくことで、しきい値以下でも申請してくれた人のデータが失われていきますが、申請してくれない人をターゲットに含める可能性が薄まっていきます。
つまり、しきい値の設定は、予測値では申請してくれる(True)だが、実際はしてくれない(Negative)であるTrue-Negativeの人にはメールを送りたくないので、これが最小になるような数値を探します。
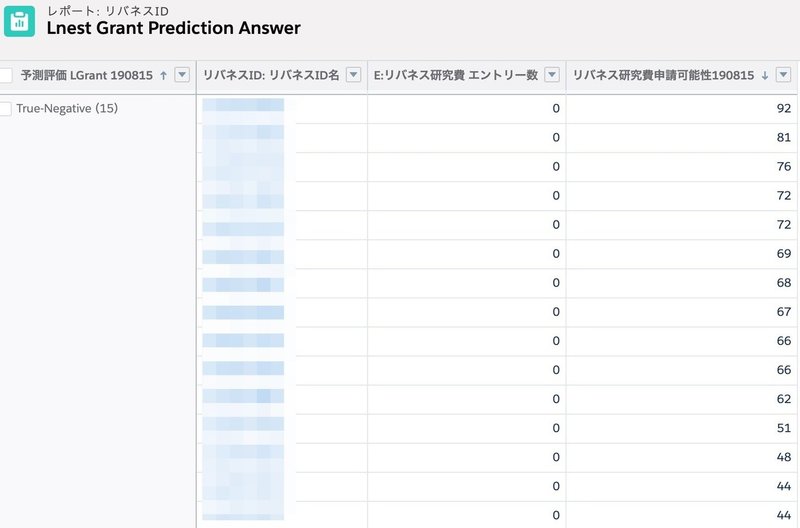
以下の画像は、True-Negativeになる人のスコアを抽出した画像です。
これをみると、しきい値を93にすると、True-Negativeが0になることが分かります。
ではそれで良いのでしょうか?というと、必ずしもそんなことはありません。
もし、93以上のスコアになる人数が、アプローチしたいと思っている人数規模より多ければ、しきい値93が正解でしょう。
しかし、現状のリバネスIDでスコア93以上をフィルタリングすると26人しか存在しません。これですと、アプローチ数が少なすぎます。
そのため、出来る限りしきい値を下げ且つTrue-Negativeが少なくなるようなしきい値を探します。
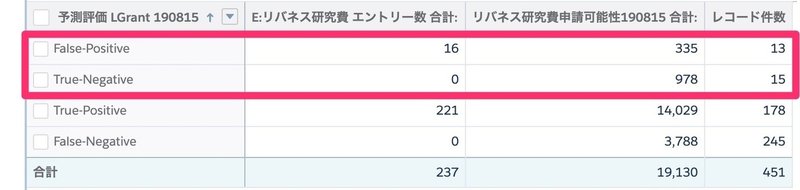
しきい値が43のときの結果がこちらです。
正答となるのが、True-PositiveとFalse-Negativeです。
誤答となるのが赤枠で囲った部分の、True-NegativeとFalse-Positiveです。
正答率は (178 + 245)/451 * 100 = 93.8 %
True-Negativeが未申請である *-Negative全体の中から発生する確率が
15 / (15+245) 100 = 5.8% です。
しきい値をどこに設定すべきかについては、色々な考え方があります。
以下では、しきい値を51にした結果、アプローチ件数が多すぎると判断して、しきい値を更に引き上げています。
*ページ下部のAppendixではEinstein Analyticsを用いて、回答用データのスコア分布を散布図にした画像を掲載しています。そちらを見るともう少し分かりやすいと思います。
申請してくれる可能性のある人にアプローチしてみましょう
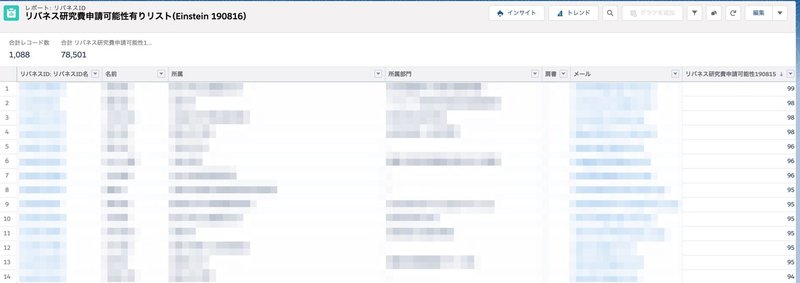
スコアの中から、安全を見て今回はしきい値を62以上に設定したレポートを作成してみました。
該当するレコード数が1088あるようです。まだ少し多い気がします。
Pardot Einsteinの行動スコアを併用する
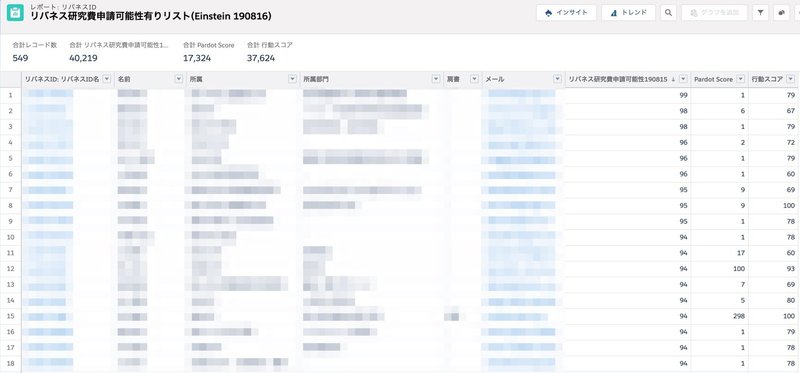
そこで、次に、Pardotから引っ張っているスコアも使うことにします。
かねてより積み上げてきたPardot Scoreが0以上の人に限定します。
もう一つ、最近導入したPardot Einsteinによる行動スコアも使ってみます。
行動スコアは過去1年の間の行動によって100点を上限にしてEinsteinがスコアリングしてくれる機能となっており、個人的にはこのスコアが、アクティブユーザを確認する指標として使えると思っています。
メールを送っても反応しない人に送るのは意味が無いと思いますので、行動スコアが10以上というフィルタも付けてみました。
すると、レコード数が549件になりました。
これでも多すぎるという場合は、スコアのしきい値をいじることで調整すればよいでしょう。
以下で私はPardotPardotでメールを送るというアクションを試みますが、リストを元に電話をするというパターンですと、もっとスコアの良い人に絞って電話をかけるというのが最適解になると思います。
Edwardがやるとしたら、ハイスコアのターゲットには電話をかけて、それ以外はメール配信で済ませるということも考えられると言ってました。
実際にアプローチをしてみましょう
それでは、こちらのレポートを出力し、メールアドレスのみを抜き出してPardotにインポートします。
リバネスIDのレコードは全てPardotに同期されているので、メールアドレスのリストさえあれば、アタックリストが完成します。
評価方法を検討します
今回はリバネス研究費と大雑把にまとめてしまったのですが、リバネス研究費自体には、申請対象となる研究分野が設定されています。
現状のデータセットでは、誰がどんなカテゴリーの研究分野に関心があるのかという情報が欠如していますので、リバネス研究費全体に興味はあるが、実際は申請が行われないという可能性があります。
そこで、実際に申請するというアクションに至らなくても評価出来るように、Pardotにスコアリングカテゴリを追加して、今回送ったメールの開封、クリック、登録解除でスコアが変化するようにします。
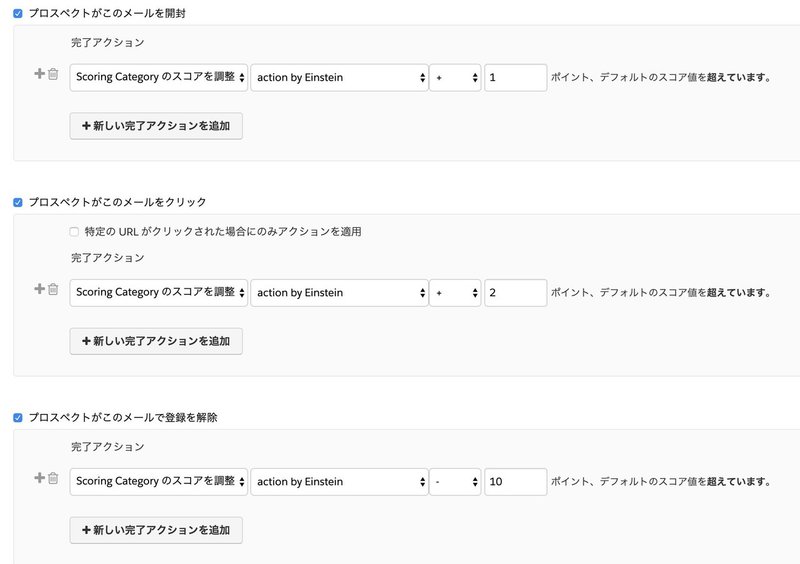
何もなければ0点
アクションがあれば+加点
送らなければ良かった人は減点
これに、リバネス研究費の申請締切後に、エントリーがあったかどうかのデータを加味すれば評価ができそうです。
準備完了!メールを送ってみましょう
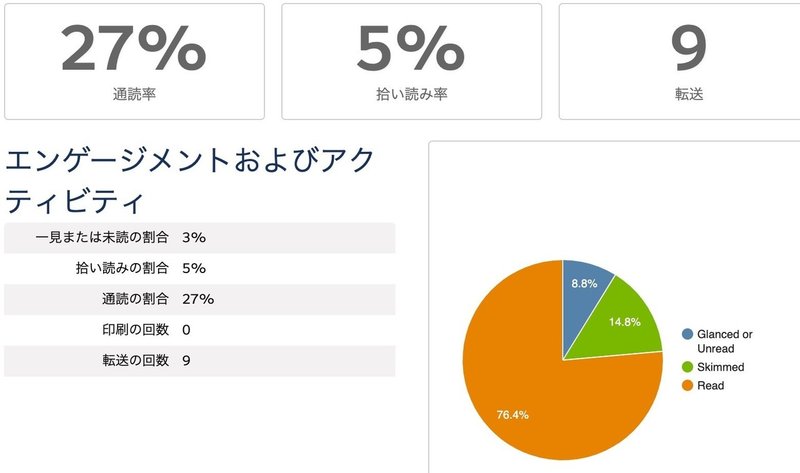
送信から数日経ったので結果を見てみましょう。
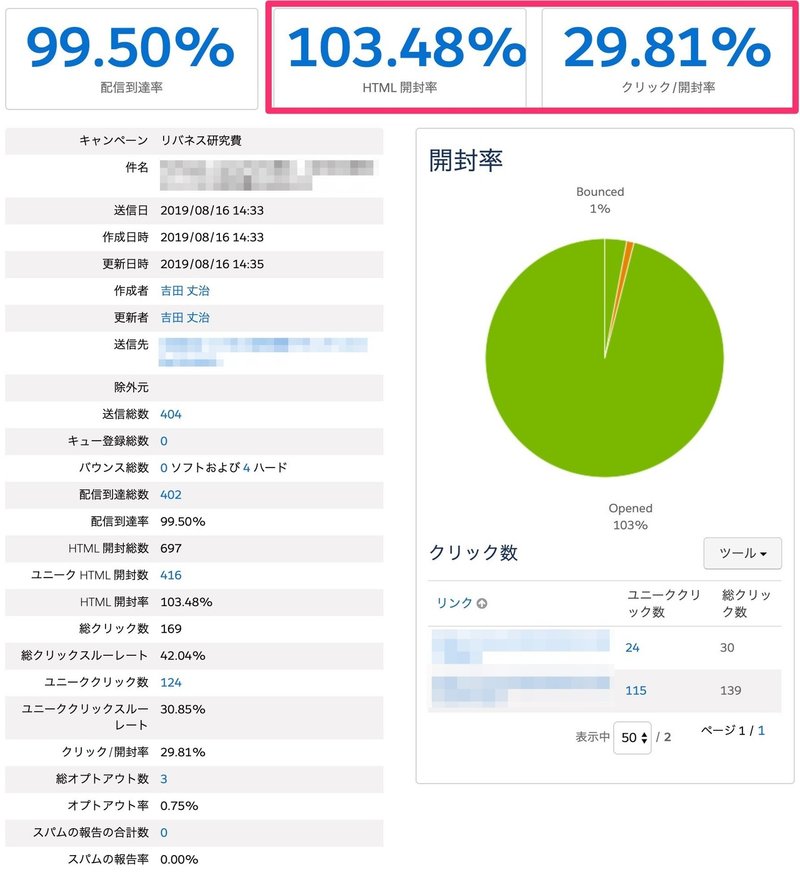
なんと、開封率が100%を超えました(転送してくれた方がいた影響)。通常、リバネス研究費に関するメールの開封率は40%前後なので、今回の開封率は飛び抜けていると言えます。
クリック率・通読率も30%程度。驚異的なパフォーマンスでした。
直近2回の同様の案内の配信結果は、クリック率が13%程度。通読率が21%程度でした。
本当にびっくりしたのですが、いまだかつてマーケティング用のメールでこんなに高い開封率になったことはありません。
今の所、結果のサンプル数が1なのでその要因がEinsteinで予測した結果というのは時期尚早ではあるのですが、メール施策の開封率向上という意味では、大成功だったと言えるでしょう。行動スコアの下限を下げて、もう少し欲張っても良かったかもしれません。
Einstein予測ビルダーによるリバネス研究費への関心度のスコアと、Pardot Einsteinによる行動スコアによるフィルタリングをかけ合わせる事で、強力な武器になりうるという仮説が一歩現実味を帯びてきました。
結果の評価をしてみましょう
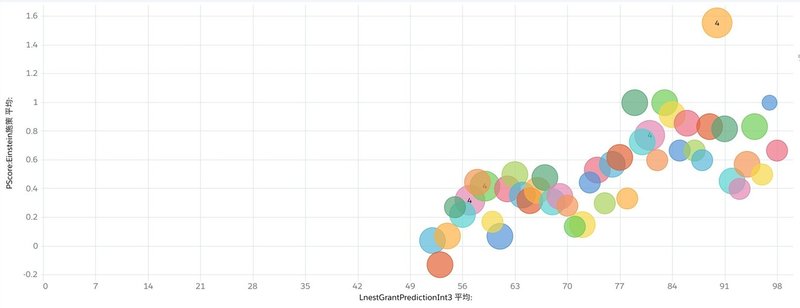
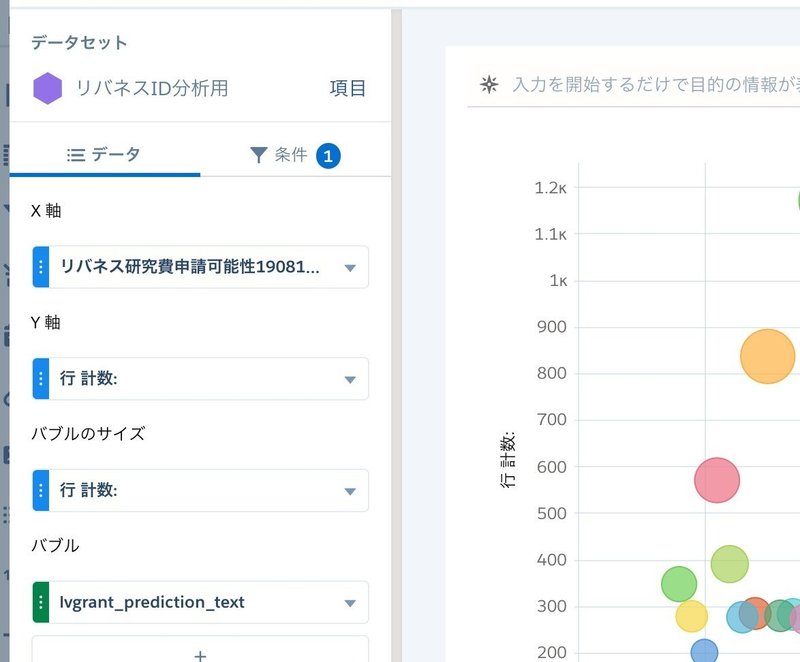
X軸がスコアで、Y軸が先程設定したスコアリングカテゴリで計測したスコアの平均点を取りました。バブルの大きさは、レコード件数です。
相関係数は0.29でした。予測スコアと獲得したアクションによる得点には弱い正の相関がありそうです。
最終的にリバネス研究費への申請はあったのか?
申請締切日を過ぎたので結果を見てみましょう。
結果的には4件の申請がありました🎉
メールが届いた人の1%が最後まで完了してくれる結果となりました。
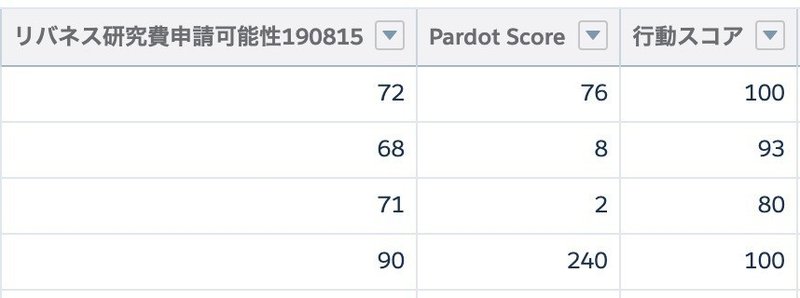
こちらが申請してくれた4名のスコアでした。行動スコア強い。Pardot Scoreは積み上げなので、真ん中の二人はほぼ新規ユーザーということになりそうです。
登録というゴールにアプローチするために…
ここまでのアクションで、リバネス研究費に関心のある人に的確なアプローチが出来たことが分かります。
しかし本来であればメールを開き、サイトを確認した人の中から、実際にリバネス研究費に申請してくれた人を最大化する必要があるので、ここで終わると片手落ちです。
そのためにはまだハードルがあります。今の所、ターゲットとなる人物がどんな分野の研究費に関心があるのかという情報が設定できていません。そのため、メールを開いたとしても、当該の研究費がその人の活動にマッチしているかどうかは分からないのです。
まず最初にやるべきこととしては、過去の活動(研究費等の申請カテゴリ、イベントのカテゴリなど)に共通するカテゴリ設定を行うという事ができるでしょう。それによって関心領域をより明確にすることで、申請というアクションに一歩近づくと考えています。
もう一つのアクション:データ設計の変更
これまでのデータは、申請書を作ってくれた人のデータ(下書き及び申請済み)しか取れていませんでした。
理想的には、メールを送信した段階でリバネス研究費のレコードを作成し、Statusをメール送信済みに設定する。
メール送信後、申請フォームを開いてくれたら、Statusをアクセス済みに変更する。
申請フォームで1文字でも書いてくれたらStatusを下書きに変更して、以降は同じプロセス。
という形にするのが理想です。これが出来ると、最初のアクションから、結果までがログとして残ることになり、Einsteinフレンドリーだと言えると思います。
補足:Einstein 予測ビルダーのスコアについて
予測ビルダーで作られるスコアは1時間に一度再評価されます。
今回使っているデータは、日々新しい情報が入ってくる設計となっているため、スコアは徐々に変わっていきます。
そのため、メール送信などの実際のアクションを行う直前にしきい値となるスコアを見直すほうが良いと言えるでしょう。
リバネスの場合は、1時間に1度Einstein Analyticsにデータ同期をしているので、以下のAppendixに示した散布図を見れば、視覚的に今現在のスコアについて理解出来るようになっています。
最後に
実データでチャレンジするにあたり、Salesforce@UKのEdwardさんには大変にお世話になりました。そしてコミュニケーション部分では弊社秋永にも多大なヘルプをしてもらいました。その分、彼女にはAIのなんたるかがインストールされたと思います。
Einstein(AI)を使うにあたって、これまで培ってきたデータの使い方とは全くアプローチが違いました。
AIの勉強はしてきたものの、実際に使うにあたって何をすればよいのか、何をやる必要があるのかについてはよくわかっていなかった状態でした。
特に、AIというある種のブラックボックスの結果をどうやって検証するのかについては、一人では分からないままだったような気がします。
今回はスペシャリストであるEdwardさんとディスカッションを重ねた事で、やるべきことが明確になりました。Trailheadも良いコンテンツが揃っていますが、細かい疑問には答えてくれませんので、スペシャリストのサポートが必要になると思います。
こちらの記事は、私自身がわからなかったことをそのまま共有したいと思って書きました。同じように悩んでいるであろう人の助けになれば幸いです。
是非、みなさんも実務でチャレンジしてみてください。多くの知見が集まることで、よりEinsteinの適用範囲が広がっていくことでしょう。
AIを使うというと大げさなことのように思われがちですが、当たり前のように使いこなし、結果を出せる時代がもう来ていると思います。
挑戦し、共有しましょう。
質問あればコメント欄へどうぞ。分かる範囲でお答えいたします。
分からないことは…一緒に解決しませんか?
続編書きました
続:Salesforce謹製AIのEinstein(予測ビルダー)の使い方をプロダクトマネージャーに直接教えてもらった一部始終の記録とその結果
Appendix
回答用データのスコア散布図
以下はEinstein Analyticsを使ったグラフ化です。もしライセンスをお持ちの場合はお試しください。
X軸がスコアの値。Y軸が該当スコアにスコアリングされたレコード数を取っています。
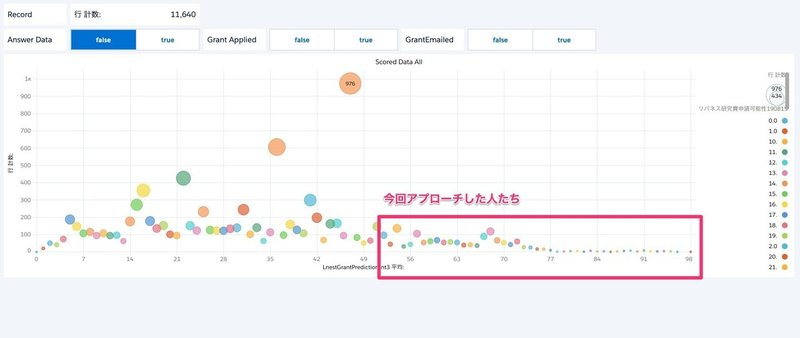
回答用データのスコア分布 全データ
申請済みのレコードのスコアが高くなり、未申請のレコードのスコアが低く判定されるはずです。
これを見ると、低スコアと高スコアの2つのピークがあることが分かります。
中間地点はレコード数が少ない領域があります。
この領域にリバネス研究費申請可能性のTRUE/FALSEのしきい値を引くことになります。
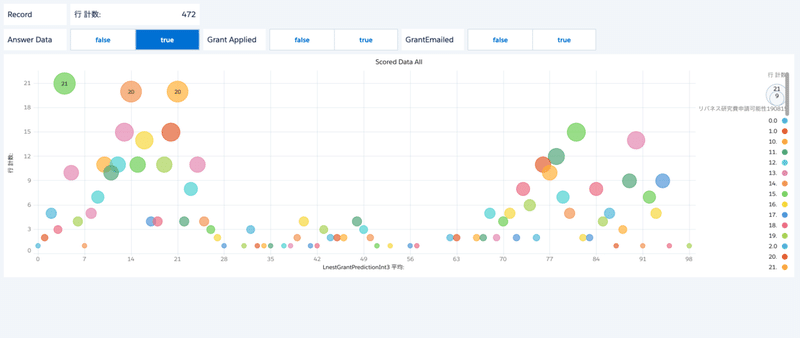
回答用データのスコア分布 リバネス研究費 申請済みのみ
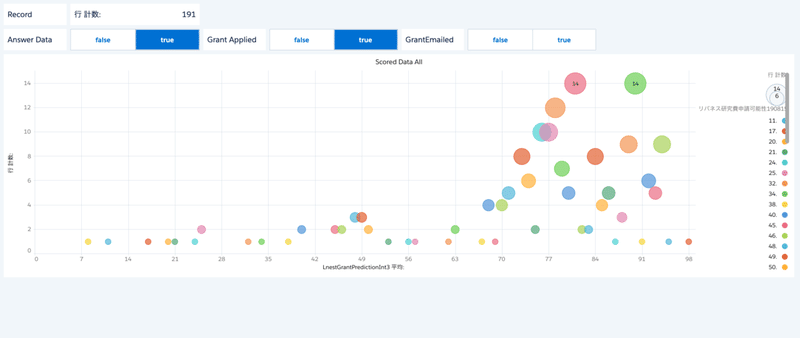
回答用データのスコア分布 リバネス研究費 未申請のみ
本文にも書いたとおり、True-Negativeの判定を重視することにしました。
予測結果が申請してくれるといっているのに、申請してくれない人には、メールの案内が無用だからです。
これでみると、45以上の領域のレコードが少なくなっていることが分かります。
本文では51をしきい値に設定しました。
その後に、あまりにメールの開封率が高かったのでもう少しデータを増やせばよかったと書いたのですが、増やすのであれば、しきい値を45。もしくは更にいうと29くらいまで攻めても良かったかもしれません。
ただ、その場合は、正答率が低下すると思いますので、今回のようなメール開封率にはならなかったでしょう。
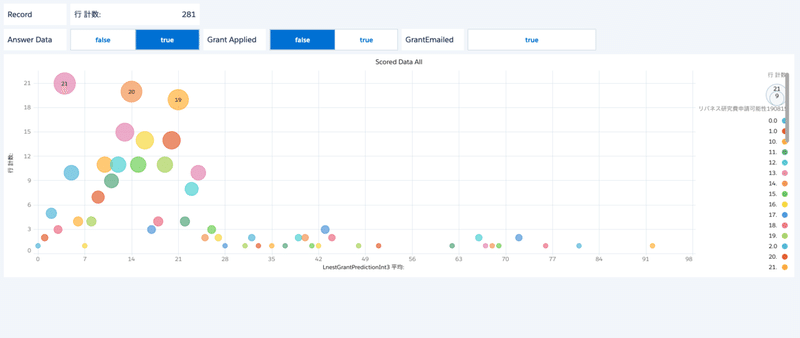
全てのスコアリング済みデータ
最後に、全てのスコアリングデータの散布図です。
今回は51をしきい値としたので52以上の人たちに向けてアプローチをしてみました。
これを見ると分かるのですが、976件のレコードがスコア47の所に現れています。
これを入れてしまうと、メール開封率が下がりそうですね。
Einstein Analyticsにおける散布図の書き方
スコアをそのままSalesforceからEinstein Analyticsに取り込むと、数値データとして取り込まれます。
散布図のドット一つ一つはスコアを使いたいのですが、数値データは使うことが出来ません。そのため、データ取得時に数値ではなくテキストとして取り込んでいます。バブルのName項目として使うからTEXTじゃないとダメなのだろうと思うのですが、ちょっと不便に感じますね。
X軸は、computeExpressionノードを使って数値データをテキスト化しています。
computeExpressionノードはこちら
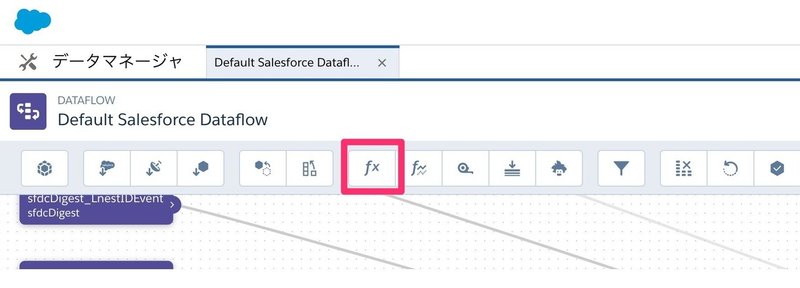
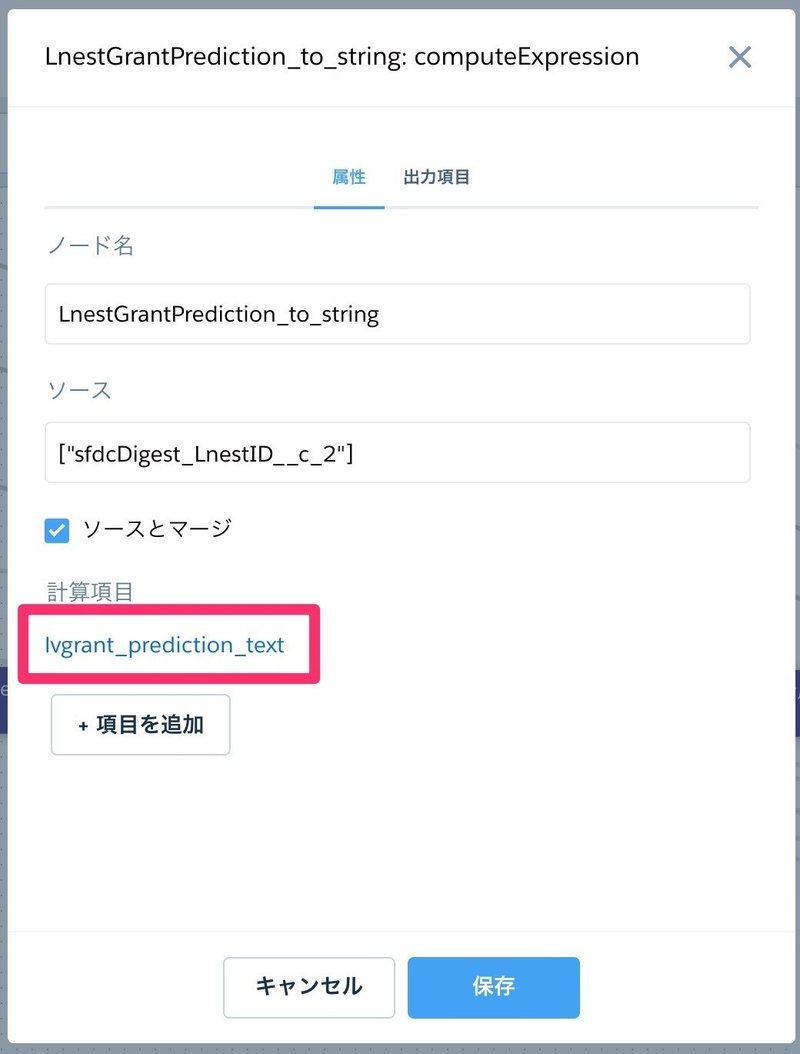
computeExpressionを使うと、ソースノードにある項目に計算を施すことが出来ます。ソースノードを指定(ここではsfdcDigest_LnestID__c_2となっていますが、各環境によって変更してください。弊社ではリバネスIDオブジェクトが指定されています)
項目を追加ボタンを押すと、具体的な数式を書く画面になります。
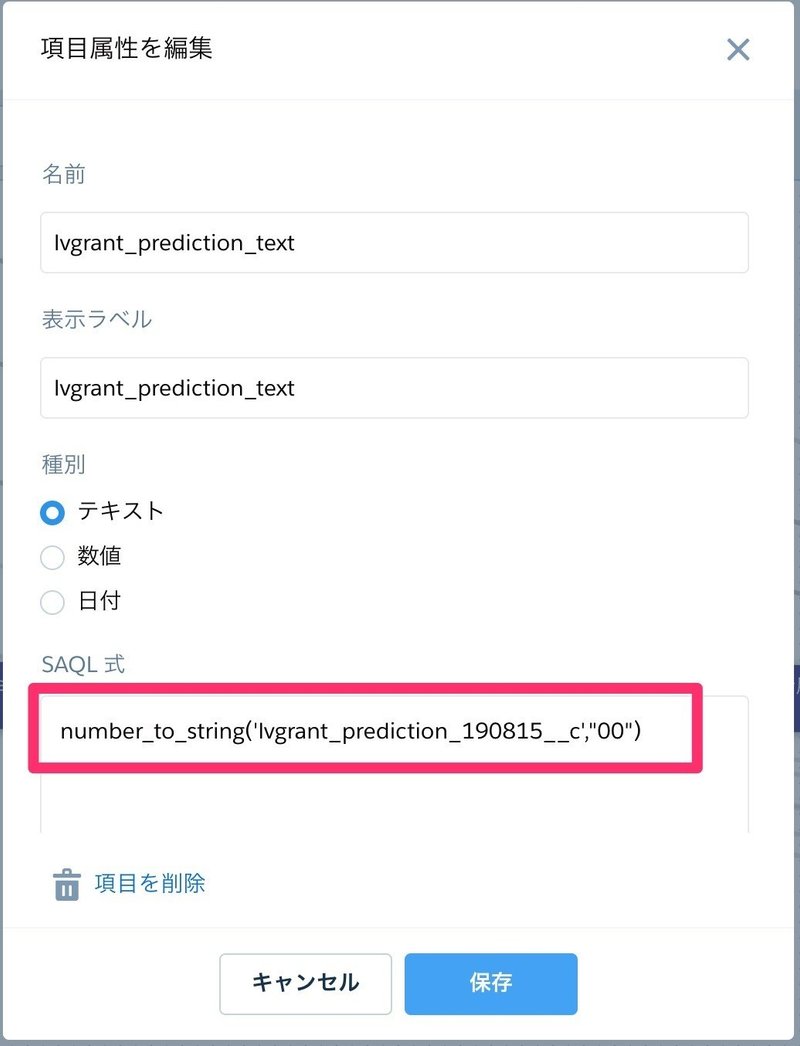
名前と表示ラベルは任意です。数式は以下の通り。
number_to_string('lvgrant_prediction_190815__c',"00")
二桁の数字で出力するようにしてあります。1だったら01 という形式で変換されます。散布図は以下の設定で出力できます。
Einstein Discoveryのストーリーを使って同様のスコアを出すには
今回の予測ビルダーの解析はロジスティック回帰が使われていることがスコアカードから分かっています。
Einstein Discoveryのストーリーはロジスティック回帰で形成されるので、同様のスコアが上がってくるはずです。
ストーリー作成用のデータセットは、予測ビルダーで使った、教師データに合わせています。
条件を改めて書くと
1:メールアドレスが存在する
2:所属が大学である
3:名が空ではない
4:リバネス研究費に申請したことがある
5:リバネス研究費勧誘メールを送信済み
6:回答用データフラグがTRUE
ロジックは 1 AND 2 AND 3 AND ( 4 OR 5 ) AND 6
これをリバネスID上で数式項目のチェックボックス(Boolean)で作り、Einstein Analyticsに同期します。
もともと使っていたリバネスIDのデータセットからレシピを作り、上記数式項目がTRUEのものだけのデータセットを作ります。
このデータセットを使ってストーリーを作成しましょう。こんな結果が出ました。
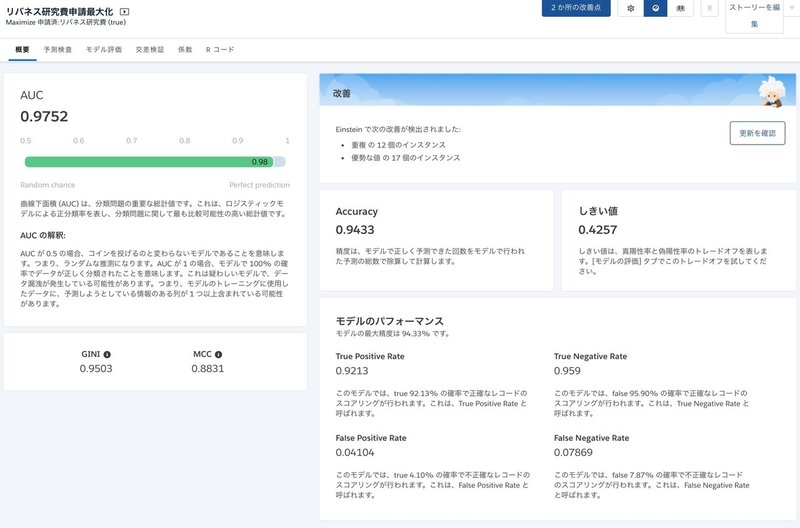
モデル評価のタブを開くと、混同行列をいじって中身を理解することが出来ます。
Accuracy(正確性)のボタンを押すと、このような図になります。
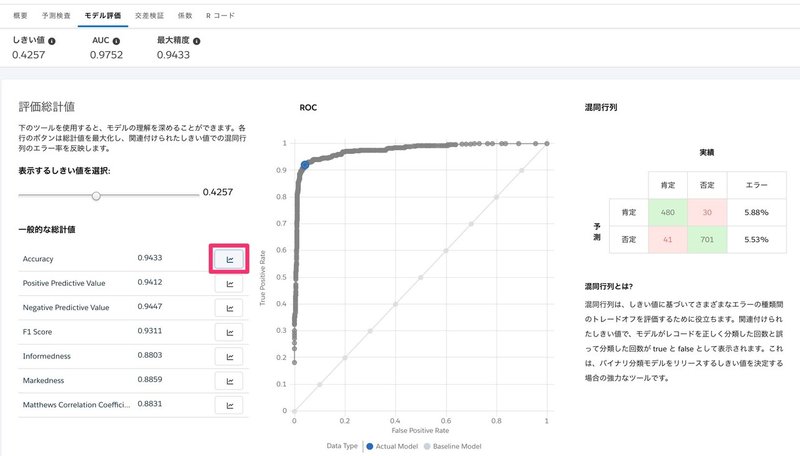
しきい値を0.4257にしたときが一番正確でした。最初のしきい値を43としたのですが、おおよそあってますね。
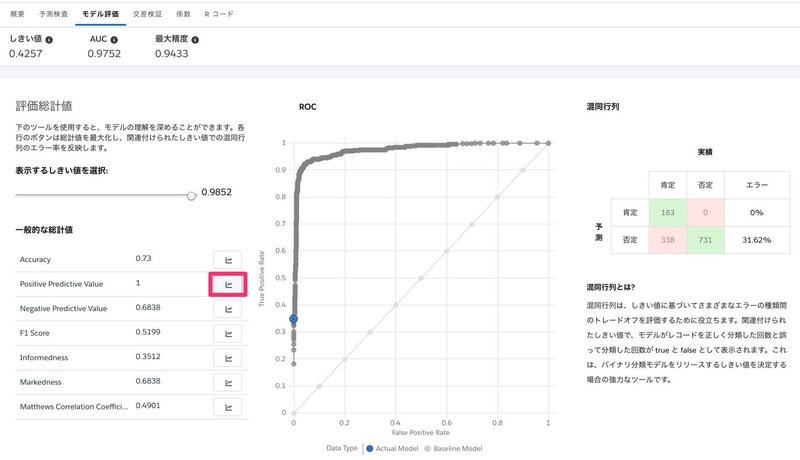
次に、Positive Predictive Valueのボタンを押してみます。しきい値が0.9852と極めて高くなりました。
右側の行列を見ると分かる通り、予測が肯定になっている場合に、実績値が否定になる可能性は0です。
予測が申請可能性を示唆した場合、100%申請してくれるというしきい値の設定です。一件、ここが良さそうに見えますがどうでしょうか。
今回でいうと、予測が否定の場合はメールを送りませんから、申請がなされないということになります。
申請者募集のためにメールを申請してくれそうな人に送りたいけれど、あまりしきい値を上げすぎると、アプローチリストが減ってしまいます。
エラーをどの程度許容してしきい値を設定するのかは、その時次第だと思いますので、各々の考え方で決める必要があります。
その他にも、F1 Score, Informedness, Markedness, Matthews Correlation Coefficient の4種類で2値分類モデルの精度を評価出来ます。
noteにはこれまでの経験を綴っていこうかと思います。サポートによって思い出すモチベーションが上がるかもしれない。いや、上がるはずです。