Stable Diffusionの生成設定まとめ


前回学習設定の記事を書きましたが、しょうもないネタ画像を作るのが面白かったので、生成についても書いていきます。WebUIにある機能を中心に書きますが、実装をみないでフィーリングで理解してる部分もあります。
生成過程について
Stable-Diffusionは拡散モデルというもので、完全なノイズからノイズを除去していって画像を生成するとかいいますね。ざっくりと以下のような図で表されます。

一般的な設定
生成法によらない設定から紹介していきます。
解像度

解像度自体は説明しなくても分かると思いますが、WebUIでは8の倍数の画像しか生成できません。これはVAEが潜在変数を8倍するからです。なんとなく8の倍数以外も生成できるようにするスクリプトを作ってみましたが、どうしても8の倍数以外を生成したいなら、できた画像をちょっと拡大縮小すればいいだけな気がします。
Batch count
画像生成を何回繰り返すかです。こんな呼び方するのWebUI以外で見たことないです。
Batch size
学習編にもありましたが、生成の場合は同時並列で何枚の画像を生成するかの設定です。GPUは並列計算が得意なので、大きくすればするほど一枚当たりの生成速度が上がりますが、VRAM使用量も上がります。最終的な生成枚数はBatch count×Batch sizeになります。
最近バッチサイズのことをバッチ数と呼ぶ人のことを見ましたが、全然別の意味になります。おっぱいの大きさのことをおっぱいの数といっているようなものです。
sampling step
上の図であったようなノイズ除去の繰り返しを何回やるかです。学習時は1000回に設定されているのですが、スキップしまくって20~50くらいでまともな画像ができるようになります。
CFG scale

CFGとは、Classifier Free Guidanceの略です。guidance scaleとも呼ばれますね。プロンプトをどのくらい忠実に再現するかという設定で、
プロンプトなしの予測×(1 - CFG scale) + プロンプトありの予測×CFG scale
という式を実際の予測結果にします。AUTOMATIC1111氏は、プロンプト無しの部分に望ましくないプロンプトを入れたらいいんじゃね?と思いついてネガティブプロンプトというものを実装しました。そのため実際には
ネガティブプロンプトの予測×(1 - CFG scale) + プロンプトの予測×CFG scale
という形になっています。ネガティブプロンプトはもはや必須級なので、これを考えたのがAUTOMATIC1111氏の最大の貢献だと思いますがあまり注目されてないですね。
CFGの式によって、学習時の計算式と生成時の計算式は異なるものになります。そのため過学習が起きた状態だと、大きなCFG scaleは画像を崩壊させる要因になります。そういった場合はCFG scaleを低くするとうまくいく場合があります。
サンプラー
学習時は1000ステップに設定していると言いましたが、生成時はスキップしまくって20~50ステップくらいで生成します。そのときどうやってスキップするかを決めるアルゴリズムです。
サンプラーによっては2倍の時間がかかるけど精度がいいとかそういうものがあります。わたしはむつかしいこと考えたくないのでおいらーしかつかいませんけど。
DDPM:原初のサンプラーですが、原初過ぎて使われません。
DDIM:DDPMの改良版です。これもあまり使われない。
PLMS(PNDM):DDIMをODE化して、序盤はルンゲクッタ法、履歴がたまったら線形多段法を使います。あんまりよく分かってない。
Euler:逆拡散過程をODE化したものに一般的なODEソルバーであるEuler法を使います。だいたいのUIがデフォルトをこれにしてる気がする。
Heun:Euler法の発展で、二階近似です。モデルの計算を二回を行うので計算時間が2倍になります。その代わり精度もあがる・・っぽい。
DPM-Solver:Euler等と違い拡散モデル専用に開発されたソルバーです。1階はDDIMと同じなので使われません。
DPM-Solver++:DPM-Solverの改良版でつ。こちらは二階バージョンにも二つに分けられて、Single step(S)とMulti steps(M)があります。Sの方は中点法を使うので計算時間が倍になります。MはAdams-Bashforth法というものが使われていて、計算時間そのままで二階近似できます。
UniPC:わかんね。
img2img
完全なノイズからスタートするのではなく、既存の画像に中途半端なノイズを与え、途中からノイズ除去ループを開始することで、画像を修正したりできます。
inpaint
img2imgとほとんどおなじですが、img2imgは画像全体を変更するのにたいして、inpaintは指定した部分以外は元の画像を保ったままにします。
Hires fix

学習データにない解像度の画像を生成すると、画像の構図が崩壊するので、一度モデルが対応できる解像度で生成してから、アップスケールした後img2imgを行います。潜在変数のまま単純な線形補間によるアップスケールをする方法や、VAEで元の画像に戻した後、なんらかのアップスケーラーを適用して再度VAEで元に戻すという方法の2種類あります。後者は精度の高いアップスケーラーを使える代わりにVAEのエンコードデコードを行うため元の画像と離れやすいと思います。
(追記)潜在空間専用のアップスケーラーを使うなんていう面白い方法も開発されました。
プロンプト関連の設定
私はプロンプト・エンジニアリングが嫌いなので、細かい設定は皆さんの方が詳しそうですが、実装面について話していきます。

Prompt weighting
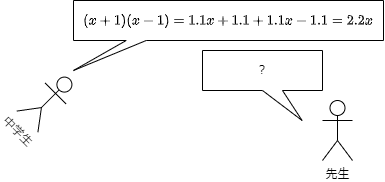
プロンプトに重みをつけます。実際に重みがかけられるのはUNetに入る直前になります。WebUIでは"()"が1.1を掛ける、"[]"が1.1で割るという意味になっています。実はこれ、"("単体は後ろのプロンプト全部1.1倍にするという効果になっています。")"は後ろのプロンプトを1.1で割ります。"("の効果を")"で打ち消すことによって、"()"内のトークンのみ1.1倍されるという意味になります。"["は1.1で割る効果なので、よくみると")"と同じ意味になっています。つまり"()"は"]["と、"[]"は")("と同じ意味になります。まあこの辺は以下の記事で知った話ですが。ただし最終的に正規化されます。たとえば一つのトークンの重みを増やすと他のトークンが全体的にダウンスケールされます。
Prompt editting
[chinchin:manman:0.5]みたいなやつですね。使ったことないですけど、ノイズ除去ループの途中でプロンプトを切り替える手法ですね。
BREAK構文、AND構文
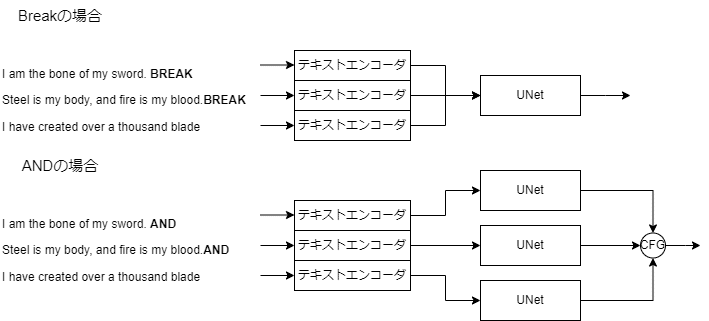
トークンは自動で75個ずつ分割されて、テキストエンコーダに送られますが、ここで分けて欲しくない!というときに分ける部分をBREAKによって指定できます。また後半のトークンほど影響度が小さくなってしまうので、それを防ぐためにBREAKを使うということもあるみたいですね。
BREAK構文はUNetに入力する前に結合しますが、AND構文では分割したプロンプトそれぞれ別々にUNetに挿入します。つまり全く別のプロンプトで生成した画像を組み合わせることになります。そのため生成時間が増えます。ANDの前に:1.5みたいな感じで入れることで重み付けもできます。具体的な計算式は、$${{\hat{\epsilon}} = \epsilon (x) + \mathrm{cfg}_{scale}\sum w_i(\epsilon (x|c_i)-\epsilon (x))}$$です。これをみたら勘のいい人でも気づくわけないと思いますが、私が大昔やったネガティブプロンプトのスケーリングはこれを使えばできます。
LoRA関連
私はびるどいんのLoRAを使ったことないのでそれについてはわかりません。
Weight
LoRAの出力にWeightがかけられます。強めたり弱めたりするのはわかるんですが、Flat LoRAのようにマイナスにするといいみたいなことも起きてびっくりですね。
LoRAの領域適用
LoRAの適用領域を制御する方法は三つに分かれます。
各モジュール単位でLoRAの出力にマスクをかける
Latent coupleとの組み合わせ
Attention coupleとの組み合わせ
1.は実装が一番単純で、生成速度にもほとんど影響しませんが、プロンプトに関連するモジュールに関しては領域を制御できません。Kohyaさんのadditional_networkで実装されています。2.は完全に制御できますが、生成速度が遅くなります。hako-mikanさんのregional_prompterで実装されています。3.は実装がとんでもなく複雑ですが、生成速度を変えずに制御できます。ただしUNet内で画像が縮小されてしまうため、一部のモジュールは大まかな領域しか指定できません。Kohyaさんのadditional_networkのattention_coupleブランチで実装されています。
LoRAの事前マージ

LoRAを適用するときは二種類の方法があります。アダプターとして使う方法とモデルにマージさせて使う方法です。後者の方が生成速度が速くなります。特に複数のLoRAを同時適用する場合、生成時間に差が結構生まれます。Additional-Networksを使う場合、Setting→Additonal-Networks→Merge weights in advanceで設定できます。まあカレーを混ぜずに食べるか混ぜて食べるかみたいなもんです。
ControlNet関連
Control Weight
特になし
start、end
ノイズ除去ループ中の一部のステップのみに適用する方法ですね。
Control Mode
Prompt「私とControlNet、どっちが大事なの!!!」
BALANCED:普通にControlNetを適用します
My prompt is more important:ControlNetの出力を、UNetの出力側程弱めるようにします。具体的にはMID($${i=0}$$)、OUT0~11($${i=1,\cdots , 12}$$)に対して、$${0.825^i}$$がかけられます。ControlNetが弱まるのでプロンプトに忠実になりやすいというわけですね。
ControlNet is more important:ネガティブプロンプト側にControlNetを適用しないようにします(以前のguess modeと同じ)。ネガティブ側に適用されなくなるので、ControlNetが強くなります。という触れ込みなんですが生成してみるとなんだかそう思えないのですがどうなんでしょう。
生成時間節約法
WebUIのSetting→Optimizationsにある謎項目の解説です。
xformers、sdp
学習編と同じですね。バッチサイズを上げるほど効果があると思います。
negative guidance minimum sigma


ノイズが少ない状態で、ネガティブプロンプト側の計算をスキップすることで、生成結果をほとんど変えずに生成時間を早める方法です。特にHires fixとかをやるときに有効ですね。WebUIの設定にあるOptimizationsから設定できます。なぜかsigmaとかいう数字を基準にしています。上のグラフがsigmaの推移で、設定した数値を下回るステップではネガティブプロンプトは計算されません。。1.1とかが無難な設定のようです。大きくするほど生成時間が減りますが生成画像の質が落ちます。
Token Merging
??「今から二人組つくってー」
俺「あ・・・TqT」
学習編でもやりましたが、画像中の似たピクセルをマージしちゃって計算量を減らすやつです。トークンというとプロンプトのトークンを思い浮かべると思いますが、Transformerという層では画像のピクセルをトークンとして扱うのでそう呼ばれます。上と同様Optimizationsから設定できます。ratioは0.5が一番良いらしいです。