
複数キャラクターを分けて生成するLatent coupleの改良版!(Attention Couple)

先月複数キャラクターを特徴が混じらないように生成する技術が公開されました。今回はこれの改良(たぶん)手法を提案します。
Colab
Attention coupleとLatent coupleの両方を試せるようになってます。比較してみてください。この実装では計算時間が半分くらいになることが確認できます。(実装が間違っていたらごめんね)
生成例

背景
先日Kohyaさんが自身のwebui拡張にLoRAの適用領域を指定する実装を追加しました。しかしこの方法はText Encoder(と書いてないけどたぶんCross Attentionのto_k, to_v)、ようするに出力が画像の形をしていないモジュールには適用されません。私はこれらのモジュールにも適用する方法を思いついたので、つぶやきました。そしたらKohyaさんが反応してくれて、latent coupleにも応用できるのではないかとのアイデアを頂きました。今回はそれをやります。
全体図
左右それぞれに別のキャラクターを生成する場合を考えます。
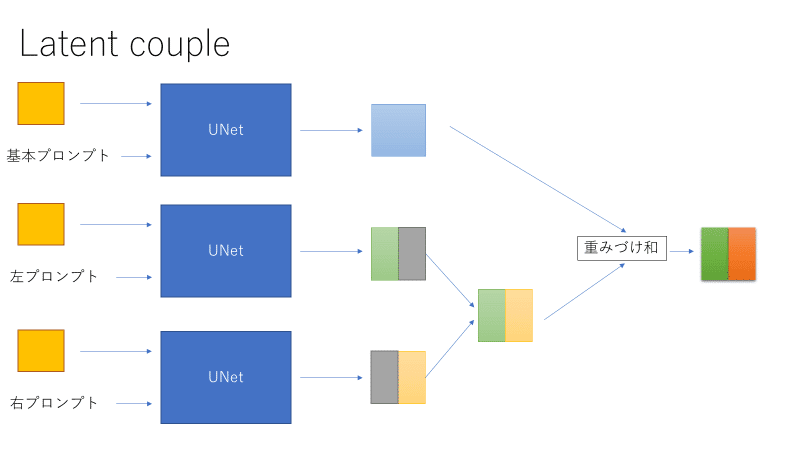
Latent coupleでは左右のプロンプトそれぞれに対しUNetの出力を計算し、左右に分けて画像をくっつけます。しかしそのままだと別々の画像をくっつけただけになってしまうので、左右両方の特徴を表す基本プロンプト(私の造語)を用意し、基本プロンプトによる生成画像と左右プロンプトによる生成画像の重みづけ和を出力とします。つまりUNetは3回分計算されます。(他にネガティブプロンプトの計算もありますが、今回は省略)
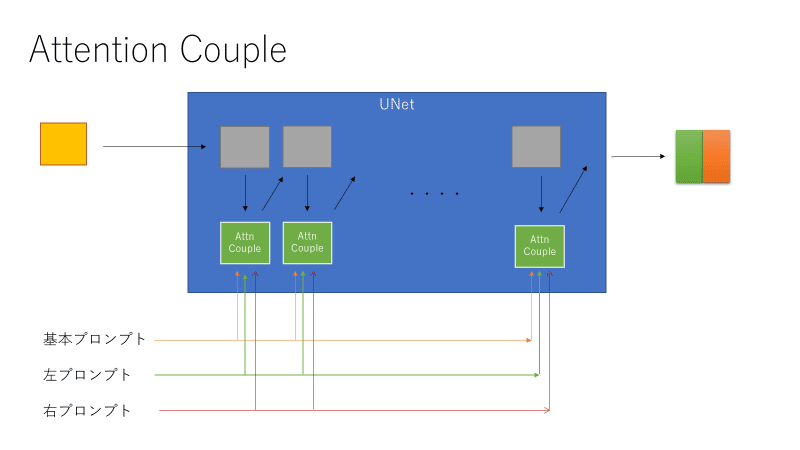
Attention coupleではプロンプトごとにUNetの計算を行うのではなく、プロンプトに関係があるモジュール単位で同様の計算を行います。これにより大幅な計算量削減が実現できます。さらにUNetの中でcouplingの計算が行われるため、より1枚の画像として一貫したものが生成される(と期待されます)。そのためもしかしたら基本プロンプトはいらないかもしれませんが、今回は基本プロンプト込みで実装しています(設定によって基本プロンプトのない状態も再現できます)。
※分かりやすく画像といってますが、実際は推定されたノイズです。
詳細
Cross attentionの$${k,v}$$にはプロンプトの情報のみが入力されており、画像としての意味を持っていません。しかし$${qk^Tv}$$まで計算すれば、これは画像の形になっています。そのためこの部分をプロンプトごとに計算し、領域に応じた操作をします。それ以外の計算(to_q, to_out, FFN, ResNetとか)はプロンプトが直接入力されないので、プロンプトごとに計算する必要はありません。今回は単純に、二つのプロンプトに対して$${k_1,\ v_1,\ k_2,\ v_2}$$を作り、$${qk_1^Tv_1}$$の左側と$${qk_2^Tv_2}$$の右側を合体させる、といった感じのことをやります。
Latent coupleとの比較
いいところ:
計算量が少ない
一部のモジュール以外は1枚の画像として計算するため、より1枚の画像っぽくなるはず
だめなところ:
実装がめんどい
UNetを置き換えるためLoRAやControlNet等の拡張とばっちんぐするかもしれない。
今後の課題
webUI拡張:だれかやって・・・
ControlNetの適用:だれかやって・・・
LoRAの適用:だれかやって・・・
kohya-ssさんがLoRAの領域別適用と合わせて実装されたようです。(今のところ別のブランチで実装)
またhako-mikanさんがAttention couple機能のみの実装をしているようです。(こっちはLoRAが不必要)
PFG(前回記事参照)の適用:だれか・・だれもやらんか・・・
おわりに
Latent coupleの改良案は公開されてから結構考えていたんですが、全く思いつきませんでした。今回なぜかLoRAの領域適用という文脈でこの実装を思いつきましたが、これがLatent coupleにも応用できることに気づきませんでした・・・。Latent coupleを公開してくれたきざみみさんとアイデアを示してくれたKohyaさんに感謝いたします。