Token MergingによるStable Diffusionの高速化について

Stable Diffusionの高速化手法で、最近webuiでも実装されたToken Merging、通称ToMeについて説明していきます。
概要
画像生成中に画像の似ているピクセル同士をマージすることで高速化します。トークンマージングという言葉だけでみると、Stable Diffusionを楽しんでおられるであろう諸兄は、プロンプトのトークンをマージするのかな?と思ってしまうと思いますが、実際にはプロンプトは関係ありません。なぜピクセルのことをトークンと呼んでいるかというと、画像をまるで文章かのように扱うモデルで使われる手法だからです。Vision Transformerというモデルでは画像をグリッド状に分割して、それぞれのグリッドをトークン(単語)とすることで言語モデルで使われるTransformer(ChatGPTのTですね)に似た計算ができるようにしたものです。Stable DiffusionにもVision Transformerが使われていますが、画像はグリッドではなくピクセルごとに分割されています。つまり1つのピクセルが1つの単語として扱われています。この手法は学習にも生成にも使えます。
オリジナルのToMe
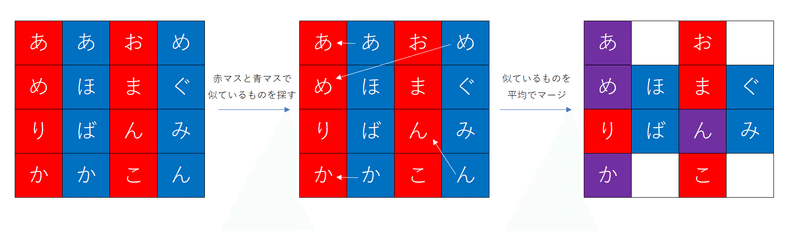
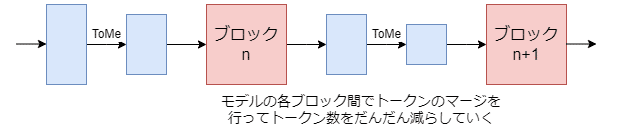
ToMeは画像分類モデルの効率化に使われる手法です。モデルの各ブロックで似たトークンをどんどんマージしていって、計算量を減らしていきます。似たトークンを探す効率の良い方法として、ニ分割ソフトマッチングという方法が提案されています。これはトークンを二つの集合に分けて、マッチングをするだけです。図のように赤と青に分割して、青のトークンそれぞれに対して、一番近い赤のトークンを探します。そしてマッチ度の高い順に減らしたい数だけマージします。マッチ度は行列積によって計算できます($${A^{(\frac{N}{2},dim)}B^{T(dim,\frac{N}{2})}}$$)。Self Attentionの$${qk^T}$$と似てますが、二分割することで類似度を測る組合せ数を減らしているようですね。分割方法は偏らないよう工夫する必要がありますが、元論文では列を赤青赤青みたいに交互に割り当てるだけみたいです。
これをモデルのブロックごとに繰り返していく事で、どんどんトークンが減っていき計算を効率化できます。
他に類似度を測る対象として入力ではなくkeyを使うとか、ソフトマックスの前にマージしたトークンに重みをつけるといった工夫が紹介されていますが、これから話すStable DiffusionにおけるToMeでは行われていません。
Stable DiffusionのToMe
論文
実装
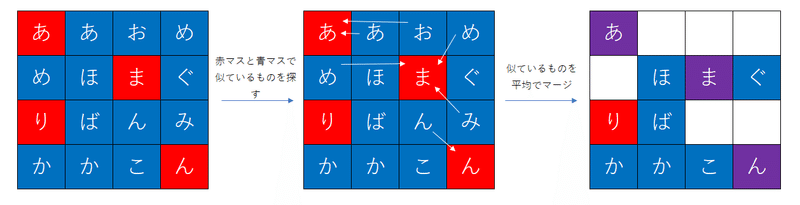
オリジナルのToMeは分類問題で使うものですので、出力層に近づくほどトークンを減らしていくのは自然です。しかし画像生成モデルでは出力がちゃんとした画像である必要があるので、トークン数(ピクセル数)がどんどん減っていったら困ります。そこでマージ→重い計算→アンマージという流れを繰り返します。この場合一度で一気にトークンを減らす必要がありますが、オリジナルの方法はきれいに二分割してしまうため、たとえばトークン数を半分にしたいときは青マスのすべてのトークンがマージされてしまいます。そのため赤マスの数<<<青マスの数という関係にする必要があります。そこでグリッド状に分割し、各グリッドでランダムに1つ選び赤マスにして、それ以外を青マスにする方法が提案されています。標準設定では2×2のグリッドで分割するため、赤が4分の1で、青が4分の3になります。webuiではいくつかのサンプラーで問題が起こるらしく、ランダムではなくグリッドの一番左上を赤にするという決め方をしているみたいです。
実験結果の概要
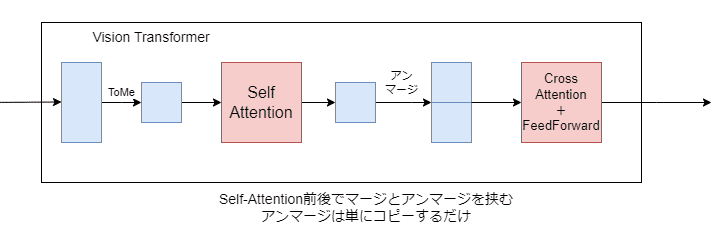
Stable DiffusionのVision TransformerはSelf Attention, Cross Attention ,Feed Forwardの3つに分かれますが、このうちSelf Attentionの前後でマージとアンマージを挟むことが推奨されています。まあSelf Attentionが一番計算量が大きいので自然ですね。
UNet内で画像が圧縮されていない外側のブロック(つまりトークン数が一番多いブロック)にのみ適用するのが性能と速度のトレードオフ的に一番いいらしいです。
拡散ステップごとに減らすトークン数を変えるという戦術も考えられるが、微妙な効果しかないみたいです。論文で拡散ステップといってるときに順方向なのか逆方向なのかがよく分かりません。
WebUIでは減らすトークンの割合(ratio)しか設定できません。それ以外は1や2に基づいた設定になっています。拡張機能もあるみたいですが、デフォルトから変えていいことあると思えないので、標準搭載された設定だけで十分だと思います。ただしグリッドの分割も変えられないので、ratioは0.75が限界です。
実際にマージの様子をみてみる
というわけで実際に生成してみて、マージされた様子をみてみます。ratio=0.5で適当に生成して、同一シードでもう一回生成します。このとき生成画像にもマージ・アンマージを適用して結果を保存してみます。20ステップで生成して5ステップごとに各ブロックで行われたマージをみてみます。

ノイズが大きい状態では結構ぐちゃぐちゃなマージになっていますが、だんだんちゃんとマージされるようになっていますね。ただノイズが大きい状態のときは予測も粗くていいので、マージしても性能が低下しづらそうです。逆にノイズが小さい状態ではマージそのものの精度が上がる代わりに細部まで忠実に再現する必要があるのでマージ自体が性能低下につながりそうです。そういう意味でステップごとに減らすトークン数を変えてもあまり変化がないのかもしれません。
まとめ
すごいですね。