
科学的発見が誇張→曲解→誤解→蔓延するメカニズムの図解と簡単で効果抜群の2つの対策

科学的発見が私たちに届くまでの伝言ゲームで、さまざまな誇張・曲解・誤解が注入されています。

いったい、どうやったら、この伝言ゲームに勝ち、信用できる科学的発見と、地雷とを見分けることができるのでしょうか?

『Science Fictions』という本がその参考になります。
この本は、アメリカのamazonで306人に評価され、☆4.6という高評価。
世界最大の書評サイトgoodreadsでは1925人に評価され、☆4.39という高評価。
日本のamazonでは31人に評価され、☆4.0と、中程度の評価(翻訳は良い)です。
この記事では、この本を元に、以下の2つの視点から、この問題と、その解決策を検討します。
〔問題の把握〕 科学的発見の流通システムにおいて、いかにして、発見が誇張され、曲解され、誤解され、流通し、最終的に私たち一般人がそれを信じてしまうのか、その全体像を把握する。
〔解決策〕 インチキな「科学的発見」に騙されにくくする、誰でも簡単に実行できる、効果抜群の2つの対策をやる。
こまけぇこたぁいいんだよ!! 答えだけ教えろ。 10秒で教えろ。

という方は、「一般人がやるべき対策」という章の末尾の「まとめ」というセクションだけお読みいただければ。
(目印にやる夫画像を貼っておきます)
「なぜ、その答えになるのか?」を知りたい方のために、以下、解説します。
効果量
最初に「効果量」について説明します。

「成長マインドセット」の研究をご存じでしょうか?
スタンフォード大学教授キャロル・ドゥエックによれば、マインドセット(思考態度)には以下の二種類があります。
〔成長マインドセット(growth mindset)〕 人間の基本的資質は努力次第で伸ばすことができると思っている。
〔固定マインドセット(fixed mindset)〕 人間の基本的資質は生まれつき決まっていて変わらないと思ってる。
どちらのマインドセットを持つかによって人生が劇的に違ってくる、というのが、彼女の主張です。
20年にわたる研究の結果、それが分かったと言うのです。
彼女は、それを一般人向けの本に書き、"Mindset: The New Psychology of Success"(邦訳:『マインドセット:「やればできる!」の研究』)という本として2007年に出版し、世界的なベストセラーになりました。
アメリカのamazonでは2万1138人に評価され、☆4.6という高評価。
書評サイトgoodreadsでは14万8152人に評価され、☆4.09という高評価。
日本のamazonでも1948人に評価され、☆4.3という高評価です。
以下、この本からから引用します。
本書を読まれれば、自分についてのある単純な信念---私たちの研究で発見された信念---が人生をどれほど大きく左右しているかがおわかりになるだろう。
その信念は、人生のありとあらゆる部分にまで浸透している。
自分の性格だと思っているものの多くが、じつはこの心のあり方(=mindset)の産物なのである。
あなたがもし可能性を発揮できずにいるとしたら、その原因の多くは"マインドセット"にあると言ってよい。
(太字改行引用者)
彼女の成長マインドセットのTED の再生回数は1546万回、
YouTube は575万回です。
彼女のこの理論は、教育界でも強い支持を広く集めています。
マインドセットの概念は教育界で熱狂を巻き起こした。
2016年にアメリカの教師を対象におこなわれた調査では、57%の人が成長マインドセットの原則に関するトレーニングを受けたことがあり、98%が成長マインドセットの考え方を教室で実践すれば生徒の学習が向上すると答えている。
イギリスでも数千の学校が公式サイトで、成長マインドセットの方針を掲げている。
(改行引用者)
これは、この理論が、教育現場において実践しやすいことも理由の一つかも知れません。
ドゥエック教授は、
「わあ、○点も取ったの、いい点ね。あなたは頭がいいわ」と「能力」褒めれば固定マインドセットを持つようになり、
「わあ、○点も取ったの、いい点ね。よく頑張ったわ」と「努力」を褒めれば成長マインドセットを持つようになる、
と言うのですから。
では、この手の話に手厳しいことで有名なはてなブックマークはどうでしょうか?
この本の内容を紹介したGigazineの記事には1377のブックマークがつき、それについたコメントの多くは肯定的で、この研究結果自体を懐疑しているコメントはごくわずかです。
これだけ多くの人々に絶賛される理論ですから、アメリカとイギリスだけでなく、他の国でも効果があるに違いありません。
そこで、中国の9~13歳の子供624人を被験者にして、成長マインドセットの検証実験( Li,Y.,& Bates, T.C., Ph.D. 2017年)が行われました。
しかし、どちらのマインドセットを持つかによって、IQにも学業成績にも違いは出ませんでした。
中国人が特殊な文化を持っているためでしょうか?
それとも、624人では、被験者数が少なすぎて、この効果を統計的に検出できないのでしょうか?
では、チェコ共和国の大学生5653人を被験者にして行われた実験( Bahnik, Stepan, and Marek A. Vranka 2017年)はどうでしょうか。
実は、その研究でも、成長マインドセットと固定マインドセットの違いは検出できませんでした。
大学生だからダメなのでしょうか?
もっと幼いうちでないと、効果がないのでしょうか?
ところが、イギリスの6歳の生徒4584人を被験者にしたFoliano, F., Rolfe, H., Buzzeo, J., Runge, J., & Wilkinson, D.の2019年の研究でも、やはり、効果は検出できなかったのです。
アメリカの大学の数学と心理学の学生2607人を被験者にしたCaitlin Brez, Eric M. Hampton, Linda Behrendt, Liz Brown & Josh Powersの2020年の研究でも、効果は検出できませんでした。
これほど多くの被験者でも検出できないなんて、本当に、そんな効果は存在するのでしょうか?

成長マインドセットは、ドゥエック教授のでっち上げではないのでしょうか?
ところが、そうでもないのです。
2018年には300件以上のマインドセット研究のメタアナリシスがおこなわれ、成長マインドセットと学校や大学での成績の相関関係をアンケートを用いて測定した研究と、成長マインドセットに誘導して成績を向上させようという実験を解析した。
いずれの場合も効果は実際にあったが、弱かった。
相関関係については、生徒のマインドセットが成績の変動に関与する割合は約1%だった。
(改行引用者)
メタアナリシスとは、過去に報告された複数の研究結果を統合するための統計解析のことです。

個別の実験としては信頼性が最高レベルのランダム化比較試験と比べても、メタアナリシスはさらにエビデンスレベルが高く、信頼性が高いとされています。

つまり、効果は、たしかに存在するのです。
ただ、効果が微弱なため、実験条件によって、被験者によって、ノイズによって、効果を検出できたり、できなかったりするのです。
メンタリストDaiGo氏の『超効率勉強法』という本では、ドゥエック教授の「成長マインドセット」を激推ししていて、かなりのページ数を割いて解説しています。
DaiGo氏は、チャンネル登録者数226万人のYouTuberで、科学的根拠のある話をすることをウリにしている方です。
以下、『超効率勉強法』から引用します。
成長マインドセットを育てれば、生まれつきの天才にはかなわないにせよ、それに近いパフォーマンスを発揮しやすくなります。世間で「努力の天才」と呼ばれるような人たちは、みんな似たような思考法を持っているのです。
これを読んだ人は、「成長マインドセット」にはものすごい効果があると思ってしまいそうですが、実際には、微妙な実験条件の違いで効果が検出できたりできなかったりする、不安定で微弱な効果しかありません。
つまり、効果が誇張されているのです。
この本は、どれくらいの人が買っているのでしょうか?
なんと発行部数20万部。
ものすごく売れてます。
Amazonレビューでの評価はどうでしょうか?

なんと1441人に評価され、☆4.3の高評価です。
以下、この本についたAmazonレビューコメントをいくつか引用します。
「科学的に証明されている」勉強法が詰まっていて、学習する上では必須の知識、応用方法が凝縮されています。
実験や研究をもとにした内容ですので「なるほど」です。
ちまたでは、科学的に間違った学習法でも、
「売れている」
本はいくつもあるので、注意しなければならないが、
この本は、「売れて」いてなおかつ「正しい」勉強法の本である。
成功者が書いているので説得力が違います。子供にも教えたいと思います。
こうして、微弱な効果が発見され、それが誇張されて本に書かれ、それを誇張したスピーチがTEDで行われ、それをYouTuberやブロガーがさらに誇張し、Amazonレビューに絶賛コメントが多数付き、我々一般人の多くが絶賛するというわけです。

「メタアナリシスだから信用できる」は本当か?
メタアナリシスの結果、成長マインドセットには微弱な効果があることが判明しました。
しかし、そもそも、「メタアナリシスだから信用できる」と言っていいのでしょうか?
それを確認するため、「ロマンチック・プライミング」のメタアナリシスを見てみましょう。
これは、「魅力的な女性の写真を見せられた男性は、より多くのリスクを冒し、消費財に金をかける(パートナーを惹きつけるために「目につく消費」をする)」という仮説です。
心理学者のデイビッド・シャンクスらは、そのメタアナリシスを行いました(2015年) 。
すると、これについて15本の論文が見つかり、43の実験について記されていることが分かり、仮説が裏付けられたかのように見えました。
メタアナリシスという望遠鏡によって、銀河が見えたのです。
ところが、シャンクスたちが大規模な実験でロマンチック・プライミングを再現しようとしたところ、再現された効果はすべてゼロ付近に集まりました。
銀河は見えなかったのです。
大規模な実験というのは、大型望遠鏡です。

はるか遠くの銀河まで、鮮明に見えるはずです。
なのに、そこにあるはずの銀河が、見えなかったのです。
いったい、なぜ、大規模実験の結果とメタアナリシスの結果が矛盾したのでしょうか?
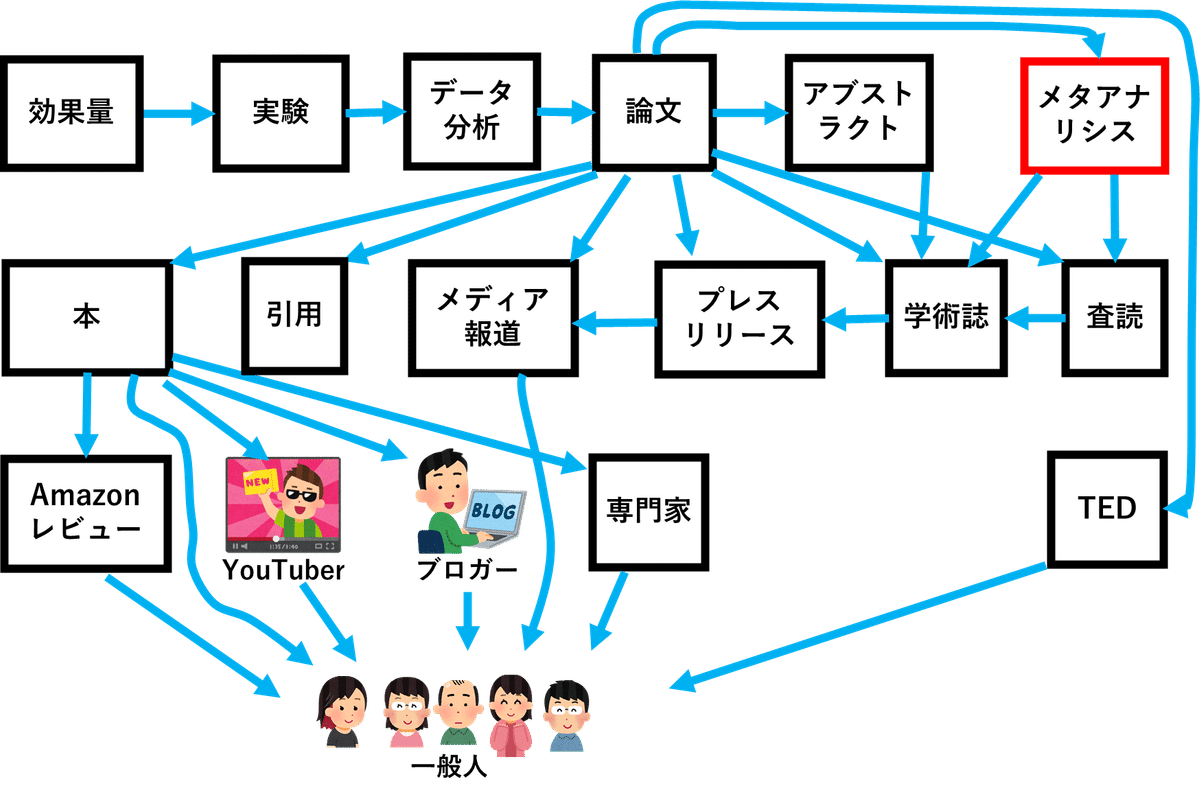
メタアナリシスにおいて、サンプル数(被験者数)を縦軸、検出された効果の大きさを横軸にした図に、各論文の実験結果をプロットしていくと、理論上は、以下のようになるはずです。

なぜなら、サンプル数が小さい実験ほどノイズが入りやすいので、検出された効果にばらつきがでるからです。
逆に、サンプル数が大きくなれば、ノイズが除去されるので、検出される効果の大きさにばらつきがなくなるはずです。
ところが、実際には、この図のようなきれいなファンネルにならないことがよくあります。
なぜかというと、「効果が検出されなかった」という論文(NULL論文と呼ばれる)を学術誌に掲載してもらおうとすると、拒否されることが多いからです。
また、NULL論文は、研究者の業績としても評価されにくいので、NULLの結果が出たら、それを、そもそも論文に書かない研究者が多いからです。
その結果、下図のようになることが多いのです。
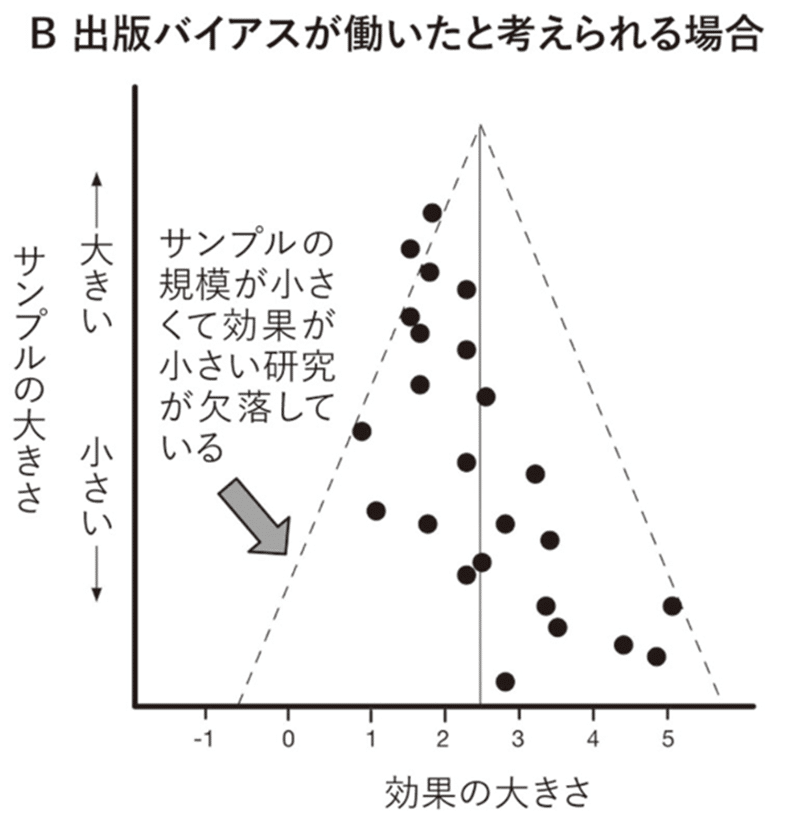
(『Science Fictions』より引用)
これを、出版バイアスと呼びます。
これによってメタアナリシスのレンズが歪んでしまい、存在しない銀河が、メタアナリシス望遠鏡のレンズに映ってしまうというわけです。
実は、さきほどのシャンクスらのメタアナリシスにおいても、出版バイアスがないか調べてみたところ、NULL論文があるはずのところから、ごっそり論文が抜けていることが分かりました。
分かりやすいように、シャンクスらの行ったメタアナリシスを雑なイメージ図で説明します。
NULL論文も全て出版されていれば、理論上は、以下のようになっていたはずです。

つまり、サンプル数(被験者数)が大きい実験ほど検出される効果はゼロに近づきます。
また、サンプル数が小さい実験はノイズが混じるので、効果はマイナスとプラスに同じように散らばるのです。
しかし、NULL論文が出版されにくいことにより、実際には、下図のようになってしまったというわけです。
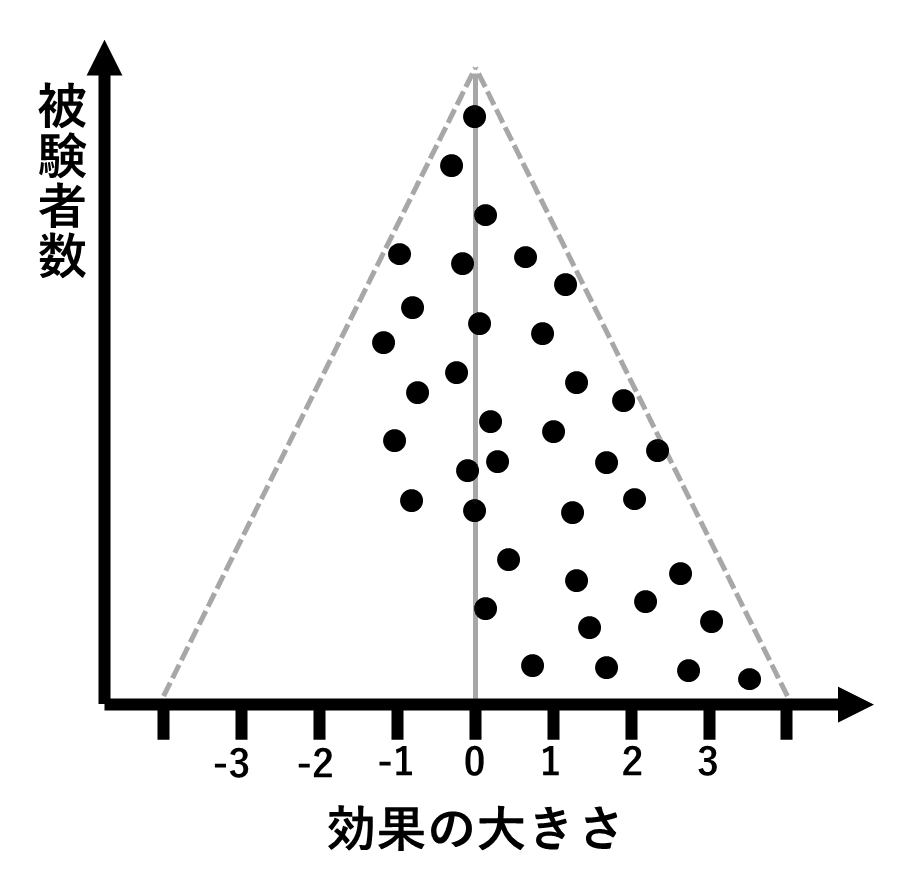
このため、仮説を支持する論文が多数派になり、ありもしない銀河が見えてしまったというわけです。
そういうわけで、メタアナリシスが信用できるかどうかは、そのメタアナリシスが、出版バイアスをどの程度考慮して補正しているかに依存します。
「メタアナリシスだから信用できる」とは、一概には言えないのです。
ありもしない効果が検出されるプロセス
この章では、双六(すごろく)の「データ分析」のところを解説します。

出版バイアスさえなければ、実験結果は信頼できるのでしょうか?
一般に、p値が0.05未満だと、統計的に有意だと見なすことが多いです。
実は、「p値が0.05未満だと、統計的に有意」になるのは、あくまで、一種類の統計検定だけをやることが前提の話です。
統計検定Aではp値が5%未満にならなかったので、統計検定Bを試し、それでもダメだったからCを試し……をくり返し、ついに、Gで4.8%になったとします。
この場合、前提条件が崩れてしまっています。
サイコロを何度も振っているからです。
さらに、被験者全部のデータを使うと、どういう統計分析をやっても有意にならなかったとします。
そこで、「この効果が出るのは、身長が低いor高い人に限られるのかもしれない」と考え、被験者を身長170センチ以上と未満に分割して分析したとします。
その結果、身長170センチ未満の被験者だけで分析すると、p値が0.045になることが分かったとします。
この場合も、前提が崩れています。
サイコロを振った回数が多くなっているからです。
ここで、それでもまだ、統計的に有意にならなかった場合を考えます。
その場合、被験者の中に、データを大きくゆがめている人がいないか、調べます。
すると、被験者の中に、仮説とは逆の振る舞いをする人がいて、それがデータを大きくゆがめていることが分かりました。
その被験者を除外すれば、統計的に有意になります。
そこで、実験者は、「その被験者を除外する正当な理由」を、一生懸命考え出します。
たとえば、その被験者は、実験当時、体調が悪かった、とかなんとか。
そして、その被験者を除外して、データを分析し直すと、p値が0.041になったとします。
しかし、こういうことをやっていれば、当然、前提は崩れています。
やっぱり、サイコロを振る回数が増えているからです。
実は、こういうp-hackingやHARKingと呼ばれるインチキ行為は、広く行われていると考えられています。
以下、『Science Fictions』から引用します。
ワンシンクは自分のフログの投稿で、ニューヨークのピザレストランで収集したデータセットを分析するように大学院生に勧めたことを書いた。
彼は大学院生に、最初に立てた仮説は「失敗」したが、仮説を支持しない結果を論文として発表したり、すべてをお蔵入りにしたりするのではなく、「(データセットを)救済する手が何かあるはずだ」と伝えた。
彼女はそれに応えて、「毎日のよう に……不可解な新しい結果を持ってきて……毎日のように……データを再分析する別の方法を思いついた」。
ワンシンクは、自分のデータセットをさらって何かしら「重要なもの」を探していたことを率直に認めたことによって、自分だけでなく残念ながら大勢の科学者が研究をおこなう方法に大きな欠陥があることを、意図せず明らかにした。
こうして、科学者の「データ分析」の「努力」が実って、ありもしない効果が検出され、その科学的発見をYouTuberとブロガーが大げさに喧伝し、それを一般の方々が絶賛することになったりするわけです。

論文検索はどのくらい信用できるか?
「成長マインドセット」でググると、「成長マインドセットは教育や人材育成のカギを握る重要なものだ」という主張ばかりが目につきます。
検索結果をいくらスクロールしても、再現実験に失敗したとか、その効果が微弱であるという記事は、なかなか見つかりません。
普通の検索エンジンの結果を鵜呑みにすると、とんでもない勘違いをしてしまいそうです。
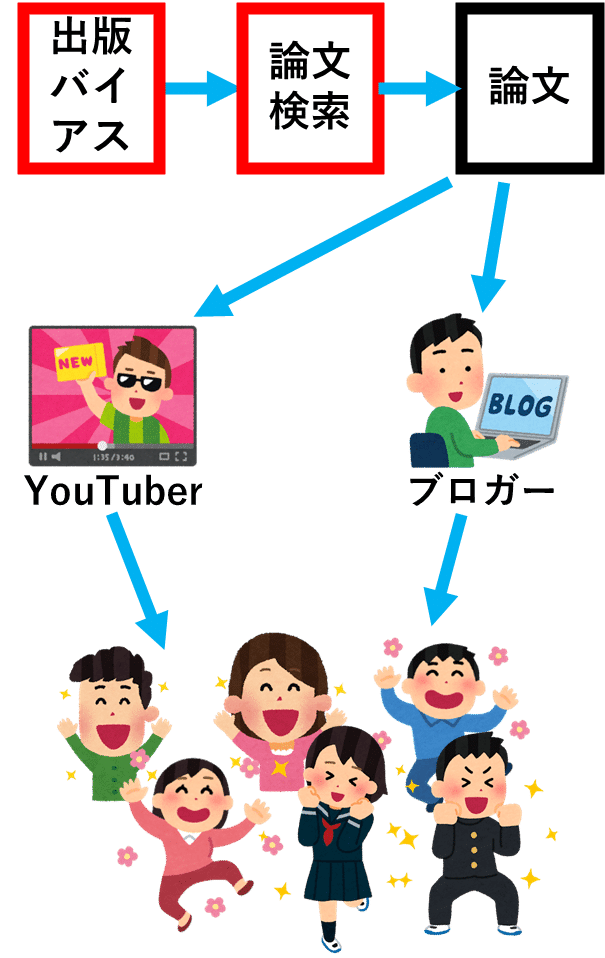
そこで、Googleスカラーなどの、論文検索エンジンを使います。
ところが、論文検索をやると、ターゲットとする効果が検出されたという論文の方が多く引っかかり、NULL論文は少ししかひっかかりません。
これも、出版バイアスです。
学術誌も大学もNULL論文を好まないために、検索結果が歪んでしまっているのです。
「論文検索して出てきた関連論文を片端から全部読んだが、効果が証明されたという論文がほとんどだったから大丈夫だろう」
などと考えると、「ロマンチック・プライミング」のような、とんでもない勘違いをすることになります。
このため、論文を大量に読んで自説に自信を持ったYouTuber/ブロガーが、それを根拠に自説を記事/動画で語り、それを人々が絶賛することになるというわけです。
超一流の学術誌なら信用できるか?
しかし、ネイチャーやサイエンスのような、超一流の学術誌に掲載された論文なら信用できるのではないでしょうか?
一流の学術誌は、一流の科学者たちに査読された一流の論文しか掲載しないはずだからです。
「査読(さどく)」とは、その学問分野の専門家が読んで、内容の評価を行うことです。
科学的発見の信頼性を議論する上で、「学術誌」と「査読」はキモとなるところなので、ここは、少し詳しめに見ましょう。

それらを理解するための良い例が『Science Fictions』で紹介されていたので、少し長くなりますが、説明します。
2008年、医療系で最も権威ある学術誌の一つ『ランセット』に一本の論文が掲載されました。
これは、イタリアの外科医パオロ・マッキャリーニによる論文で、「気管の移植に成功した」というものです。
この論文を機に、マッキャリーニは天才外科医として評判が高まり、2010年にはスウェーデンのカロリンスカ研究所(カロリンスカ医科大学)に教授14人の推薦を受けて客員教授として迎えられ、付属のカロリンスカ病院の主任外科医に就きました。
カロリンスカ研究所は優れた大学がそろうスウェーデンでトップクラスというだけでなく、ノーベル医学・生理学賞の選考委員会が置かれています。
マッキャリーニは次々と手術を成功させ、2011年には2本目の論文も『ランセット』に掲載されました。
サンクトペテルブルク出身のバレエダンサー、ユリア・トゥーリクさんは健康でしたが、この「天才外科医」マッキャリーニの画期的な手術を受けることにしました。
交通事故の影響で、気管に穴が開いており、話すときには穴を自分の手で塞がなければならなかったからです。
彼女は、息子に歌を歌ってやるために手術を受けることにしたのです。
この手術を受けてしばらく後、彼女はジャーナリストのインタビューに対して、以下のように語ったということです。
何もかも、すべてが最悪です。
クラスノダールの病院に入院して半年あまり。
全身麻酔で30回以上、手術を受けました。
最初の手術の3週間後に化膿した瘻孔〔膿が漏れる穴〕が開き、その後、首が腐ってしまいました。
体重は47キロ。
歩くのもやっとです。
息をするだけで苦しくて、今では声も出ません。
そして、あまりにも強烈な臭いがして……人々が後ずさりします。
(改行引用者)
彼女は最初の手術から2年後の2014年に死亡しました。
彼女の手術は、たまたま運悪く失敗したのでしょうか?
実は、マッキャリーニがこの手術をした患者は、みな、同じような状況でした。
以下、『Science Fictions』から引用します。
カロリンスカ病院でマッキャリーニの患者を術後に担当した医師たちは、目の前の患者の悲惨な状態と、科学論文で報告され称賛されている結果が、どうしても一致しなかった。
彼らはカロリンスカ研究所の所長に不満を訴えた。
ところが、研究所からは驚きや懸念が返ってくるどころか、申し立ては相手にされず、口止めさえされたのだ。
さらに、患者のカルテを見てプライバシーを侵害したとして警察に通報された(この告発はすぐに取り下げられた)。
最終的に、研究所の上層部は医師たちの強い訴えを無視できなくなり、近くにあるウプサラ大学の教授を独立した研究者として迎え調査を始めた。
2015年5月に発表された長文の報告書は、これ以上ないほど明確だった。
マツキャリーニは複数の「科学的不正行為の罪」をおかしていた。
彼の7本の論文で、必要な検査をしていないにもかかわらず患者の状態が改善したと偽る、患者がより長く健康だったように見せるために追跡期間を偽って記載する、患者が重度の合併症になったことや追加の手術を受けなければならなかったことを報告しない、人間を対象とする医学的実験をおこなうための倫理的な許可を正しく得ていない、ラットの気管を置換する実験でデータを改ざんする、などの行為が認められた。
ただし、これで終わりではなかった。
独立調査機関が指摘した疑いについてマッキャリーニが説明に応じた後、カロリンスカ研究所は独自の内部調査をすると決めた。
そして2015年8月、非公開の情報をもとに、実際は不正行為はなかったと結論づけたのだ。
その翌週に『ランセット』は、「パオロ・マッキャリーニは科学的不正行為の罪をおかしていない」と祝福した。
マッキャリーニの容疑は晴れた----医学界で最も権威ある2つの機関が「潔白」を証明したのだ。
(太字改行引用者)
その後もいろいろあって、結局、さらなる調査が行われ、真実が誰の目にも明らかになったわけですが、最終的にマッキャリーニが解任されたのは2016年3月、最初に失敗した人工気管移植手術から7年も経った後のことでした。
双六で言うと、「実験」にあたる部分に、そもそも問題があったわけです。
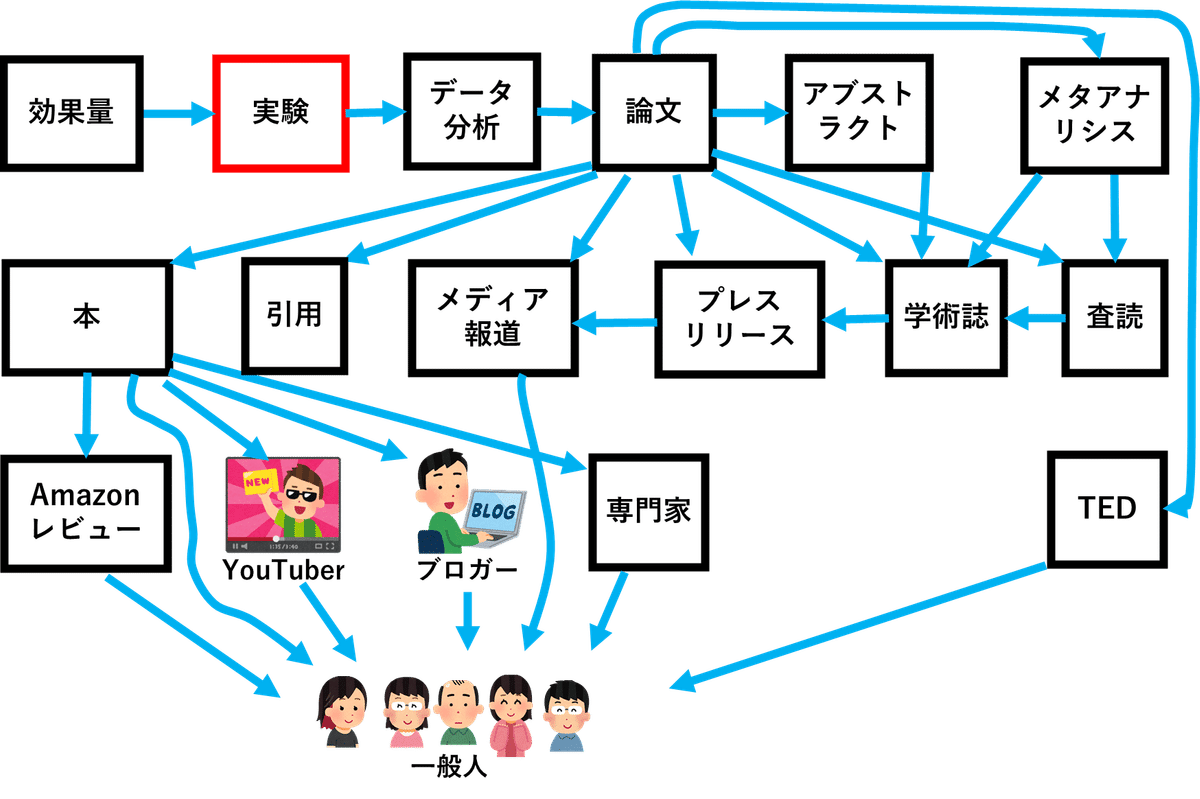
なぜ、超一流の学術誌が、こんなインチキ論文を掲載したのでしょうか?
なぜ、査読を行った一流の医学者たちは、マッキャリーニのインチキを見抜けなかったのでしょうか?
実は、ほとんどの場合、査読を行う専門家たちには、詳しいデータは公開されていないのです。
これは、医療系の学術誌に限った話ではなく、ほとんど全ての学術誌がそうなのです。
査読者は、税務署の職員が税務調査をするように実験や手術の詳細を調べたりはしません。
彼等は、マッキャリーニが自己申告したことは全て事実だという前提で、査読を行ったのです。
以下、『Science Fictions』より引用します。
査読者は、基本的に結果の解釈について懐疑的だが、データが偽物かもしれないという考えがすぐに浮かぶことはない。
また、査読者の人選自体がハックされることもあります。
以下、『Science Fictions』より引用します。
たとえば、科学者が学術誌に論文を投稿する際に、査読者を自ら推薦できるという意外な事実がある。
詐欺師はこれを利用する。
推薦された査読者に論文を送るか、あるいは編集者が選んだ査読者に送るかは編集者の自由だが、たいてい前者になる。
著者が査読者を推薦するというそもそもの意図は、多忙な編集者が論文に関連のある適切な専門家を探す負担を軽くするためだ。
この仕組みは、言うまでもなく、悪用にうってつけだ。
著者が友人や同僚を査読者として推薦すれば、出版までの道のりが楽になる。
それだけでも十分に問題だが、不正行為は簡単にエスカレートする。
ある編集者は、生物学者のムン・ヒュインのケースを紹介している。
『〔ムンは〕好ましい査読者を推薦していた……〔彼らは〕偽の名前と身元やアカウントを使った、彼自身や同僚だった。
実在する人物の名前もいくつかあったが(ネットで検索すればわかる)、自分や同僚が管理できるメールアドレスを勝手に作成し、自分で査読してコメントを記していた。
偽名でメールアドレスを作成しただけの場合もあった。
これらの査読者が提出したコメントは、ほぼすべてが好意的だったが、論文を改善するための提案もあった。』
(改行引用者)
査読の不正をしたのは、もちろん、ムンだけではありません。
これも本書から引用します。
2016年に大手科学出版社のシュプリンガーは、自社の『トウモア・バイオロジー』誌で査読の不正が横行していることに深く絶望し、わずか4年分のバツクナンバーから汚染された論文107本を撤回した後、この学術誌の発行をあきらめて別の会社に売却した。
マッキャリーニ事件に話を戻します。
いつもの双六(すごろく)で整理すると、「実験」自体に問題があり、「論文」がねつ造され、それを「査読」が通過させてしまい、「学術誌」がそれを掲載してしまったために、インチキな事実が「メディア報道」され、それを一般人が信じてしまい、健康だったバレエダンサーのユリア・トゥーリクさんも信じてしまい、首が腐ってお亡くなりになられた、ということになります。

マッキャリーニの論文は、例外でしょうか?
もちろん、ここまで酷いインチキは、例外的です。
しかし、これほど大きなインチキが一流の専門家による査読を通過し、一流の学術誌に二度も掲載されてしまったという事実には意味があります。
なぜなら、もっと小さくて分かりにくい微妙なインチキの多くは、査読においても気づかれにくく、通過してしまっていると考えられているからです。
たとえば、統計的に有意な結果にならなかったために、さまざまな統計検定を試し、それでやっと統計的に有意になるパターンを見つけたとします。
そうやって見つけた統計的有意性には、統計的な妥当性はありません。
そこで、研究者は、はじめからその統計検定だけを行うつもりだったかのように論文を書くのです。
つまり論文にウソを書くのです。
こういうインチキをやっても、統計分析の過程が自己申告であるため、バレにくいです。
また、それでも統計的に有意にならなかったので、被験者を身長170センチ未満と以上に分割して、それぞれ統計検定を行って、170センチ未満の被験者でだけ統計的に有意になったとします。
その場合、はじめから170センチ未満の人で有意な結果がでるだろうと仮説を立てていたかのように、論文にウソを書いても、なかなかバレません。
都合の悪いサンプルを、もっともらしい理由をつけて除外するのも、同様です。
はじめからそういう方針で実験計画を立てていたかのように論文を書いてしまえば、バレにくいのです。
論文のアブストラクト(要約/概要)は信用できるか?
科学的根拠がある話をすることがウリのYouTuberが、別のYouTuberとネットバトルをしているとき、「主張の根拠が論文に書かれているかどうか」が議論の焦点になっていたことがあります。
私はそのバトルを観察していたのですが、興味深かったのは、彼等は論文の本文は読まず、アブストラクト(要約/概要)だけ読んで論争していたということです。

アブストラクトとは、論文の冒頭に書かれている要約/概要で、そこは無料で読めます。
しかも、非常に短いので、すぐに読めます。
Web小説の投稿サイトの場合、小説の「概要」ページには、小説の結末までは書いてません。ネタバレになってしまうからです。
これに対し、論文の「アブストラクト」には、論文の結論まで書いてあります。ネタバレしてるのです。
ということは、論文の結論だけ知りたい人は、アブストラクトだけ読めば十分?
ところが、論文のアブストラクトには「スピン」と呼ばれる粉飾や誇張に近い表現が含まれていることが多いのです。
以下、『Science Fictions』から引用します。
2010年のある分析では、NULLの結果になったランダム化臨床試験(試験対象の治療法とプラセボで差がなかった臨床試験)の代表的なサンプルについて、スピン(ここでは、ポジティブな発見がないことから読者の注意をそらすために使われている表現を指す)がどの程度含まれているかを調べた。
その結果、論文のアブストラクトの68%および本文の61%に、臨床試験で失敗したにもかかわらず、その治療法の利点を強調しようとする部分があった。
また、論文の20%はすべてのセクション(イントロダクション/序論、メソッド/手法、リザルツ/結果、ディスカッション/考察)に少なくとも1つのスピンがあり、18%はタイトルにもスピンが含まれていた。
(改行引用者)
アブストラクトの誇大表現は、NULL論文に限った話ではありません。
Christiaan H.らが2015年に行ったアブストラクトの分析も、本書では紹介しています。
この分析(引用者注:Christiaan H.らが2015年に行った分析)は特定の用語を含むアブストラクトの割合を年別にグラフ化している。
それによると、「革新的(innovative)」「有望(promising)」「頑健(robust)」の使用率は飛躍的に増加しており、「ユニーク(unique)」「前例のない(unprecedenied)」も(逆説的 かもしれないが)大幅に増えて、「良好な(favourable)」は着実に増えている。
「画期的(groundbreaking)」は、1999年頃までは ほぼゼロで推移していたが、何らかの理由で突然、増加した。
平均すると、これらの自画自賛のポジティブな言葉の使用率 は、1974年のわずか2%から2014年には17.5%と、分析期間を通じて9倍近くに増えている。
この論文の著者たちは、「過去40年間のポジティブな単語の増加傾向から推定すると、2123年にはすべて(のアブストラクト)に『斬新 (novel)』という言葉が登場するだろう」と痛烈に結んでいる。
(改行引用者)
論文を読むときは「タイトル詐欺」だけでなく「アブストラクト詐欺」にも注意しないといけないということです。
論文を根拠に何かを主張している人がいたら、その人がちゃんと論文の本文を読んでからそう言っているのか、それともアブストラクトだけしか読まずにそう言っているのか、ちゃんと確認した方が良さそうです。
論文の本文は信用できるか?
じゃあ、論文の本文は信用できるのでしょうか?

ところが、スピンは、アブストラクトだけではなく、本文にも蔓延しているのです。
科学のスピンについては数多くの論文があり、それぞれの分野の現状を明らかにしている。
たとえば、産科・婦人科の臨床試験のうち15%は、有意ではない結果をあたかも治療の効果を示しているかのように見せている。
ガンの予後検査に関する研究の35%は、有意でない結果をあいまいにしてわかりにくくするためにスピンを使っていた。
複数の一流学術誌に掲載された肥満治療の臨床試験の47%に何らかのスピンがおこなわれていた。
抗鬱薬と不安神経症の治療薬の臨床試験について報告している論文の83%が、研究デザインに関する重要な限界を議論していない。
脳機能イメージングの研究に関するレビューは、相関関係を因果関係に誇張することが「横行」していると結論づけている。
スピンのなかには、不正行為に発展したり、少なくとも重大な機能不全にいたったりするものもある。
2009年のレビューによると、中国の医学誌に掲載されたランダム化対照試験と称する研究のうち、実際にランダム化をおこなっているのはわずか7%だった。
(改行引用者)
実際、論文の「実験手続き」と「実験結果のデータ」が、本文の文章と一致しないことは珍しくありません。
なので、私が論文を読むときは、最初に論文全体をサクッと斜め読みしたら、すぐに「実験手続き」と「実験結果のデータ」をチェックします。
その後に本文の文章をちゃんと読むと、「この実験手続きとこの結果データからそれを主張するのは無理があるor言い過ぎだろ」ということが書いてあることが、よくあるのです。
というわけで、論文の本文の文章を引用して、「この論文には、こう書いてある」と、どや顔で自説を主張の根拠を示す人がいたら、「その論文の文章は、本当に、その実験手続きとデータから主張できることなのかな?」と疑問を持った方がいいです。
プレスリリース
論文が出版されると、そのプレスリリースがメディアに向けて発表されます。
プレスリリースとは、ニュース素材としてメディアの記者が利用しやすいように、文書や資料としてまとめたもののことです。

プレスリリースの作成にも、科学者が深く関わっています。
科学分野のプレスリリースは広報担当者だけで作成するわけではなく、科学者が深く関わっていることはあまり知られていない。
科学者が自ら全文の草稿を書くこともある。
何も知らない研究者が自分の仕事に集中しているときに、メディアが突然、彼らの発見を取り上げて大げさに報道するという筋書きは、決してよくあることではない。
(改行引用者)
イギリスのカーディフ大学の研究者を中心とした2014年の研究では、健康に関する科学研究のプレスリリース数百件を調べ、そこで説明されている研究と、最終的に発表されたニュース記事を照合しました。
その結果、プレスリリースには以下の3種類の誇大広告があることが分かりました。
(1)正当な根拠のないアドバイス
人々が行動を変えるべき方法(特定の種類の運動をすすめるなど)を提案するプレスリリースは、その研究結果が裏づけるよりも短絡的または直接的だった。
この傾向は検証の対象となったプレスリリースの40%に見られた。
(改行引用者)
(2)異種間の飛躍
マウスで得られた結果の90%は、最終的に人間には適用されない。
<略>
カーディフ大学の研究チームによると、動物実験の初期段階で得られた結果が人間にとって重要な意味を持つことを暗示したり、あるいは明確に主張したりして、プレスリリースを誇張する例はなくならない。
調査したプレスリリースの36%にこのような誇張が含まれていた。
一方、ヘルス部門の研究に関するニュース記事は、 その研究が人間を使っておこなわれたものではないという事実を、第8段落か第9段落のどこかに埋もれさせることもめずらしくない。
(改行引用者)
(3)分かったのは相関関係なのに因果関係が分かったかのように書く
==================
カーディフ大学の研究では33%のプレスリリースが因果関係を強調していた。
自分たちの観察の結果や相関的な結果が、あたかもランダム化された実験から得られたもので、何が原因かを明らかにできるかのように書かれていたのだ。
(改行引用者)
==================
これ、本書では「誇大広告」と表現されていますが、はっきり言うと、単なるウソでは。
その研究の結果のデータから言えないことを、あたかも言えるようにウソついてアドバイスしてるんですから。
動物実験から得られた結果の多くは人間には適用できないのに、そのまま人間にも適用できるかのように言うのもウソですよね。
そのデータからは、相関関係しか分からないのに、因果関係が分かったかのように言うのも、ウソですよね。
まとめると、科学者自身がプレスリリースでウソをつき、そのウソをメディアが報道し、そのウソニュース記事を、一般人が「健康に役立ついい情報だ」と思って読むことがけっこうあるわけです。

引用されるためのウソと誇張
この章では双六の「引用」について説明します。

世間は、権威ある学術誌を信用しますし、権威ある科学者を信用します。
しかし、そもそも、その「権威」は、何によって決まっているのでしょうか?
実は、論文も科学者も学術誌も、その権威は、被引用数に大きく影響されています。
たとえば、権威ある学者というのは、権威ある大学の教授とかです。
その権威ある大学の教授のポストに収まるのは、どんな科学者でしょうか?
アカデミックなポストへの採用や昇進で明示的に考慮されることが多いのがh指数です。
h指数は、「少なくともh回引用されている論文がh本以上ある」ことを意味します。
また、学術誌の権威は、インパクトファクターに大きく影響されます。
その学術誌に掲載された論文一本当たりの被引用数が多ければ多いほど、インパクトファクターは大きくなります。
具体的にはどうやって計算するかというと、たとえば、2024年のある学術誌のインパクトファクターは、2021年と2022年に掲載した論文が2023年に引用された回数の平均です。
この記事の執筆時点のインパクトファクターは、Natureが69.504、Scienceが63.832、Lancetが168.9です。
このため、学術誌の多くは、被引用数が大きくなりそうな論文を掲載する傾向にあります。
また、大学の権威は、そこに所属する科学者の論文が、どれだけ一流の学術誌に掲載されたかに大きく影響されます。
大学の権威もまた、論文の被引用数に大きく影響されているわけです。
このため、科学者の多くは、自分の論文の被引用回数を増やしたいという強い動機があります。
ブロガーやYouTuberが自分のコンテンツをネットでバズらせたいように、科学者も自分の論文を科学者コミュニティでバズらせたいわけです。
引用がSNSのバズに似ている点は、それだけではありません。
もちろん、論文を引用されるための最善の方法は、重要で画期的な結果を出すことだ。
研究者のなかには、自分の結果がまさにそのようなものであることを学術誌に(そして世界に)納得させるために、途方もない時間を費やす人もいる。
前章で説明したような「スピン」も、引用されやすくする方法だ。
ある研究では、有意な結果を示した論文は、NULLの結果を示した論文に比べて1.6倍多く引用されているが、著者が「結果は自分の仮説を支持する」と明確に結論づけている論文は2.7倍多く引用されている。
要するに、論文を引用されたいなら、よりポジティブな表現で書けばいいのだ----研究の結果について、洗練されていないが現実的で鋭い部分を、ことごとく言葉で研磨して滑らかにすることにはなるが。
(改行引用者)
まんま、ブロガーやYouTuberにも当てはまりそうな文章です。
Web記事や動画をバズらせるための最善の方法は、重要で画期的なコンテンツを作ることです。
ブロガーやYouTuberのなかには、自分のコンテンツがそのようなものであることをネットユーザーに納得させるために、途方もない時間を費やす人もいます。
話を盛ったり、誇張したりすることも、リツイートされやすくする方法です。
ポジティブなことを断定的に言っているツイート/ブログ記事/動画は、リツイート回数が何倍にもなりがちです。
論文にスピンが入り込む大きな原因の一つが、この「引用」なのです。
そもそもGoogleが世界一の検索エンジンになったきっかけは、「ページランク」というアルゴリズムを使って検索結果を表示したからですが、少なくとも初期は、被リンク数がページランクを決める重要な指標の一つでした。
これは、元々、被引用数が論文の評価を大きく左右するアカデミックな世界の慣習からヒントを得たと言われています。
そのGoogleの検索結果は、今や、SEOスパムにやられまくって汚染されてしまっているわけですが、似たようなことが、論文の被引用数でも起きているわけです。
この被引用数ゲームがもたらす影響を図にすると、以下のようになります。

そもそも、なぜ、メタアナリシスの結果が歪むかというと、出版バイアスのせいです。
なぜ、出版バイアスが起きるかというと、NULL論文が出版されにくいからです。
なぜ、NULL論文が出版されにくいかというと、それを学会誌が掲載したがらないし、大学も、NULL論文を実績としてあまり高く評価しないからです。
なぜ、学会誌がNULL論文を掲載したがらないかというと、それが引用されにくいからです。
なぜ、大学が、NULL論文を実績としてあまり高く評価しないかというと、それが引用されにくいからです。
なぜ、NULLの結果が出ると、研究者は、データをこねくり回して、無理矢理、それを統計的に有意の結果に見せがちなのかというと、NULL論文が学会誌にも大学にも評価されにくいからです。
なぜ、論文にもアブストラクトにもスピンが入りがちかというと、その方が、被引用数が多くなりがちだからです。
この図を見て分かるように、問題は、以下の2つから発生しています。
(1)アカデミックな世界全体が被引用を評価基準として重視しすぎ。
(2)NULL論文は引用されにくい。
で、これらの解決策としては、
まず、(1)の問題については、「引用」以外の評価基準(後述)も、もっと重要視することで緩和されます。
また、(2)のNULL論文が引用されにくい問題については、NULL論文の評価を高くするための仕掛けを入れることで緩和されます。
ちなみに、この本では、他にも、被引用数を増やすハッキングの手口を紹介しています。
●自分の過去の論文を過剰に引用する。
●学術誌の編集長が論説で自分の論文を過剰に引用する。
●学術誌の論説で、その学術誌のインパクトファクターを増やすことに貢献する論文の引用を過剰にやる。
●複数の学術誌で引用カルテルを結んで、相互に引用し合う。
●一つの論文にまとめられる内容を、複数の論文に分割して、相互に引用し合う。
これって、なんだか、どっかで見たことあるような……
相互に言及し合うブロガー/YouTuber/インフルエンサーや、同じメディアに掲載されるライター同士の相互言及って、まんまじゃないですか。
そう、ネットに似てるんですよ。
ネットに飛び交う情報が歪んでいるのと似たような原理で、学会に飛び交う情報も歪んでいるというわけです。
学会は、すごく客観的で学術的に正しい情報だけが飛び交う理知的な世界かと思いきや、けっこう、人間くさいところのようです。
バイアスの累積
これまで説明してきたようなバイアスは、累積していきます。
精神医学を研究するユムジェ・アナナ・デ・フリースらは、新薬の治験から最終的に世の中に出るまでに発生するすべてのステップを検証しました(2018年)。
その結果の詳細は長くなるので、本書に譲り、ここでは、その概要の図だけを引用するにとどめます。

これは、ある抗うつ剤に効果があるかを検証した実験が多数行われたときの様子です。
最初は、「効果があった」という結果と、「効果がなかった」という結果が、半々でした。(図の左端の状態)
〔出版バイアス〕 しかし、「効果が検出されなかった」という論文は半分くらいしか出版されないのに対し、「効果が検出された」という論文はほとんど全部出版されるので、「効果が検出された」という論文の方がずっと多くなります。
〔結果の切り替え〕 次に、統計的に有意にならなかった場合に、研究の焦点を変更したり、統計分析の手法を変更したりを、統計的に有意になるまで繰り返します。
すると、残った「効果が検出されなかった」という論文のうち、何割かが、統計的に有意な結果になります。
〔スピン〕 それでも統計的に有意にならなかったものの何割かが、スピンによって、まるで効果があったかのように印象づけるように表現が工夫されます。
〔引用のバイアス〕 最後に、「効果が検出されなかった」と報告する論文よりも、「効果が検出された」と報告する論文の方が引用されやすいので、「効果が検出されなかった」という論文の影響力は小さくなり、「効果が検出された」という論文の影響力は大きくなります。
Googleスカラーなどの論文検索においても、被引用数の多い論文の方が検索上位に来ますので、普通に論文検索すると、「効果が検出された」という論文ばかりが目につくようになります。
こうして、バイアスが累積していき、抗うつ剤の効果とその信頼性が、過大評価されてしまうのです。
YouTuber/ブロガー
YouTuber/ブロガーは、どれくらい信用できるのでしょうか?
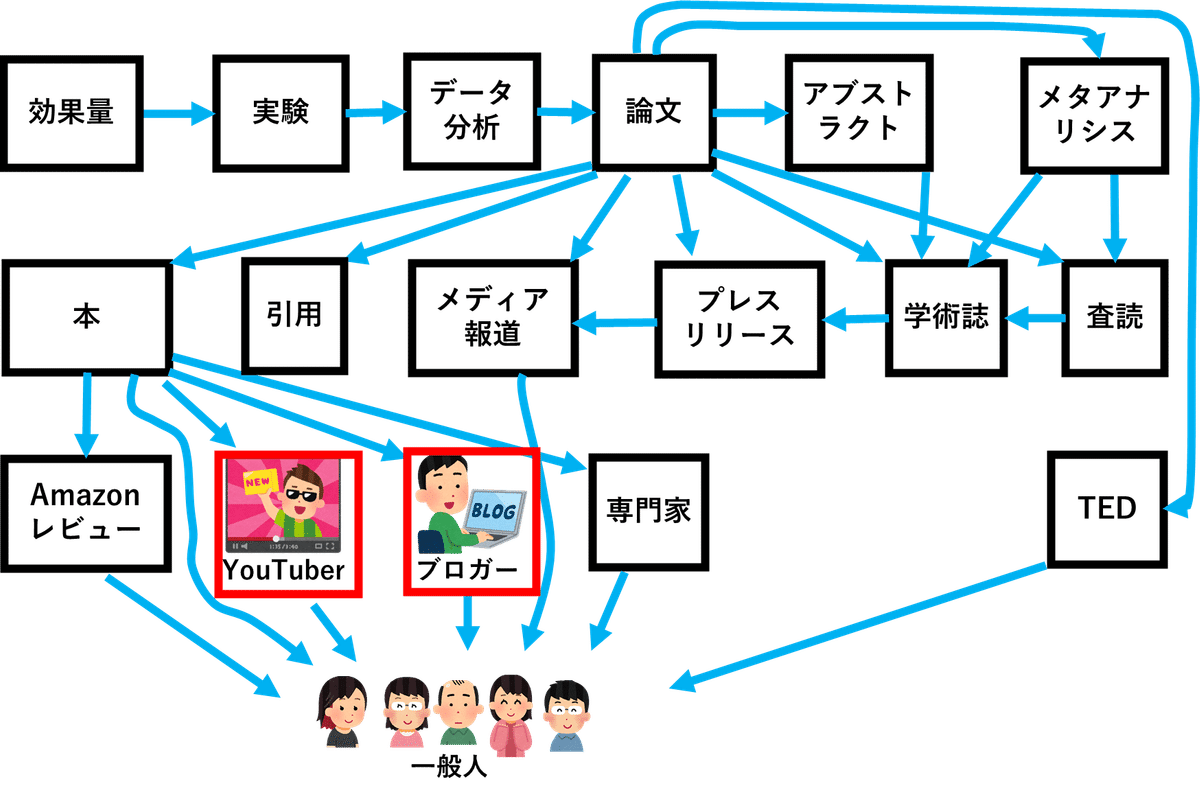
具体例がないとイメージがわきにくいと思うので、メンタリストDaiGo氏の『超効率勉強法』を例にして話します。
この本は、論文の出典を示しているところもありますが、出典を示していないところの方が多いです。
たとえば「テキサス大学が、かつてこんな実験をしました。」と書いてあるところがありますが、テキサス大学に所属するどの研究者が何年に出版した論文なのかが分からないので、論文を特定するのは難しいです。
一方、以下のような記述は、根拠となる論文の出典は記されていませんが、検証は可能です。
非効率勉強法5 集中学習
5つ目は、「集中学習」です。
これは、数時間のまとまった時間を取って、1つの科目や単元だけを徹底して学ぶ手法のこと。現在完了形を身につけたいなら現在完了形だけを、ベクトルを理解したいならべクトルだけを通しでやっていくテクニックで、一部の予備校などでも採用されているケースを見かけます。
ただし、検証には、手間がかかります。
たとえば、「数学だけ2時間勉強する」で学習効率が落ちなかったとしても、「行列だけ2時間勉強する」、「行列の回転だけ2時間勉強する」、「ある一つの行列の回転の問題だけ2時間勉強する」のいずれかで、学習効率が落ちる可能性があります。
もし、「ある一つの行列の回転の問題だけ2時間勉強する」が非効率だったとしても、「数学だけ2時間勉強する」の学習効率はとくに落ちない場合、DaiGo氏のアドバイス通りにすると、トータルの学習効率は下がります。
たとえば、数学を勉強していて、調子が出てきたとします。
そこで、DaiGo氏の本に書かれていたことを思いだし、数学の勉強を1時間やったところでいったん休憩したら、そのままゲームをしたり、SNSをやったりしているうちに、残りの1時間の勉強をしないケースが出てくるかもしれません。
実際に「数学だけ2時間勉強すると学習効率が落ちる」が科学的事実なら、まあ、それもしかたないかもしれません。
しかし、もし、「数学だけ徹底的に勉強する」の学習効率がとくに落ちないのなら、調子が出てきたときは、ノリと勢いに任せて、集中力の続く限り、半日でも丸一日でも飽きるまで数学をやりまくった方が、トータルの学習効率は上がります。
また、集中学習をしないということは、間隔を空けて学習をすることになりますが、その「間隔」の長さによって、学習効率はどのように異なるのでしょうか?
「間隔」は「1分」「5分」「30分」「1時間」、どのくらいあけると、学習効率はどのようになるのでしょうか?
「1分」あけても「1時間」あけても学習効率が変わらないなら、「間隔」は1分にした方が得です。
また、「間隔」の間、何をしているのかが問題です。
ぼーっとしているのと、ゲームをしているのと、読書をしてるのと、他の科目を勉強しているのとで、学習効率に違いはでるのでしょうか?
違いが出ないなら、他の科目を勉強していた方が、トータルの学習効率は上がります。
これについて、DaiGo氏は、この本で以下のように述べています。
なぜ集中学習は効果がないのでしょうか?
ここ数年の研究により、人間の脳は、状況に応じて2つのモードを切り替えていることがわかってきました。
・集中モード……目の前の情報に注意深く意識が向いている状態
・緩和モード……リラックスして思考がさまよっている状態
言うまでもなく、集中学習で使われるのは「集中モード」です。このとき、あなたの頭は分析に物事を考える 力がオンになり、目の前の情報を理解すべくフル回転しています。
ただし、「集中モード」だけで真の知識は身につきません。
ようは、「間隔」の間、リラックスしてる必要があるということです。
これが本当なら、「間隔」の間は、ぼーっとしているか、入浴するか、散歩でもしていた方がよさそうです。
また、英単語のような単純な「暗記」をする場合と、数学のような頭を使って「思考」する場合では違いが出るのでしょうか?
英語の発音はどうでしょうか? 英語の発音は、口、舌、喉の沢山の筋肉を連係動作する「運動」の学習です。
もし、「暗記」の場合には集中学習の効率が悪いとしても、「思考」や「運動」の集中学習の効率が悪くならないとしたら、数学や発音練習では、ノリと勢いが続く限り、集中学習した方が得、という話になります。
また、「教科書を読む」と「問題集を解く」の両方とも、集中学習の効率は悪いのでしょうか?
前者はインプットで、後者はアウトプットではないのでしょうか?
もし、インプットの集中学習が非効率で、アウトプットの集中学習が非効率でないとしたら、アウトプットをやっている場合は、集中学習をやってもいいということになります。
こんな感じの懸念点を、一つ一つ、論文のデータと突き合わせて検証してみたのですが、大変に手間のかかる作業でした。
それを、集中学習に限らず、学習効率に大きく影響すると考えられるさまざまな要因について、一通り検証したら、一年かかりました(その結果をまとめたのが拙著『最新研究からわかる 学習効率の高め方』です)。
この検証過程で分かったのは、『超効率勉強法』の主張は、間違っているというより、ズレていたり、雑だったりするということです。
ズレているというのは、学習効率を大きく左右するポイントじゃないところを、さも大きく学習効率に影響するかのように言っているということです。
それよりもはるかに重要なポイントは、別の場所にたくさんあるのに。
「雑」とはどういうことか?
たとえば、『超効率勉強法』の以下の記述が、その典型です。
非効率勉強法4 テキストの再読
4つ目は「テキストの再読」。これも、やってはいけない勉強法です。
ご存じのとおり、1つの教科書や参考書を何度も読み返すテクニックのことで、
これも、たくさんの論文のデータと突き合わせて検証してみました。
それで分かったのは、「テキストの再読」は、実験条件によって、効率的になる場合と非効率になる場合の両方があるということです。
つまり、効率的になるような条件下で、効率的になる方法でテキストの再読をすれば効率的だし、非効率になるような条件下で非効率になるような方法でやれば非効率になります。
場合によっては、「テキストの再読」をしない方が非効率になります。
どうして、彼は「テキストの再読」が「非効率勉強法」だと思ったのでしょうか?
(1)実験条件と実験手続きの吟味が不十分だから
実験条件と実験手続きの細部を十分に吟味していれば、「テキストの再読」が非効率になるのは、ある特定の実験条件と実験手続きの場合だけだと分かるはずです。
(2)過度な一般化をやっているから
ある特定の条件下でテキストの再読が非効率だったということを根拠に、「テキストの再読」一般が非効率だと思い込んでいます。
(3)吟味した論文の数が少なすぎるから
学習効率に関する他の論文のデータを吟味していれば、「テキストの再読」が非効率になるのは、ある特定の条件下だけだと、すぐに気がつくはずです。
(4)点と点をつなげていないから
彼がやってるのは、象の足だけ見て、「象とは柱のような生き物である!」と主張していることと同じです。
たくさんの論文のデータを突き合わせ、同じ現象をさまざまな角度から見ることではじめて、象の全体像が浮かび上がってきます。
(5)チェリー・ピッキングをしているから
自説に都合のいい論文だけ読んで、自説と矛盾する論文をスルーしています。
再現実験したらNULLの結果になりました、とか、効果はあったけど微弱でした、という論文が出回っていても、見なかったことにしてます。
自説と矛盾する論文と向き合わない限り、「象とは柱のような生き物である」という思い込みから抜け出すことはできません。
「壁みたいだぞ」「でかい牙があるぞ」などの論文も受け入れることではじめて、「どうも柱じゃないっぽいな……」と気がつき、象の全体像の理解が始まるのです。
誤解のないように言いますが、これ、全然、DaiGo氏個人の問題じゃないです。
YouTuber/ブロガー/ライター/作家が、科学実験を紹介しながら自説を主張する場合の多くが、こんな感じです。
間違っているというより、ズレていて、雑で、過度な一般化をやっていて、象の足だけ見ていて、針小棒大で、チェリー・ピッキングで、確証バイアスゾンビなのです。
『Science Fictions』を読んでいると、科学者の言ってることが、いまいち信用ならない気がしてきますが、YouTuber/ブロガーの主張を論文のデータと突き合わせて検証すると、彼等よりも科学者の方がはるかに信用できるということがよく分かります。
比較すること自体が科学者に失礼、というレベルです。
事前登録
ダメな論文が蔓延しないように、科学者や政府は、どのような努力をしているのでしょうか?
最も効果的な対策の一つが、事前登録です。
これは、実験計画を事前に登録してから、実験を始める方法です。
これをやると、統計検定をやって、統計的に有意にならなかった場合に、統計手法を変えたり、データを分割したりして、統計的に有意になるパターンを見つけ出すようなことをやって論文を書いたら、バレます。
「ん? 実験計画では統計検定Aをやるって書いてあったのに、この論文では統計検定Cをやって有意になったって書いてるよね。だとすると、そのp値は、その値が示すほどの信頼性はなさそうだな」と分かってしまうのです。
あるいは「実験計画では、身長の違いによって、効果が出たり出なかったりするなんて仮説を立てていなかったのに、論文では、はじめからその仮説を立てて検証実験を行ったかのように書いてある。この論文の主張は、話半分に聞いておいた方が良さそうだな」と分かってしまいます。
以下、『Science Fictions』から引用します。
事前登録は、アメリカでは2000年から政府の資金援助を受ける臨床試験に義務づけられており、2005年以降は大半の医学雑誌で論文掲載の前提条件になっている。
登録にあたり、研究者はデータを収集する前に、 どのようなことをする計画なのかを詳細に記した文書にタイムスタンプをつけてオンラインで公開する。
(改行引用者)
事前登録の威力は絶大です。
心臓病予防に関する大規模な臨床試験の研究は、事前登録の影響を端的に語っている。
<略>
事前登録が必要になる前の臨床試験の成功率は57%だったが、その後は8%まで激減している。
繰り返しになるが、事前登録が必要になる前は、心臓病に「効果があると思われる」多くの研究がおこなわれ、大成功を収めていたのだ。
やがて真実が明らかになった。
これらの研究で試された薬や栄養補助食品は、私たちが信じさせられていたほどに有用ではまったくなかったのだ。
事前登録が義務づけられる前と後でどう変わったかのグラフを、本書から引用します。

事前登録が義務づけられた2000年を境に、NULL論文(統計的に有意な結果の出なかった論文)が激増し、統計的に有意の結果の出た論文が少なくなったことが分かります。
逆に言うと、事前登録が義務づけられていなかった時代は、いかにいい加減な論文が蔓延していたかが、よく分かります。
恐ろしいですね。
古い論文には、くれぐれも注意しましょう。
オープンサイエンス
さらに一歩進んで、実験の各ステップのデータを、サーバに登録しておくという方法があります。
たとえば、実験を行って、被験者からデータを取ったら、それをすぐにアップロードするのです(アップロード時にタイムスタンプが付きます)。
こうすると、査読者は、論文のデータが怪しいと思ったら、生データにアクセスし、生データに不正な変更が加えられていないか、監査することができます。
また、研究のプロセスが全部ログられていると、それらを改ざんして論文を書くのは、かなり困難になります。
さらに、プログラムで自動的にデータの間違いや不正をチェックできるようにする試みも増えてきています。
人力でやるより、はるかに効率よく不正を検出できるようになります。
サーバに登録したデータに誰でもアクセスできるようにすることで、その論文を不審に思った人は誰でも、その論文の生データにアクセスして、はたして、その論文が、そのデータから言えることを主張しているのかどうか、検証することができるようになります。
また、学術誌に掲載される前の論文を、サーバで公開し、誰でも自由に閲覧できる仕組みも普及してきました。
新型コロナ騒動のときに大活躍したプレプリントサーバーが、それです。
査読者だけでなく、論文を検証した人は誰でも、論文にコメントをつけられるような仕組みも導入されてきているようです。
プレプリントサーバーには、以下のような利点があると考えられています。
まず、学術誌には、NULL論文を掲載したがらないというバイアスがありますが、プレプリントサーバーには、それはありません。
NULL論文だからという理由で、プレプリントサーバーで公開できないという制限はないからです。
このため、プレプリントサーバーは、出版バイアス問題を緩和する効果があると考えられています。
また、ありもしない効果を検出して論文にしてしまう確率を下げることが期待されます。
なぜなら、研究者たちが、データをこねくり回して、無理矢理統計的に有意な結果を出そうとするのは、そうしないと、学術誌に掲載してもらえず、論文を出版できないからです。
プレプリントサーバーであれば、どんな結果であっても公開できるので、無理矢理統計的に有意な結果を出さなくてはならないというプレッシャーが下がることが期待できます。
論文の本文やアブストラクトに入り込むスピンも、同様の理由で、減ることが期待されます。
さらに、プレプリントサーバーは、公開までのスピードが圧倒的に速いです。
従来なら、査読だの編集だのの手続きが必要なので、出版までに数ヶ月~数年かかるところを、プレプリントサーバーなら、すべてをすっとばして、すぐに公開できます。
だから、新型コロナのときに大活躍したのです。
もちろん、そのデメリットもあって、一流の学術誌にはまず掲載されることのないレベルのあちゃーな論文も公開されるので、プレプリントサーバーに公開された論文を読むときは、その点は注意する必要があります。
要するに、研究の計画、各ステップのログ、データ、論文、コメントを、全世界にどんどん無料公開していくのです。
それによって、不正、バイアス、過失、誇張を減らしていくわけです。
この潮流は、「オープンサイエンス」と呼ばれています。
このオープンサイエンス運動は、研究資金の提供者も後押ししています。
近年は研究資金の提供者が、研究がオープンアクセスで公開されることを要求するようになった。
研究資金提供組織の協会であるサイエンス・ヨーロッパの「プランS」は、メンバーが資金提供するすべての研究について、完全なオープンアクセスの学術誌に掲載することを義務づけている。
この野心的な戦略はヨーロッパ16カ国の政府系機関のほか、ウェルカム・トラストやビル&メリンダ・ゲイツ財団など主要な研究資金提供組織が採用している。
プランSの規定では、 サイエンス・ヨーロッパの助成金を得た科学者は、完全にオープンアクセスではない学術誌に論文を投稿することはできない。
ただし、現段階で『サイエンス』や『ネイチャー』を含む学術誌全体の85%が、完全なオープンアクセスを認めていない。
(改行太字引用者)
実は、学術誌が、オープンサイエンス運動を阻害しているんです。
なぜかというと、論文が誰でも無料でダウンロードできるようになったら、彼等の売り上げが減るからです。
こうした購読料がいかに「法外」なものかは、あらためて考える意味がある。
ノーベル賞を受賞した生物学者で学術誌の編集者も務めるランディ・シェクマンは2019年に、カリフオルニア大学が非営利組織のナショナル・アカデミー・オブ・サイエンスと営利企業のエルゼヴィアという2つの出版社に払った購読料を比較した。
科学論文を1本ダウンロードする料金は、ナショナル・アカデミー・オブ・サイエンスの0.04ドルに対してエルゼヴィアが1.06ドルと、実に26倍を超えている。
世界中の研究者がエルゼヴィアに数百万ドルを支払っており、その額は営利の出版社全体で数十億ドルにのぼる。
これだけの金を払って、どんな特別サービスがあるのだろうか。
少なくともナショナル・アカデミー・オブ・サイエンスが発行している学術誌は、エルゼヴィアの学術誌と基本的に同じか、それ以上のサービスを提供している。
学術誌の顧客の多くは大学や研究所などの公的機関です。
つまり、学術誌の売り上げのかなりの割合が、我々一般人の払った税金から来ています。
また、論文を書く研究者の生活費も研究費も税金でまかなわれています。
彼らは、論文の著者に印税も払いません。
つまり、学術誌は、税金を使って書かれた論文を、税金で買ってもらって、大きな利益を出している機関です。
その学術誌が、オープンサイエンスを阻害し、出版バイアスなどの問題の解決を阻害しているわけです。
なので、納税者である我々は、二重の意味で、学術誌から被害を受けています。
第一に、税金を不当に搾取されているという意味で。
第二に、オープンサイエンスを阻害し、科学研究をゆがめ、我々の健康や人生に害を与えているという意味で。
なので、納税者である我々一般人こそが、この問題にもっと関心を向け、オープンサイエンスを推進し、学術誌が不当な利益を上げるのをやめさせるように圧力をかけていく必要があるのではないでしょうか。
ちなみに、「論文一本あたり1.06ドル」というのは、大学とかが学術誌を購読している場合の平均単価です。
われわれ一般人が、論文を買おうとすると、一本あたり5千円とかを払わなければなりません。
私は、論文を買うたびに、とても嫌な気分になります。
一般人がやるべき対策
じゃあ、我々一般人は、これまで見てきた問題について、どのような対策をすればいいのでしょうか?

誰でも簡単に実行できて効果抜群の対策が2つあります。
透明性
一つ目は、「透明性」です。
透明性を基準に行動すれば、騙されるリスクは劇的に下がります。
たとえば、「事前登録」は、透明性を高める仕組みです。
事前に、そんな実験計画を立てていたかを透明化しているからです。
今後、論文は、「事前登録」された実験なのかどうかが、一目で分かるようになっていくと思います。
論文のタイトルの末尾に事前登録マークがつくとか。
また、YouTuber/ブロガーが、論文を根拠に何か言う場合、根拠としている論文が事前登録論文なのかを表示するのが当たり前になっていくと思います。
事前登録しているかどうかで、信頼性が大きく違うからです。
我々一般人は、それが事前登録された論文なのかどうか、確認することで、ある程度の信頼性を担保できます。
この透明性の原則は、YouTuber/ブロガー/本にも当てはまります。
YouTuber/ブロガー/本の透明性とは、根拠としている論文の出典を明らかにすることです。
実際に、YouTuber/ブロガー/本の主張の裏取り調査をしてみると、透明性が低いほど腐敗していることが、露骨に分かります。
裏取り調査とは、関連する論文の実験条件/実験手続き/データを吟味して、突き合わせ、YouTuber/ブロガーの主張の妥当性を検証することです。
腐敗とは、「テキストの再読は、非効率な学習法である」みたいな、間違っているというより、ズレていて、雑で、過度な一般化をやっていて、象の足だけ見ていて、チェリー・ピッキングで、確証バイアスゾンビな主張のことです。
なんで、根拠としている論文の出典をあかさないと、腐敗するのでしょうか?
科学者でも、一般人でも、不透明なほど、インチキをやる人間が増えるからです。
事前登録を義務化したら、心臓病に関する怪しい論文が激減したのと、原理は同じです。
事前登録しなければ、データをこねくり回して、有意な結果が出た後に、「最初から、こういう仮説を検証しようとしてたんだよ」とウソをつくことができます。
だから、事前登録しないと、インチキ論文が横行しました。
バレなきゃウソをつく人は、一般に考えられているよりも、ずっと多いんです。
YouTuber/ブロガーも同じです。
論文の出典を隠しておけば、ウソをついていても、なかなかバレません。
裏取りをする手間が爆上がりするので、ほとんどの人は、コスト的に、その裏取りができないからです。
根拠としている論文を隠しておけば、根拠としている論文から言えないことを言い放題なので、興味深いこと、面白いこと、驚くようなこと、読者を気持ちよくさせるようなこと、バズるようなことを、いくらでもでっち上げられます。
盛って盛って盛りまくることができるのです。
というか、隠しているのではなく、そもそも、そんな論文が存在してない可能性もあります。
「ある実験では」「○○大学の研究では」などと、いかにも科学的根拠があるように匂わせながら、実際には、根拠のない話をねつ造するというわけです。
インチキをやる動機も、科学者とYouTuber/ブロガーは、よく似ています。
科学者は、科学者として評価を高めるために、インチキをやって統計的に有意な結果を出し、論文本文にもアブストラクトにもプレスリリースにもスピンを入れます。
YouTuber/ブロガーは、登録者数を増やす、Amazonレビューの☆の評価を高くする、ブログの読者を増やすという目的のために、話を盛るのです。
実は、論文の出典を明記するより、さらにもっと優れた判定基準があります。
動画/ブログ記事/本のなかで、根拠となる論文の出典に加え、実験条件と実験手続きを説明しているかどうかです。
これをやった場合、誤魔化しが効かなくなります。
なぜなら、読者は、根拠としている論文を読まなくても、それが、根拠としている論文から言える主張なのかどうかが、分かってしまうからです。
実は、ここで、奇妙なパラドックスが生まれます。
「根拠としている論文から言えないことを言っている」ということが読者にバレる頻度が高いYouTuber/ブロガー/本の方が信用できるというパラドックスです。
出典を隠す人は、「根拠としている論文から言えないことを言っている」ことがバレにくいです。だから、信頼され、Amazonで大勢の人に高く評価されるのです。
一方、出典を明らかにし、実験条件と実験手続きを説明している人は、容易にインチキがバレるので、ちょっと口が滑っただけでもそれがバレてしまい、「こいつは時々インチキを言うな」と思われてしまうと言うわけです。
スゴ本さんの『ミスを責めるとミスが増え、自己正当化がミスを再発する『失敗の科学』』という記事では、ミスを責めると、ミスを隠すようになって、逆にミスが増えるという事例を紹介しています。
「根拠としている論文から言えないことを言っている」を責めると、それと同じようなメカニズムが働きます。
出典を明らかにし、実験条件と実験手続きを説明している人に対して、「根拠としている論文から言えないことを言っている」と責めると、その人は、実験条件と実験手続きを説明しなくなり、出典も隠すようになりがちです。
興味深いことに、最初は出典を明らかにしていたYouTuberが、「根拠としている論文から言えないことを言っている」と叩かれまくったために、出典を隠すようになったケースがあります。
その人の昔の本には、出典がけっこうあるのですが、最近の本では出典が書かれなくなりました。
つまり、読者の多くは、YouTuber/ブロガー/作家に、逆インセンティブを与えているのです。
出典を隠してインチキを言うほど、信用できて、面白いと、高く持ち上げます。
出典を明示して実験条件と実験手続きを明示するほど、「根拠としている論文から言えないことを言っている」と叩かれるリスクが上がります。
また、根拠としている論文から言える範囲のことしか言えなくなるために、面白くないのでAmazonレビューの☆評価も下げるわけです。
我々一般人が、本来、やるべきは、この逆インセンティブをやめ、正しいインセンティブを、YouTuber/ブロガー/作家に与えることです。
出典を明示せずに、「ある実験では……」「○○大学の研究では……」みたいに科学的根拠があるようなことを主張する人の話は、話半分……いや、話1/10ぐらいで聞いておいた方がいいです。
根拠としている論文の出典を明示していたら、それだけで、評価を上げた方がいいです。
さらに、実験条件と実験手続きを説明していたら、それだけで、大きく加点した方がいいです。
そして、根拠としている論文の出典を明示し、かつ、実験条件と実験手続きをちゃんと説明していたら、「根拠としている論文から言えないことを言っている」ことが明らかな場合でも、それは大目に見るべきです。
なぜなら、ウソであることがはっきりしているウソには、大して害がないからです。
出典と実験条件と実験手続きが書いてある場合、それを根拠にそれからは言えない主張をすれば、すぐにそれは読者に分かります。
実験条件と実験手続きを読んで、「コイツは根拠としている論文から言えないことを言っている」と鬼の首を取ったように叩いて騒ぐことは、世の中を悪くします。
「根拠としている論文から言えないことを言っているけど、出典と実験条件と実験手続きをちゃんと説明しているからエライ」と褒めた方が、はるかに世の中は良くなります。
そして、「根拠としている論文の出典が書いてないから怪しい」「実験条件と実験手続きが書いてないから怪しい」ということは、積極的に言っていった方が、世の中は良くなるのです。
出典を表示しない記述が多い本に対しては、Amazonレビューでも「出典が書かれていないものが多いので、信憑性が怪しい」というコメントをつけて、☆の評価も下げるべきです。
また、それは、単に世の中を良くするというだけでなく、自分個人の得でもあります。
「出典・実験条件・実験手続き・実験データを明らかにしているものほど信用度が高い」という判断基準を持っていれば、ズレていて、雑で、過度な一般化をやっていて、象の足だけ見ていて、チェリー・ピッキングで、確証バイアスゾンビな主張に騙される頻度を大きく減らすことができるのですから。
実験条件
二つ目の対策は、「実験条件を少し変えたらどうなるか?」を吟味してみることです。
たとえば、以前、「○○というコンテンツが超大ヒットしたのは偶然である」という主張の根拠にダンカン・ワッツ博士らの行った「ミュージックラボ」の実験(2006年)を紹介した方がいらっしゃいました。
その実験の概要は、以下のようになります:
実験はWebサイトで行われました。
1万4341人の被験者が参加したその実験では、未知のバンドの未知の曲が48曲サーバに登録されています。
そのサイトにやってきた被験者は、到着しだい、2つのグループのいずれかに、ランダムに振り分けられました。
どちらのグループでも、被験者は、それらの曲を聴いて、五段階評価(☆1(嫌い)~☆5(好き))し、望むならダウンロードするように依頼されました。
2つのグループの違いは、曲名の横にダウンロード数が表示されるかどうかです。
ダウンロード数表示ありの被験者グループは、さらに8つのグループに分けられました。
曲名の横に表示されているダウンロード数は、それまでに到着した同じグループの被験者によってダウンロードされた数です。

実験は、二回行われました。
実験1では、ランキングなし。曲の並び順は、被験者ごとにランダムです。
実験2では、ランキングあり。ダウンロード数が表示されるグループでは、ダウンロード数の多い順に曲が縦に並んでいます。
結果はどうなったか?
ダウンロード数表示ありの8つのグループで、どの曲がヒットしたかは大きく異なりました。
もちろん、質がすごく良い曲は多くのグループで上位になり、質がすごく悪い曲は多くのグループで下位になりました。
(質の良し悪しは、ダウンロード数非表示のグループの評価で決めている)
でも、それ以外の大多数の曲は、ヒットするかどうかは、ほぼランダムだったのです。
なぜこうなったのでしょうか?
「被験者は、ダウンロード数が多い曲やランキング上位の曲をダウンロードする傾向にあった」という点が鍵です。
そのため、初期に、偶然、ダウンロード数が多くなった曲があると、その曲はますますダウンロード数が増え、雪だるま式にダウンロードが増えて、それがヒット曲になったのです。
つまり、「初期に、偶然、小さな偏りができる → ダウンロード数表示やランキングによってその偏りが拡大する → ヒットが生まれる」という作用機序で、主に偶然によって、ヒットするかどうかが決まったのです。

この結果を見ると「コンテンツがヒットするのは偶然である」と言えるような気がします。
しかし、もし、これが「未知のバンドの未知の曲が48曲」ではなく、「有名バンドの未発表曲4つ + 有名バンドの未発表曲だと偽った無名バンドの曲4つ + 未知のバンドの曲40曲」で、「作者名表示、非表示」×「ダウンロード数表示、非表示」×「ランキング表示、非表示」のマトリクスで被験者がグループ分けされていたら?
「初期に、知名度の違いによって、小さな偏りができる → ダウンロード数表示とランキングによってその偏りが拡大する → ヒットが生まれる」
という作用機序で、主に知名度の違いによって、ヒットするかどうかが決まっていたかもしれません。

また、「種の飛躍」の問題もあります。
「マウスで得られた結果の90%は、最終的に人間には適用されない」のと同じ話で、曲以外の種類のコンテンツを使ったら、別の実験結果になった可能性も考えられます。
たとえば、Web小説だと、「初期の小さな偏り」に影響を与えられそうなコントロール可能な変数は、タイトル、アイキャッチ画像、ランディングページの作品概要、小説冒頭の挿絵、小説冒頭の数十行、フォロワー数、作者のブランド、作品コンセプト、キャラ、ストーリー、演出、クライマックス、エンディング、文章の上手さ、などなど、たくさんあります。
それら全てをあわせても、「初期の小さな偏り」に与える影響は「偶然のゆらぎ」よりも小さいでしょうか?
あるいは、マンガ、アニメ、TVドラマ、映画だったら?
そもそも、あなたは、なぜ、今、この文章を読んでいるのでしょうか?
私が18年間ブログを書き続けた結果、いろんなものが溜まった → それがこの記事の「初期の小さな偏り」に影響した → その偏りをXのリツイート数表示といいね数表示が拡大 → この記事が拡散 → あなたのところに届いた
からではないでしょうか。
この記事の「初期の小さな偏り」に影響を与えた要因には、「偶然のゆらぎ」もあるでしょうが、「18年間の積み重ね」などの必然的な要因を全て足し合わせたものの方が大きかったのではないでしょうか。
あの実験で「初期の小さな偏り」が主に偶然で決まったのは、単に、「偶然のゆらぎ」以外の要因が強く出ないように実験条件を設定したからにすぎないのではないでしょうか?
実験条件は、実験者が恣意的に決めるものです。「初期の小さな偏り」が主に偶然で決まるような実験条件にすれば主に偶然で決まるし、主に必然で決まるようにすれば主に必然で決まる、ただそれだけのことかもしれません。

偶然によって決まるかどうかは、少しずつ実験条件の異なるたくさんの実験をやってはじめてわかることであって、この実験一つだけでは、象の足の一つに触った程度しかないのです。
そう考えると、ミュージックラボの実験は「○○というコンテンツが超大ヒットしたのは偶然である」という主張の根拠として使えるようなものじゃないことが分かります。
これは、その主張が正しいかどうかとは別の話です。仮にその主張が正しかったとしても、その実験は、その主張の根拠としては使えないのです。
なので、「○○というコンテンツが超大ヒットしたのは偶然である」は、「根拠としている論文からは言えない主張」なのです。
以上のような吟味が、論文を読めない人でも可能だという点が、非常に重要です。
動画/ブログ記事の中に実験条件・実験手続きが書かれていれば、「実験条件を少し変えたらどうなるか?」という疑問を持つだけで、「根拠としている実験から言えることを主張しているか?」を吟味することができるのです。
「透明性」の価値がいかに高いかが分かります。
実験を根拠に「テキストの再読は非効率」という主張をする人がいた場合も、同様です。
もし、動画/ブログ記事/本の中に実験条件・実験手続きが書かれていれば、「実験条件を少し変えたら、テキストの再読は非効率になっただろうか?」と考えるだけで、「テキストの再読は非効率」という雑な主張には騙されなくなります。
科学的根拠があることをウリにする人たちが、出典を隠し、実験条件・実験手続きも説明しないことが多い理由の一つが、これなのです。
まとめ

まとめると、以下の2つの簡単な対策で、インチキ論文やインチキYouTuber/ブロガー/作家に騙されにくくなります。
〔透明性〕 透明度の低い研究は話1/10に聞く。
〔実験条件〕 実験条件を少し変えたらどうなるか?を吟味する。
以上です。
こんな長文を、ここまで読んでいただき、ありがとうございました。
この記事の作者(ふろむだ)のツイッターはこちら。
この記事を面白いと思った人が面白いと思いそうな同じ作者の記事
エビングハウスの忘却曲線の実験を根拠にした勉強法がインチキである理由を丁寧に説明する
※この記事は、文章力クラブのみなさんにレビューしていただき、ご指摘・改良案・アイデア等を取り込んで書かれたものです。
この記事が気に入ったらサポートをしてみませんか?