ビッグデータの活用実践法(コンセプトを創る)

ビッグデータの活用法の一つに
テキストマイニングを使ってアウトプット
する方法があります。
なぜなら、SNSやメール、口コミサイトなど、
企業と顧客をつなぐ非対話型の
コミュニケーションが増加しているからです。
よって、テキストマイニングによる
データ解析は欠かせない技術となっています。
しかしながら、横文字が多くて拒絶してしまいますので
少し分解した定義から掘り下げていきます。
ビッグデータとは、3Vとも言われて
・データ量(Volume)
・発生頻度(Velocity)
・多様性(Variety)
様々な形の、様々な性質の、様々な種類のデータを指します。
テキストマイニングとは、
文字列データを対象としたデータマイニングで、
大量のテキスト情報の中から様々な
有益な情報を発掘することができる技術です。
大量データの中から有益なテキスト情報を
抽出するために利用されます。
まとめると、
様々な形の、様々な性質の、様々な種類のデータから
有益な情報を発掘することができる技術
と言えます。
また、テキストマイニングでは、
対象ユーザーに合わせて、
適した分析対象を選ぶことも大切です。
ポイントは、
Twitterだけではなく、他のSNSなど
ターゲットにあったツールから柔軟に
選択できることを忘れないでください。
実は、データ分析は、魔法の杖ではありません。
ポイントとして2つあります。
1点目
目的は明確にする
2点目
仮説を立案する
ここを無視すると、データから何かが
見えてくると勘違いをします。
仮説を立案し、目的を明確にしないと
データ分析は全く意味をなしません。
テキストデータといってもさまざまですが、
・ソーシャルメディア(Twitter、Instagram、ブログ、Facebookなど)
・顧客アンケート
・メール
・インターネット掲示板
・口コミサイト
などのお客様の声が
主な分析対象となります。
たとえばTwitterは、非常に即時性が高いSNSです。
ユーザーが思ったことや感じたことをすぐにつぶやく
傾向があるので、本音に近い生の声を拾うことができます。
今回は、大学の講座でも教えている
方法をご紹介したいと思います。
テキストマイニングで取り扱う文字列のデータは、
定性データの代表的なものです。
定性データは、数値化することができないため、
UVP構文に当てはめて現場で使用します。
※UVP構文の説明はここでは割愛します。
テキストマイニングとして分析できる
ことは、
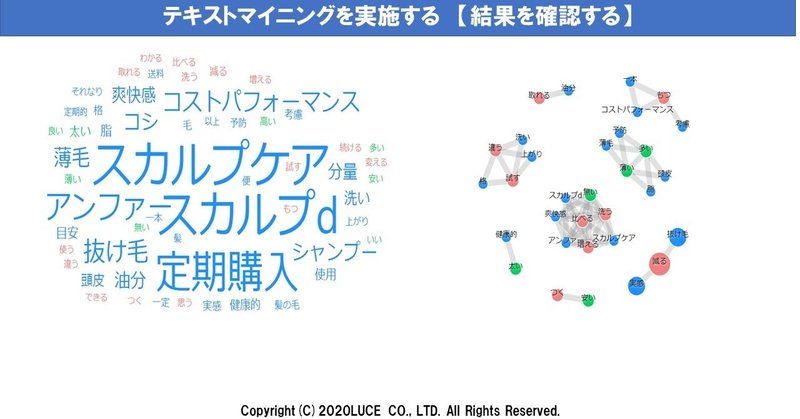
・ワードクラウド
・単語出現頻度
・共起キーワード
・2次元マップ
・係り受け解析
・階層的クラスタリング
などがあります。
更に
・評価や感情分析(センチメント分析)
・対応分析(コレスポンデンス分析)
も可能です。
大学生にもわかるテキストの方法ですが、
ワードクラウドと共起キーワード
の2つを使います。
ワードクラウドとは、
文章中に出現する単語の頻出度を表にしています。
単語ごとに表示されている「スコア」の大きさは、
与えられた文書の中でその単語が
どれだけ特徴的であるかを表しています。
ポイントは、形容詞や動詞です。
学生には、擬態語・擬音語をピックアップ
するように指導をしています。
共起キーワードとは、
文章中に出現する単語の出現パターンが
似たものを線で関係性を描きます。
1)自分のSNSか楽天市場で選択する(楽天市場で展開する)
2)800件以上あるレビューコメントのジャンル(商品)を選択する
・(★1点から★★★★★5点)
3)10件、お客様の声を全てワードにコピペ(コピー&ペースト)する
・良いコメントでも悪いコメントでもOKです。
4)共起キーワード(グループ単位)をUVP構文に自由に組み合わせる
・●●にとって【ターゲット】
・▲▲になるための【メリット&ベネフィット】
・××のサービス【問題解決】
を埋めます。
これが完成するとお客様の声でコンセプトが出来上がります。
スカルプDの事例で
UVPの構文を組み立てる
(例)
抜け毛を減らしたいことを実感したい20代にとって
頭皮の油分が取れるための
洗うことで爽快感がわかるサービス
になります。
インターネットを活用して自分の商品・サービスを売りたい! でもなかなか売れずにモヤモヤしている問題を解決する アドバイスをしています。 https://www.youtube.com/channel/UCxrQWY0HlXqFcOfe02_uztg/videos