生成系AIは機械翻訳技術の発展系

どうも僕はこの種の歴史ネタの記事を書き始めると、際限なく書き連ねてしまうようで…予定より長くなってしまった記事を4つに分けることにしました。やはりブログはコンパクトにしないと読んで貰えないですからね😆
前回「現在のAIブームは第1次AIブームとよく似ている」とか「技術的には格段に進歩したのに世間からのリアクションはあまり変わらない」とお話しました。もう一言だけ言い添えるとしたら「機械翻訳のために開発した技術をチャットボットに応用すると急に世間の関心が集まってくる」と言えるのかも知れません。
実際「AIと対話するアプリケーション」であるチャットボットは、今でも情報系の専門家以外の方々にもその効果が広くアピールできる決定的なソリューションなのです。特に第1次AIブームの1960年代には、スマホはおろか、まだパソコンすら無かったので「コンピュータと対話できるアプリケーション」ELIZAの出現はそれこそ革命的な出来事で、当時の男性向け月刊誌『PLAY BOY』の特集記事として取り上げられたくらいの大ブームを引き起こしました。そのおかげもあって同じ1966年に発表されたALPACの最終勧告…それまでの10年間で実現がもっとも期待されていた機械翻訳の研究を全否定する内容だったのですが…によるAIへのネガティブなイメージを完全に払拭してしまい、ブームをさらに過熱させる「事件」となりました。このあたりの経緯は今年のChatGPTのブームを彷彿させますよね?
そのChatGPTのエンジンである「生成系AI」という技術、実は中身は機械翻訳技術の発展系なんですね。そのあたりを説明するため、前回の年表に機械翻訳のトピックを追加してみました。
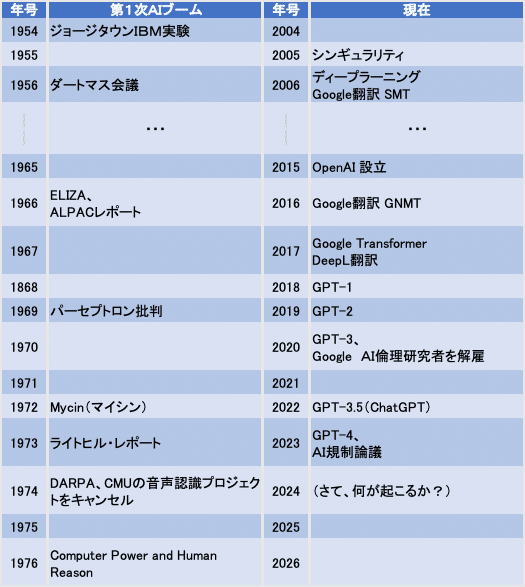
そもそも機械翻訳の研究開発は、まだ「AI」という言葉がなかった1954年から始まっていたのです。その12年後、ダートマス会議からは10年後の1966年、機械翻訳の実用性を評価する目的で設立された ALPAC(Automatic Language Processing Advisory Committee)という諮問委員会から懐疑論が報告され、機械翻訳の研究開発は冬の時代に突入してしまいました。
その後の機械翻訳の研究には紆余曲折があったのですが…
現在の機械翻訳は SMT(Statistical Machine Translation:統計的機械翻訳)が基礎になっているそうです。例えば、英語から日本語だと「have 〜」は「〜を持っている」と翻訳しますが、「have to 〜」だと「〜をしなければならない」と翻訳しますよね?英語のテスト勉強での丸暗記を思い出される方も多いかと思いますが、このような言葉の並びのパターンを予めルールとして打ち込んでおいて、翻訳をする際にその発生確率を計算しながら正しい訳文を決める方法を使います。2006年に登場したGoogle翻訳の最初のバージョンはこの方法を採用しています。その10年後の2016年、Google翻訳はGMNT(Google Neural Machine Translation)に変わります。このバージョンでは人手と時間がかかるルールの打ち込みを止めて、コンピュータを使って人間が書いた大量の文書から言葉の並びのパターンのルールを取り出す、つまり機械学習のモデルへと置き換える変更を行いました。Google翻訳の精度が急激に向上した事を覚えている方もいらしゃるのではないでしょうか?ルールを維持する労力(人手と時間)を大幅に削減できて、なおかつ翻訳の精度も大きく向上できる…つまり第1次AIブームの時とは対照的に、今世紀の機械翻訳は10年間で技術的に大きくステップアップしたのです。
ですが、GNMTを採用したGoogle翻訳の印象って案外薄くないですか?今年の年始以来のChatGPTを巡る大騒ぎには程遠い感じ。ChatGPTも(人間が書いた)膨大な文書を取り込んで、次に来る確率の高い単語を予測しているだけで、GNMTも流暢な自然言語で応答してくれるます。文書量が相対的に少ない日本語の精度がいささか低いのも同じ。
なのに…
相手がチャットボットだと「とうとうAIは知性を獲得した」だとか「質問に何でも答えてくれるから、宿題も相談できそう」とか「やはりシンギュラリティは近い」とか…挙句の果てには、法規制の大真面目な議論がヒートアップする始末。長年、機械翻訳に携わって来た研究者やエンジニアからは「扱いがだいぶん違いませんか?」とクレームが漏れて来そう😀
50年間を経ても尚、チャットボットの決定的ソリューションぶりは健在であることが確認できる8ヶ月間でした。
おそらくOpenAIのCEOのサム・アルトマンは ELIZA が第1次AIブームで最も普及したAIアプリケーションであったことを、よくわかってたんでしょうね。2015年に設立したばかりの同社は、この分野では明らかに後発ですからね。彼らがGoogleに対して一発逆転を狙ったのが ChatGPT だった…と解釈するのが自然だと僕は思います。
一方、GMNT を開発し(おそらくその基盤技術である)Transformer まで論文を公表しておきながら、コード・レッドに追い込まれた Google は何をやっていたのでしょうか?「おそらくこの事件が関係あるのでは…」と僕は考えています。解雇された研究者たちがどこまで知っていた(あるいは知っている)のかはわかりませんが、彼女らの解雇に踏み切った Google には相応の事情があったことだけは想像できます。「ひょっとしたら、彼らもまた、第1次AIブーム終焉の顛末をなぞっているのではないか?」などと想像力を逞しくしているところです。(つづく)
#AI
#ChatGPT
#ELIZA
#機械翻訳
#ALPAC
#SMT
#GNMT
#Transformer
#生成系AI
#技術史
この記事が気に入ったらサポートをしてみませんか?