
【SRE:サイト信頼性エンジニア】最初に理解したいことと最初のアクション

はじめに
現在参画しているプロジェクトでSREとしての職務を求められました。
ただ、SREについて調べてみると「信頼性」「自動化」などの言葉が並べられいてはいますが、いまいちピンときませんでした。
そこで今回はSREとして高めるべき信頼性の概要と、自動化が語られる背景、また、最初に取るべきアクションに焦点を当てて明確化しました。
SREの定義
Site Reliability Engineering:サイト信頼性エンジニアリング
Google エンジニアリングチームから生まれたもので下記のように定義します。
信頼性の高い本番環境システムを実行するための職務、マインドセット、エンジニアリング手法
信頼性とは
SREが達成すべき信頼性はサービスレベル目標によって定められます。
※早速期待に沿えない形になりますが、サービスレベル目標は各アプリケーションによって定義する必要があります。
サービスレベル目標はアプリケーションによって様々ですが、アプリケーションの信頼性向上のための構成要素は基本的にどのアプリケーションも共通しています。基本的な要素から高度な要素まで次の図の階層を使用して表せます。
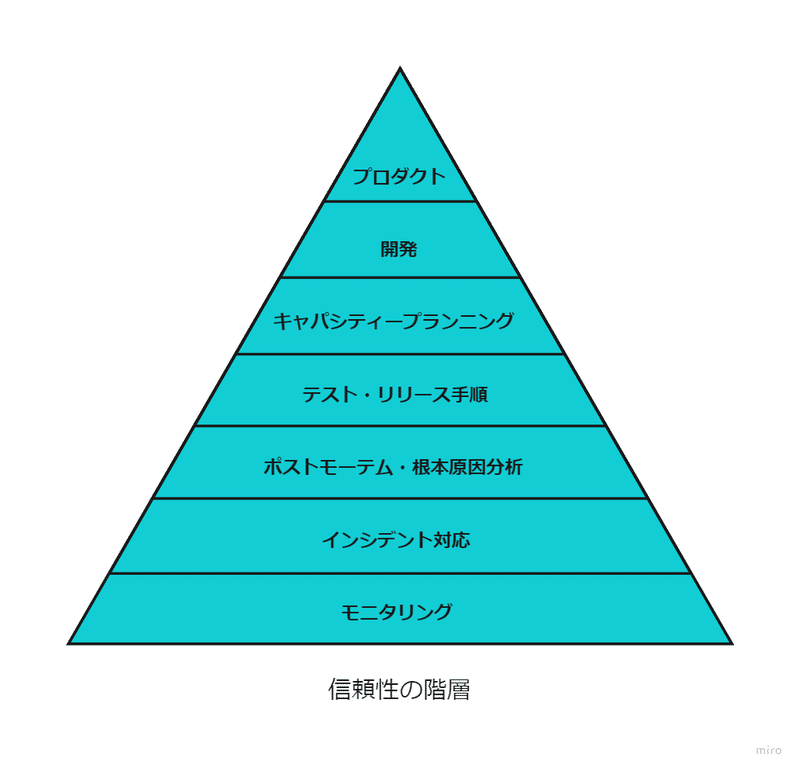
信頼性を向上させるためにSREは信頼性の階層ピラミッドにあるものすべてを考慮する必要がありますが、より低階層のものほど基本的な要素になります。
今回は最も基本的な要素3つについて説明します。
①モニタリング
サービスが機能しているかをモニタリングすることが最も基本的なSREの職務になります。
場当たり的なモニタリングになっていればそれは問題です。モニタリング要件・ルールを決め、異常を適切に検知できる仕組みを作ることが必要です。
②インシデント対応
インシデント対応の担当者とチーム全体で反復可能な対応フローをきめることが必要です。
③ポストモーテム・根本原因分析
インシデントから学習を行うことが必要です。インシデントの振り返りや管理を行い根本的に解決ができるフローを用意することが必要です。
※『Site Reliability Engineering』によればポストモーテムとはインシデント、その影響、それを緩和または解決するために取られた措置、根本原因、およびインシデントの再発を防ぐためのフォローアップ措置について書面で記録したものです。
A postmortem is a written record of an incident, its impact, the actions taken to mitigate or resolve it, the root cause(s), and the follow-up actions to prevent the incident from recurring.
自動化≒トイルの削減
信頼性を向上させる作業には多くのトイルが存在しており、トイルを放置するとミスの発生確率が高く、またスケールアップへの対応が遅くなり、信頼性が保てません。
トイル定義について『Site Reliability Engineering』の第 5 章には次のように記載されています。
次の項目の一つ以上に当てはまる作業 ・手動での作業を伴うもの ・繰り返されるもの ・自動化可能なもの ・割り込みで発生するもの ・一時的な対処であり、永続的な価値をもたらさないもの ・サービスの成長に伴い作業量が増えるもの
トイルを削減していくことによって、信頼性を安定的に効率的に保てます。
SREの文脈で自動化が多く語られているのはこのトイルを自動化によって削減しているからです。
1つの基準としてGoogleのSREはトイルに費やす時間を50%以下にすることを目標としています。
現在地を知る
SREは信頼性を高め、トイルを削減していくことが職務です。ただ、SREの必要性が叫ばれてからまだ年月が経っておらず、これからSREチームを立ち上げる組織も多いことでしょう。そもそもサービスレベルやモニタリング、その他の要件も決められていないということもしばしばあるとは思います。
まずはサイバーエージェントの成熟度概要を参考にして、現在地を確かめてみましょう。

SREを始める
現在地を確認した後は成熟度概要のレベルを上げていく営みを始めていきます。
立ち上げ時のやるべきアクションはこちらにまとめられています。
まとめ
今回の資料の結論は下記になります。
信頼性:サービスレベル目標によって定められる。
自動化が語られる背景:信頼性を向上させる作業にはトイルが多く存在ており、自動化によって削減する必要があるため
SREについて調べてはみたものの机上ではまだ漠然としています。
実務の中で気づいたことを随時追記していこうと思います。
推薦図書
書籍
Building Secure & Reliable Systems
The Site Reliability Workbook
Site Reliability Engineering
参考文献
Google - Site Reliability Engineering
サイト信頼性エンジニアリング(SRE) | Google Cloud
https://d2utiq8et4vl56.cloudfront.net/files/user/pdf/techinfo/SRETechnologyMap.pdf
この記事が気に入ったらサポートをしてみませんか?