自動論文まとめ4月8日

LLMを用いたクラウドインシデント管理のためのXライフサイクル学習 [LLM]
X-lifecycle Learning for Cloud Incident Management using LLMs
著作者: Drishti Goel, Fiza Husain, ..., Saravan Rajmohan
Trend
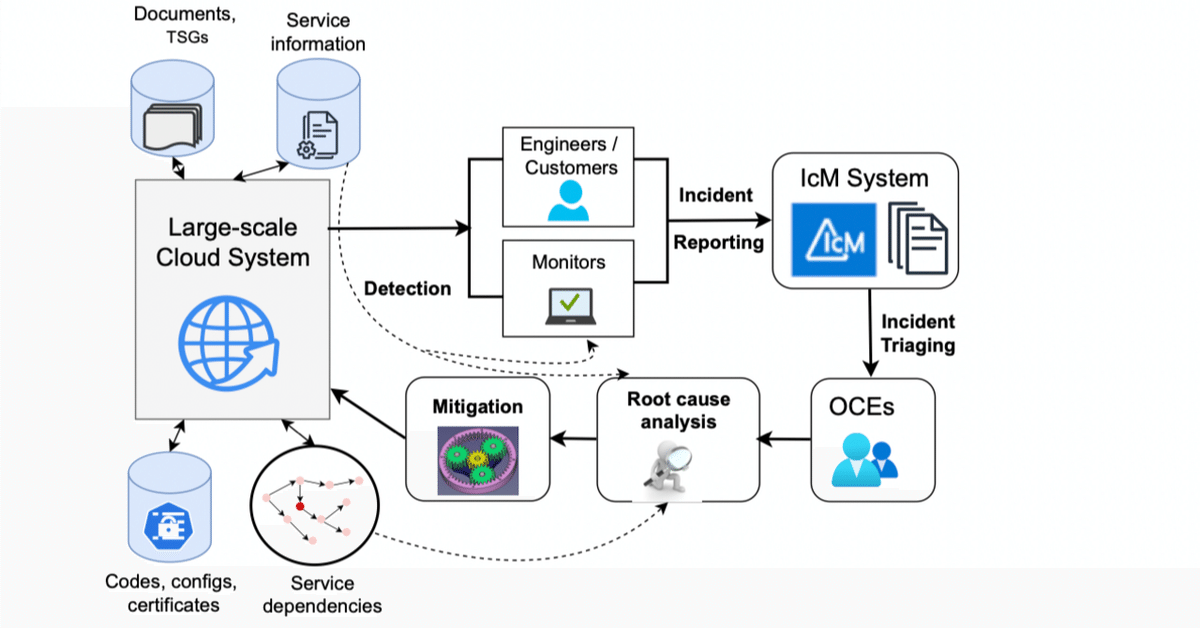
大規模なクラウドサービスのインシデント管理は複雑で手間がかかるが、最近の大規模言語モデルの進歩により、オンコールエンジニアが迅速に重要な問題を特定し軽減するためのコンテキスト推奨事項を自動生成する機会が生まれている。
Contribution
本研究では、ソフトウェア開発ライフサイクルの異なる段階からの追加のコンテキストデータを活用することで、依存障害関連のインシデントの原因推奨事項を自動生成するタスクと、インシデントを自動検出するために使用されるサービスモニタのオントロジを特定するタスクの性能を向上させることを示している。
医療ルールエンジンにおける差分テストの中心におけるLLMs: 医療ルールエンジンのケーススタディ [LLM]
LLMs in the Heart of Differential Testing: A Case Study on a Medical Rule Engine
著作者: Erblin Isaku, Christoph Laaber, ..., Jan F. Nyg{\aa}rd
Trend
医療ルールエンジンのテスト方法において、大規模言語モデル(LLMs)を使用するトレンドがある。
Contribution
本研究では、LLMsを使用したテスト生成と差分テスト手法(LLMeDiff)を提案し、GURIのテストにおける効果を検証した。
直接ナッシュ最適化:一般的な好みを用いて言語モデルに自己改善を教える [LLM]
Direct Nash Optimization: Teaching Language Models to Self-Improve with General Preferences
著作者: Corby Rosset, Ching-An Cheng, ..., Tengyang Xie
Trend
これまでの研究では、大規模言語モデルの後処理において、報酬最大化アプローチが一般的であったが、その限界が指摘されていた。
Contribution
本研究では、報酬最大化の枠組みを避け、一般的な好みに直接最適化するDirect Nash Optimization(DNO)アルゴリズムを導入し、GPT-4を超える性能を達成した。
SemEval-2024 Task 6におけるSHROOM-INDElabチームのゼロショットおよびフューショットLLMベースの幻覚検出分類 (Zero- and Few-Shot LLM-Based Classification for Hallucination Detection) [LLM]
SHROOM-INDElab at SemEval-2024 Task 6: Zero- and Few-Shot LLM-Based Classification for Hallucination Detection
著作者: Bradley P. Allen, Fina Polat, Paul Groth
Trend
大規模言語モデル(LLMs)を使用した幻覚検出のための分類器の構築に関する先行研究を拡張し、タスク、役割、および対象概念の文脈固有の定義を組み込んだSHROOM-INDElabシステムが開発された。
Contribution
SHROOM-INDElabシステムは、SemEval-2024 Task 6競技会でモデルに依存しないトラックとモデルに依存するトラックでそれぞれ4位と6位の成績を収め、分類の決定が人間のラベラーと一致していることが示された。また、自動生成された例を使用したfew-shotアプローチよりもゼロショットアプローチの方が精度が高いことが示された。
異なる色調のフェイク:警告がLLM幻覚に関する人間の知覚と関与に与える影響 [LLM]
Fakes of Varying Shades: How Warning Affects Human Perception and Engagement Regarding LLM Hallucinations
著作者: Mahjabin Nahar, Haeseung Seo, ..., Dongwon Lee
Trend
大規模言語モデル(LLMs)の広範な採用と変革的な影響により、その能力に疑念が生じています。この研究は、LLMの幻覚(hallucinations)に対する人間の知覚を理解することを目的としています。幻覚の程度(真実、軽度の幻覚、重度の幻覚)を系統的に変化させ、警告(不正確性の可能性に関する警告:存在しない vs 存在する)との相互作用を調査しました。
Contribution
この研究の主な貢献は、人間がコンテンツを真実と認識する順序が真実 > 軽度の幻覚 > 重度の幻覚であり、ユーザーのエンゲージメント行動も同様のパターンを示すことを示したことです。さらに、警告が幻覚の検出を改善し、真実のコンテンツの認識にほとんど影響を与えないことを観察しました。
GenQREnsemble: ゼロショットLLMアンサンブルプロンプティングによる生成クエリ再構成 [LLM]
GenQREnsemble: Zero-Shot LLM Ensemble Prompting for Generative Query Reformulation
著作者: Kaustubh Dhole, Eugene Agichtein
Trend
最近、ゼロショットQRが注目されており、大規模言語モデルに内在する知識を活用する能力が評価されています。
Contribution
本研究では、多くのタスクに恩恵をもたらしてきたアンサンブルプロンプティング戦略の成功を受けて、クエリ再構成を改善するためにそれらが役立つかどうかを調査しました。提案されたアンサンブルベースのプロンプティング技術であるGenQREnsembleは、ゼロショット指示の言い換えを活用して複数のキーワードセットを生成し、最終的に検索パフォーマンスを向上させます。また、擬似関連フィードバックを組み込んだGenQREnsembleRFも導入されています。評価では、GenQREnsembleは前のゼロショット最先端技術に対して、nDCG@10で最大18%、MAPで最大24%の改善を示しました。また、MSMarco Passage Rankingタスクでは、GenQREnsembleRFは擬似関連フィードバックを使用して5%のMRRの相対的な利益、関連フィードバックドキュメントを使用して9%のnDCG@10の相対的な利益を示しました。
この記事が気に入ったらサポートをしてみませんか?