
【R言語】文字列を任意の場所で分断する~”strsplit関数”

こんにちは。日々R言語の勉強をしている、生命科学系研究者のえいこです。
研究の現場(私の仕事場)でデータを取り込んで、すぐに論文レベルの統計解析をしてグラフを作ってくれるコードを作ることを目標に日々細々と勉強しています。
今回の記事は、バリバリ統計勉強しました!とか、コードをガッツリ書きましたとかではなくて、「文字列を分断してみた」といういつもなら一行でさらっと流してしまうことを1記事にしてみようと思います。
というのも、検定結果を並べたdata.frameから文字列を抜き出して別のことに使いたいと思った時に、「どうしたら良いのだーー!」と3日くらい途方に暮れたから。
具体的にどんなことをしたいかというと...

data.frame “df”に入っているcomparisonの”a:b”や”a:c”という文字列からそれぞれ”a” ”b”を取り出したい。
この取り出した”a” “b”を使って、
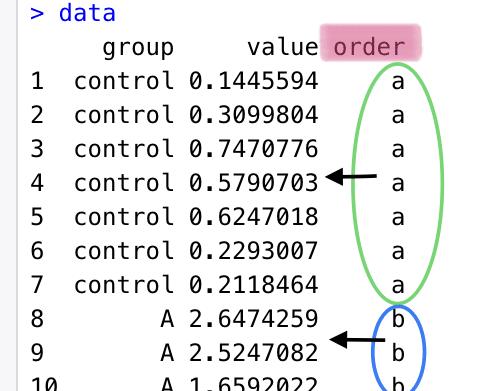
dataのvalueを呼び出したい。が今回の目的です。
この後for文で回して各組み合わせのvalueを使って効果量の計算などに使う目論見があります。
この記事では、
① data.frameから目的の文字列を抽出する
② 抽出した文字列から必要なところだけを取り出す
③ 取り出した文字列を使って別のdata.frameから値を呼び出す
をしていきます。
① data.frameから目的の文字列を抽出する
data.frameの要素を抽出するには、[]を使って要素を指定します。例えば、一行目の”a:b”を抽出したかったら
df[1,1]
df$comparison[1]とします。出力結果としては、
[1] a:b
Levels: a:b a:cとなって、”class()”関数を使ってデータの型を調べるとfactor型でした。
factor型は素人の私には使いづらいので、文字列に変換しましょう。
as.character(df$comparison[1])
[1] “a:b”文字列として、”a:b”を取り出せました。
でも欲しいのは、”a”だけ、”b”だけなので、”:”で分けられると良いのですが...
②抽出した文字列から必要なところだけを取り出す
ここでやりたいのは、「”a:b”という繋がった文字列を”:”で分解したい」ということ。
googleで調べてみると、やりたいことがRWikiに書いてあったので、早速やってみましょう。
文字列ベクトル要素をパターンに従って分解する関数は”strsplit()”。
使い方は、
strsplit(x, split, ectended=TRUE)
x: 分解する文字列
split: 何で分解するか
返り値は長さlength(x)のリスト。
“paste()”の逆の操作をする関数と覚えておくと良いかもしれません。
取り出した”a:b”を”:”で分けてみましょう。
strsplit(as.character(df$comparison[1]), “:”)
[[1]]
[1] “a” “b”と返ってきました。(splitの”:”は消えています)
“a”と”b”に分けられたのは良いのですが、”a”だけ、“b”だけを取り出すのにはどうしたら良いのでしょうか?もう少しコードを検討してみましょう。
結果はlistの形で返っています。listの第一階層の1番目を指定するコードを書いてみます。
strsplit(as.character(df$comparison[1]), “:”)[[1]][1]
[1] “a”“a”だけが取り出せました。
data.frame ”df”の形式はどんな検定をしても全て、”a:b”や“a:c”と出力されるように形式を統一しているので後はfor文に入れて回していくだけ!
◇
ちょっと気になったので...
もう少し文字列が複雑になったらどういうリストになるんでしょう?
x <- “Hellow World”
strsplit(x, “o”)とすると...
[[1]]
[1] “Hell” “w W” “rld”と出力されました。length(x)は1です。
では、
x <- c(“Hellow”, “World”)
strsplit(x, “o”) とすると...
[[1]]
[1] “Hell” “w”
[[2]]
[1] “W” “rld”と出力されました。length(x)は2ですね。
listで返すというのは、xのそれぞれの要素について分解した結果を表示してくれるということみたいです。
追記:
df$comparison[1]とかしないで、strsplitはlistで返してくれるのであればstrsplit()関数の中にdf$comparisonを直接突っ込んでみるのはどうかと思って試してみました。
strsplit(as.character(df$comparison), “:”)
[[1]]
[1] “a” “b”
[[2]]
[1] “a” “c”リストの第一要素に”a” と”b”、第二要素に”a”と”c”が表示されました。
data.frameの行数でfor文を作っても問題なさそうです。
③ 取り出した文字列を使って別のdata.frameから値を呼び出す
取り出せたのが文字列の形ですが、それを使って元のdataから値を呼び出せるのかやってみたいと思います。
まず、元々のdataのorderが”a”、”b”、”c”...となっているのでorderで行を選択することを考えました。
data.frameを操作するのには、dplyrが良いのでlibraryで呼び出しておきます。
dplyrのfilter関数を使えば良いのでは?と思いこんな感じのコードを作りました。
library(dplyr)
filter (data, order==x[[1]][1])
group value order
1 control 0.1445594 a
2 control 0.3099804 a
3 control 0.7470776 a
4 control 0.5790703 a
5 control 0.6247018 a
6 control 0.2293007 a
7 control 0.2118464 aこの"value"を使って、効果量の計算ができそうです。
◇おまけ◇
文字列を分断してlistに格納することができるようになったので、for文が書けるかどうかをここで試してみたいと思います。
x<- strsplit(as.character(df$comparison),":") #xという変数にlistを入れる
for (i in 1: nrow(df)){
print(paste(x[[i]][1], x[[i]][2], sep=" AND "))
}iをdata.frameの行数にして、分断した文字列を改めんて"AND"でつなぎなおしてみるというfor文を書いてみました。
出力結果は...
[1] "a AND b"
[1] "a AND c"きちんとfor文が回っていそうでヨカッタ!
このfor文の考え方を使って、効果量の計算コードを書いていこうと思います。
3日くらい調べながら書いた甲斐がありました。少しずつコードを書くスピードは速くなっているとは思ったのですが、まだまだですね。
それでは、また!
最後までお読みいただきありがとうございます。よろしければ「スキ」していただけると嬉しいです。 いただいたサポートはNGS解析をするための個人用Macを買うのに使いたいと思います。これからもRの勉強過程やワーママ研究者目線のリアルな現実を発信していきます。