
【超初心者向け】Pythonで顧客のアンケートデータを自然言語処理してみた

みなさんこんにちは!FOLIOアドベントカレンダーの8日目の記事です!
昨日は弊社の顧客基盤部でバックエンドエンジニアをされているmsawadyさんによる記事でした!
8日目の本記事は、FOLIO金融戦略部でコンテンツの編集&執筆をおこなっています設楽がお届けします。
この記事の目的
・初心者向けに、Pythonを使ったデータ分析(自然言語処理)の初歩の初歩を伝える記事。
読者対象
・Python初心者。データ分析初心者
・アンケートとか顧客の声を分析してみたいと考えている人
私ですが、普段は弊社サービスを使って頂いているユーザー様向けに、投資や資産運用に関するいろいろな記事を執筆、編集しているという、データ分析とかプログラミングとは全然関係ない業務をおこなっています。

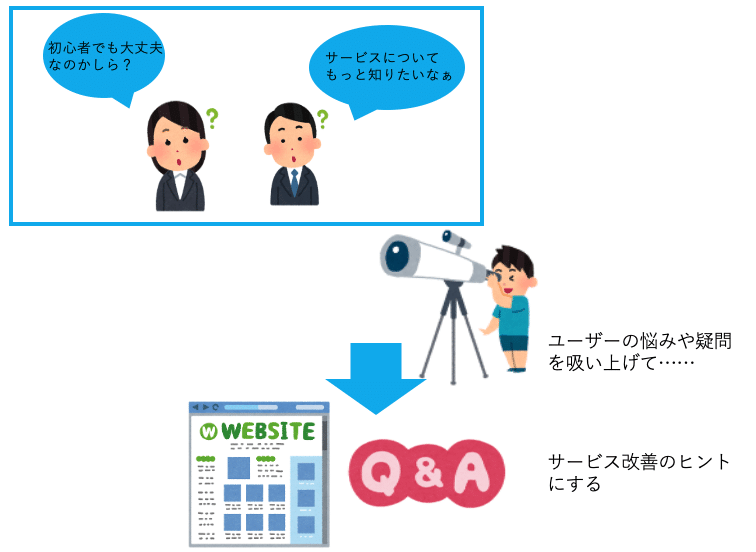
今回は、お客様から回答頂いているアンケートを使い、サービスがもっと良くなるためのヒントや、お客様がどういう点に困っていたり悩んでいるのかを、自然言語処理を使って分析してみたので、それをレポートしたいと思います。
単にアンケートの回答結果を眺めて、なんとなく直感や経験だけでユーザーの声に耳を傾けるのではなくて、プログラミングやデータ分析の力使ってお客様の声を傾聴すると、どんな結果になるのでしょうか?
なお、Python初めて約1年のほぼ初心者による記事ですので、高度なことは書いておりません。逆に初心者向けに基本的なことをわかりやすく書いたつもりです。
「これからプログラミングを始めたい」「プログラミングやってるけど、実用的なことがしたい!」と思っている方々のヒントになれば幸いです。
僕は40歳を過ぎてからプログラミングを始めたのですが、見る世界が変わりました。この記事を通して一人でも多くの人がプログラミングの世界に興味を持ってくれたらとても嬉しいです。
データ分析をする前に
データ分析を学んでいて気づいたことなのですが、データ分析をする上では、「目的」をきちんと定めて、仮説を立ててデータ分析から得られた定量的な結果から、どのような打ち手を取るのか? これが明確でないと、やる意味があまりないと個人的には思っています。
なので、大切なのは、データが得られたからすぐ何も考えずにコードを書いて分析をするのではなくて、ユーザーはどういう意見や感想や悩みを持っていて、そのペインポイントを解消するには、どんな策を取ることができるのか?を考えることが大切だなと僕は思っています。
まずはデータの取得
データ分析をするといっても、大元となるデータがないと話になりません。今回は、WEB経由でユーザーの皆様から回答を頂いたテキストデータが、会社のサーバーに保存されているので、それを使って分析したいと思います。
今回はサーバーに保存されているデータをcsv形式で吐き出し、それをExcelでtext形式に変換したものを使っています。まずはそれの読み込みからはじめます。
蛇足ですが、プログラミング未経験の方は、自分のパソコンでコードが書ける環境を設定するのは結構大変なので、Googleが提供している、Google Colaboratoryを是非使ってみてください。(Googleアカウントが必要です。たしか)
Google colabへのアクセス法は、Google colabとググっても出てきますし、ご自身のGoogle Driveの画面の左にあるメニューから、
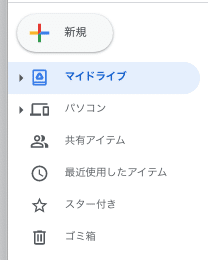
この新規ボタンを押すと以下のようなプルダウンメニューが出てきます。
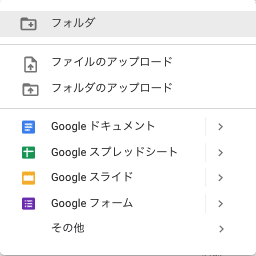
「その他」を押すと、google colabのメニューが出てくるのでクリックすると以下のような画面が出てきますので、これでPythonを書く準備は完了!めちゃ楽じゃないですか?ここまでを自分のパソコンで設定するのは本当一苦労なので、是非Google Colabを使うことをおすすめします。
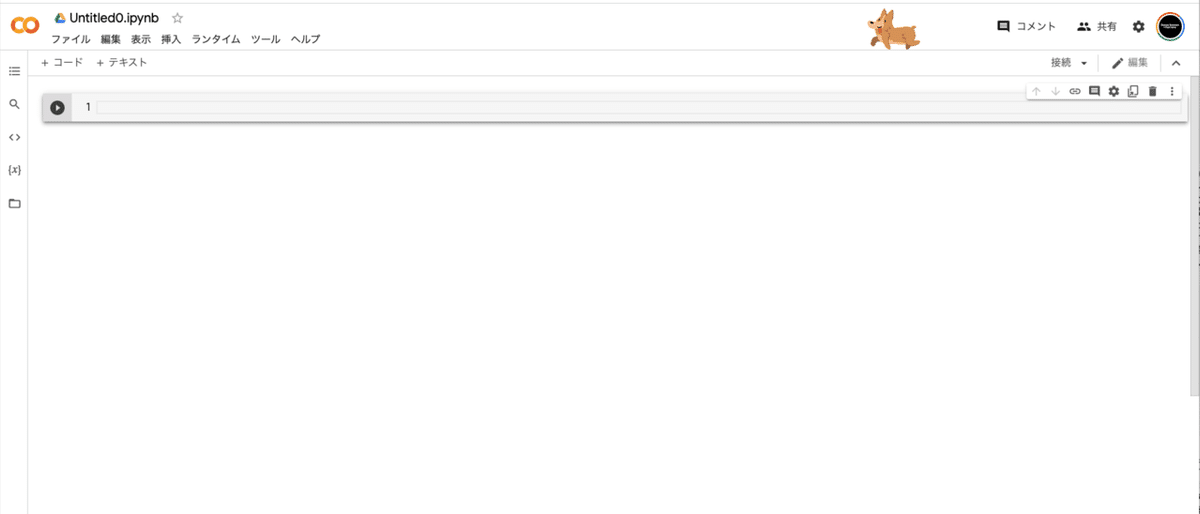
ここにコードを書いていきます。もし入力エリアが出てこない場合は、左上にある「+コード」というボタンを押してください。入力エリアが出てきます。
ファイルの読込準備
ではさっそく、Google Colabにアンケートデータのtextファイルを読み込みます。これをやらないと分析がはじまりません。
上の画面の左側にある縦メニューの一番下のフォルダのアイコンを押すと、以下のような画面が出てきます。
この赤丸ボタンをクリックすると、ファイルが選択できるので、用意したtextファイルを読み込みます。すると以下のような状態になります。私の場合は、「user_voice_final.txt」というファイル名にしたので、読み込まれているのが確認できますね。
テキストの読込&不要な文字の削除
では早速コードを書いていきましょう。本記事は初心者向けに書いたものですので、かなり平易&まわりくどい説明になっていますが、そこはご了承ください。あと、pythonの文法等に深く触れないので、本記事で興味が出たら是非入門書等で勉強してみてください。
ちなみに#の後に書かれた行は書いてあるコードの説明なので、ここはご自身で書く必要はありません。
なお、open()内の''で囲まれたファイルの場所を示すパスがわからない場合は、さっき読み込んだファイルを右クリックすると「パスのコピー」というメニューが出てくるので、それをコピペすればOK。なんと便利なんでしょうー。
#ファイルを読み込む。パスがわからない場合は読み込んだファイルを右クリックしてcopy&pasteするだけ。
user_voice = open('/content/user_voice_final.txt', encoding='utf-8')
#読み込んだファイルを↑でuser_voice変数に格納して、↓でread関数を使って読み込んでtest変数に返す。
text = user_voice.read()
text5行目のtextまで入力してからshift+return(command+returnでも)すると、以下のように無事自分が分析したいテキストが読み込めるはずです(業務上私の取り込んだ文章の中身は見せられないので一部モザイクかけています)。

なお、pythonはtextファイルじゃなくても、excelファイルもカンマ区切りのcsvファイルも読み込めちゃいます。便利ですねー。
さて、早速分析をはじめていきましょう。
まず最初にやることは、分析に不要そうな単語の削除です。先程吐き出したテキストを見ていただくとわかるのですが、\nのような文字がありますよね。これは改行のコードですので不要です。
あと括弧(「」()etc)や全角他、不要と思われるものは削除します。これを削除する方法は「正規表現」というものを活用するのですが、ここで詳細は割愛します(正規表現は難しくて自分もよくわかってない)。以下のコードを記述してみます。
#正規表現を使うためのライブラリを読み込む
import re
#変数text中に格納されたアンケート内の不要な文字や記号を削除する。
#re.subで正規表現を使った文字列の置換。
text = re.sub('\u3000', '', text)
#例えば以下だと、引数に削除したい記号(中黒)、削除後の処理、処理を実行したいデータが格納された変数textに格納される。
text = re.sub('・', '', text)
text = re.sub('「', '', text)
text = re.sub('」', '', text)
text = re.sub('(', '', text)
text = re.sub(')', '', text)
#処理後には半角スペースを入れたい場合は二番目の引数に' 'と入れる。
text = re.sub('\n', ' ', text)
text = re.sub('\\n', '', text)
text = re.sub('\\n', ' ', text)
#これでもできる。正規表現を使わないreplaceというメソッドを使った方法
text = text.replace('\\n', '')
textもっとエレガントに書く方法があるのですが、ここではわかりやすく変数textに格納されているアンケート文章に対して、正規表現を使って不要な記号などを削除して、また別の不要な記号を削除して変数textに入れて……という処理をしています。
この処理をおこなった結果が以下です。先程あった\nなどが消えているのがわかりますね。

ユニコード正規化
次にユニコードの正規化という処理をしておきましょう。聞き慣れない言葉かもしれませんが、平たく言うと、丸囲みの数字や半角カタカナ、全角の英語など、データ分析に悪影響を与えそうなテキストデータをクレンジングしてくれます。
たとえば丸囲みの数字は半角数字に、半角の日本語は全角に、全角のアルファベットは半角にしてくれます。
ユニコード正規化はとても簡単で、ライブラリをインポートしてunicodedata.normalize('NFKC', text)という一文を書くだけです。以下実験でやってみましょう。
#ユニコード正規化。ライブラリを入れる
import unicodedata
#元のテキスト。①とか半角カタカナとか入ってるのを確認
text_sample = '①番の山田さんは73㌔です。データから推測するとGOODな体重ですよ。
エッ?俺の体重?それは㊙だよ。'
#以下がユニコード正規化前。
print('UNICODEの正規化前:{}'.format(text_sample))
#一行以下を書くだけ
text_sample = unicodedata.normalize('NFKC', text_sample)
#ユニコード正規化した後のテキストは以下。
print('UNICODEの正規化後:{}'.format(text_sample))正規化前と正規化後のテキストを比較してみると、以下のようにきちんと変換されているのがわかります。
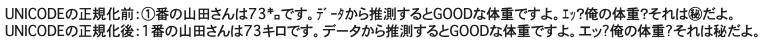
この一文をアンケートのtextにも適応しておきましょう。text変数にいれたデータを上とおなじようにunicodedata.normalizeするだけです。あ~ら簡単(ここでは省略)。
形態素解析をおこなう
英語の場合だと「I have a pen」「I hava an apple」のように単語一つ一つがバラバラになっているのですが、日本語は「今日は天気がいいですね」のように単語と単語が繋がっていますね。
これは分析をする上では非常に問題で、単語をバラバラにして「今日」「は」「天気」「が」「いい」「です」「ね」のようにしてから分析をおこなう必要があります。この区切る機能を「形態素解析(けいたいそかいせき)」といいます。
形態素解析は単語の区切りと同時に、品詞の種類など、単語の性質にも同時に分析できます。
この形態素解析は色々なエンジンがありまして、先達の方々がとても便利なツールを開発してくださっているので、私達は必要なライブラリをインストールしたりインポートするだけで、とても便利な機能を簡単に使うことができます。有名なエンジンにはMeCab,Janome,JUMANなどがあります。
ここでは、MeCabを使った初歩的な形態素解析についてみてみましょう。まずは必要なライブラリのインストールです。これは「おまじない」のようなものだと覚えてください。
!pip install mecab-python3
!pip install unidic
!python -m unidic download今回は、形態素解析の使用例でよく出てくる「もももすももももものうちもももすももももものうち」という日本語を解析していきます。
私達は、これが昔からある早口言葉で「桃も李も桃のうち、桃も李も桃のうち」と単語を区切ることが経験上できます。
しかしコンピューターはそんなことはわかりません。さて、どうやって単語をわければいいでしょうか?
そこで登場するのが形態素解析です。以下のコードを書いてみましょう。
import MeCab
import unidic
#すももテキストを作る。
text_sumomo = 'すもももももももものうちもももすももももものうち'
#おまじないのようなもの
tagger1 = MeCab.Tagger('-Owakati')
#printの()内のテキストが出力される。
print('表示されるパターンその1:品詞ごとに分かれて表示される(わかち書き)')
#単語ごとに分解されて表示される。
print(tagger1.parse(text_sumomo).split())
#改行
print()
#おまじないのようなもの
tagger2= MeCab.Tagger()
print('表示されるパターンその2:品詞を回析したものを表示')
#単語ごとにより詳しい情報が表示される
result_sumomo = tagger2.parse(text_sumomo)
print(result_sumomo)
表示されるパターンその1の箇所を見ていただくとわかるように、ちゃんと品詞で分解してくれているのがわかるかと思います。
パターンその2には品詞を解析した結果も出てきますね。ちゃんと品詞分解されていますね。頭ええ!!
ちょっと別のテキストでも実験してみましょうか。二つの例文を作ってみました。今回はちょっと毛色の違う日本語です。
「僕はB'zの曲は全然知りませんが、ultra soulぐらいは知っています。好きなアーティストはサザンオールスターズで、勝手にシンドバッドが好きです。」
「紅の豚と天空の城ラピュタととなりのトトロだったら一番好きなのはどれですか?」
これを解析してみると……。
text_sample_bz = '僕はB\'zの曲は全然知りませんが、ultra soulぐらいは知っています。好きなアーティストはサザンオールスターズで、勝手にシンドバッドが好きです。'
text_sample_ghibli = '紅の豚と天空の城ラピュタととなりのトトロだったら一番好きなのはどれですか?'
tagger2= MeCab.Tagger()
result_text_sample_bz = tagger2.parse(text_sample_bz)
print(result_text_sample_bz)
result_text_sample_ghibli = tagger2.parse(text_sample_ghibli)
print(result_text_sample_ghibli)

エラーが出ないで解析されているようですが、何かがおかしいですよね?
そうなんです。例えば今回の場合は「サザンオールスターズ」と固有名詞で分割して欲しいのですが、「サザン」「オール」「スターズ」と3つの名詞に、「天空の城ラピュタ」と分割して欲しいところ「天空」「の」「城」「ラピュタ」と分割されてしまってますねー。
これは困りますよね。たとえばあなたが、ニュースサイトの記事の分析を任されたとして、固有名詞がこのようにバラバラに分解されてしまっては、正しい分析ができません。
さて、これはどうしたらいいでしょうか?
そこで登場するのが、新語に強いライブラリです。こいつをインポートしてやって回析します。ライブラリは世の中に沢山あるのですが、今回はToshinori Sato (@overlast)さんの辞書をinstallさせていただくことにしましょう。
#最近の言葉に強い辞書を入れて形態素解析して違いを見る。
!apt-get -q -y install mecab libmecab-dev file
!git clone --depth 1 https://github.com/neologd/mecab-unidic-neologd.git
!echo yes | mecab-unidic-neologd/bin/install-mecab-unidic-neologd -nこれをインストールすると、最後に、

というのが出てくると思います。この文章の以下のテキストに注目です。
When you use MeCab, you can set '/usr/lib/x86_64-linux-gnu/mecab/dic/mecab-unidic-neologd' as a value of '-d' option of MeCab.
「MeCab使うときには、-d以下はこんな感じで書いてね」と言ってますので、dic_dirの部分で-dを指定してあげて以下のコードを記述します。
#ディクショナリを指定する
dic_dir = '-d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-unidic-neologd'
#テキストを変数に格納する
text_sample_bz = '僕はB\'zの曲は全然知りませんが、ultra soulぐらいは知っています。好きなアーティストはサザンオールスターズで、勝手にシンドバッドが好きです。'
text_sample_ghibli = '紅の豚と天空の城ラピュタととなりのトトロだったら一番好きなのはどれですか?'
#Taggerの引数にdic_dirを入れてtagger3変数へ格納する。
tagger3= MeCab.Tagger(dic_dir)
#tagger3でテキストをparseして、result_text_sample_bzへ格納。
result_text_sample_bz = tagger3.parse(text_sample_bz)
print(result_text_sample_bz)
#上のことを繰り返しジブリのテキストもparseする。
result_text_sample_ghibli = tagger3.parse(text_sample_ghibli)
print(result_text_sample_ghibli)気をつけて欲しいポイントは、最初に-dを指定してdic_dir変数に入れていることと、それを9行目の.Tagger()の引数にdic_dirを使ってあげていることがポイントです。これをprintしたのが以下です。


見ての通り、綺麗に分割されているのがわかります。ultra soulとか天空の城ラピュタが固有名詞になってるのはちょっと感動を覚えませんか(笑)!?(俺だけか?)
せっかくなので、もう一つのエンジンjanomeを使った形態素解析もやってみましょう。janomeの方がMeCabに比べてもっと短いコードで形態素解析ができます。まずはpip installでjanomeをインストールします。
#janomeはもっとシンプルに形態素解析をおこなえる。
!pip install janomeそして以下のコードを書きます。サンプルのテキストは「今日の昼ごはんはチャーハンと半ラーメンと餃子でした。」という町中華感満載の一文。
text_janome = '今日の昼ごはんはチャーハンと半ラーメンと餃子でした。'
#janomeのtokenizerをインポートする
from janome.tokenizer import Tokenizer
text1 = Tokenizer()
#for文をつかってtext_janomeを一単語ずつtokenizeする。
for tokenized_text in text1.tokenize(text_janome):
print(tokenized_text)これを実行すると以下が出力されて、ちゃんと品詞で分解されているのがわかるかと思います。

アンケート文を形態素解析して可視化してみる
さて、ちょっと脱線してしまいましたが、形態素解析を用いれば、単語を一つずつわけられることがわかったかと思います。ここでアンケート文の内容を分析してみましょう。
ここで使う手法は、WordCloudという単語の頻出度合いによって単語を大きく見せたり小さく見せたりして直感的に頻出度合いがわかる方法です。
文章で解説するよりも、実際に見たほうがわかりやすいので実装してみましょう。まずは使うライブラリのインポートです。
#必要なライブラリのインポート。
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from janome.tokenizer import Tokenizer続いて日本語フォントのインストール
#グラフの文字化けを防ぐためフォントのインストール
!apt-get -yq install fonts-ipafont-gothic以下がWordCloudを表示するためのコードです。
#日本語のフォントを指定する
font = '/usr/share/fonts/opentype/ipafont-gothic/ipagp.ttf'
#text変数には形態素解析して可視化したいtextファイルを入れておきます。
t = Tokenizer()
#tokenizeしたテキストを、tokenized_textに格納
tokenized_text = t.tokenize(text)
#わかち書きされた単語を格納するためのlistを用意する。
words_list=[]
#tokenizeされたテキストをfor文を使ってhinshiとhinshi2に格納する。
for token in tokenized_text:
tokenized_word = token.surface
hinshi = token.part_of_speech.split(',')[0]
hinshi2 = token.part_of_speech.split(',')[1]
#抜き出す品詞を名詞だけにする、ただし数と代名詞と非自立は除く。
if hinshi == "名詞":
if (hinshi2 != "数") and (hinshi2 != "代名詞") and (hinshi2 != "非自立"):
words_list.append(tokenized_word)
words_wakachi=" ".join(words_list)
#明らかに頻出語になりそうで、しかも意味なさそうな単語(ストップワードといいます)を除去する。
stopWords = ['ので','そう','から','ため','自分', '投資','運用']
#WordCloudを表示。色々な引数が用意されてて、サイズや背景色などがパラメーターとして用意されている。
word_cloud = WordCloud(font_path=font, width=1500, height=900,
stopwords=set(stopWords),min_font_size=5,
collocations=False, background_color='white',
max_words=400).generate(words_wakachi)
#画像表示のメソッド
plt.imshow(word_cloud)
#表示サイズの指定
plt.figure(figsize=(20,15))
#画像を表示する
plt.show()さてちょっと長いですが、これを実行すると以下のようなWordCloudがめでたく出てくるはずです(ここも業務の都合上隠している部分があります)。

このWordCloud化で大切なことは「お客様がどんな話題に触れているのか?」というのがビジュアライズされている点で、ここに色々な仮説を立てるヒントがあると思いませんか?
「手数料について多く話題に上がってそうだか、手数料の何に困っているのだろう?」
「期待、とは何に期待して頂いているのだろう?」
「利益、が多く取り上げられてるようだが、利益のどんな話題が多いんだろう」
などなどです。
つまり、次の分析手法としては、wordcloudで浮上した頻出単語は、「どんな単語と関連しているのか?」がわかるとよりユーザーが何に悩んでいるのかが見えてくると思いませんか?
そこで使えるのがWord2Vec(ワードツーベック)という手法です。
Word2Vecで単語間類似度を調べる
Word2Vecについてここで深堀りすると難解になるのと、長いコラムになってしまうので割愛します!
まあ一言で言うと、単語を数値化(厳密に言うとベクトル化)して単語同士の意味の近さを計算することができます。私は最初聞いた時に何を言っているのかさっぱりわからなかったのですが(笑)、簡単に言いますと、
「東京ー日本+アメリカ=ニューヨーク」
みたいな計算ができるっていうすげえ手法なんですが、これでもなんだかよくわかりませんよね(笑)。興味のある方はWord2Vecで調べてみてください。
ということで、今回はWord2Vecの雰囲気を知るために、まずは実装してみることにしましょう。まずは下処理です。最初に以下のコードを書いてください。
tok = Tokenizer()
#名詞と動詞と形容詞を抽出するためのpickup_wordsというメソッドを作る。
def pickup_words(text):
tokens = tok.tokenize(text)
return [token.base_form for token in tokens
if token.part_of_speech.split(',')[0] in['名詞', '動詞','形容詞']]
pickup_words(text)ここでは名詞と動詞と形容詞をtextから抽出するためのメソッドを作ってpickup_wordsという名前で定義しています。これを実行すると以下のように単語がリストになって表示されると思います。(一部業務に関わるのでモザイク処理しています)

次に以下のようなコードを書いて、この単語のリストを文章ごとに列にして入れ子構造にします。
#全体のテキストを「。」で区切った配列にしてsentences変数に格納
sentences = text.split('。')
#各文章を単語のリストに変換してwords_list変数に格納
words_list = [pickup_words(sentence) for sentence in sentences]
#words_listを表示する
print(words_list)これを実行すると以下のようになります。
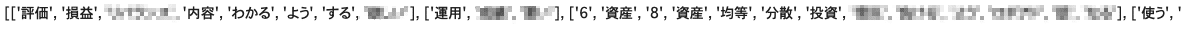
これでWord2Vecを実行する前準備ができました。早速コードを書いていきます。
# Word2Vecライブラリのロード
from gensim.models import word2vec
#Word2Vecの引数は、さっき作ったリスト、iterは学習の繰り返し数,min_countは出現頻度が低いものをカット
#windowは前後の単語を拾う際の窓の広さ、sizeは次元圧縮数
user_voice_model = word2vec.Word2Vec(word_list,
iter=100, min_count=5, window=5,size=50)一番下の行のWord2Vecの()の中身の意味がよくわからないですよね。これについて説明すると大長編になるので割愛します。興味のある方はgoogleで「Word2Vec パラメーター 引数」みたいなので検索すると詳しい記事が出てくるはずです。
さてあっという間にWord2Vecを使った「use_voice_model」という名前のモデルができました。これを使ってアンケートを分析します!
今回は、さきほどwordcloudで可視化した時に大きく表示された「手数料」という単語について分析してみましょう!
#作ったWord2Vecのモデルで分析。
#手数料という単語の特徴量ベクトルを調べる。モデル名.wv['分析したい単語']
print('「手数料」の特徴量ベクトルは以下出ました↓')
print(user_voice_model.wv['手数料'])
print()
#手数料に近い単語はなんだろうか?
print('「手数料」に近い単語を洗い出したら以下出ました↓')
#most_similarメソッドを使って、手数料という単語に類似した単語を分析してみた。
for word, value in user_voice_model.wv.most_similar("手数料"):
print(word, value)これを実行すると以下のような結果が出ました!

手数料と関連して使われている単語は、「安い」「出金」「高い」のような単語が出てきました。まあ当たり前っちゃ当たり前ですが……。
ただ、こういう手法で、ユーザーの皆様のペインポイントを探り、サービスをもっと快適に、もっと安心して使ってもらえるような記事を書いたりUI、UXを工夫するようなヒントが得られるんじゃないかと思います。
あと、そもそもですが、モデルの精度が今ひとつな感じがするので、モデルを作る時のハイパーパラメーターをチューニングするなどして、精度を上げる必要がありそうです。
あとは、Word2Vecでベクトル化したデータをクラスタリングして、そのクラスの中で共起する単語を出してみるのような分析や、そのクラスタリングがきちんとしたクラスに分類されているか?を確かめるためにt-SNEやUMAPなどの次元削減をやってみるのもいいのかなーと思っていますが、またの機会にお届けしたいと思います。
いかがでしたでしょうか!?
この記事を通して、
「プログラミングって面白そう!」
「Python、データ分析やってみたい!」
と思ってくださる方がいれば嬉しいですー!
最後までお読みいただきありがとうございましたー!
明日の9日目は、この人に聞いたらだいたい何でも教えてくれるエンジニア、kenchan0130さんの記事です。

東京都八王子市高尾山の麓出身。東京在住の編集者&ライター。ホッピー/ホルモン/マティーニ/アナログレコード/読書/DJ