
スケールし続ける組織におけるデータマネジメント

お久しぶりです。マネーフォワード分析推進室で日々データマネジメントに勤しんでいるササキです。他の方が書いた記事内にはちょこちょこ登場したりもしていたのですが、自分で記事を書くのはだいぶお久しぶりになってしまいました。
今回はマネーフォワードでなぜLookerを導入したかという話を軸に、マネーフォワードにおけるデータマネジメントについて整理してみたいと思います。後述しますが、マネーフォワードは組織の人数も事業の数もものすごいスピードで増えており、そういった環境下でのデータマネジメントに求められることを発信することで似た悩みを抱えている or 今後抱えそうな組織の助けになれることを期待しています。
前段:マネーフォワードの組織と事業領域は拡大している👆
さて、本編に入る前にまずはマネーフォワードという会社全体の動きについて、IR資料を引用しつつ紹介させてください。

マネーフォワードはちょうど今年の5月に設立10周年を迎えた会社です。
「お金を前へ。人生をもっと前へ。」というMissionを掲げ、お金にまつわる世の中の課題解決を通じてユーザーのみなさまの人生をもっと前に進められるようサービスを展開しています。
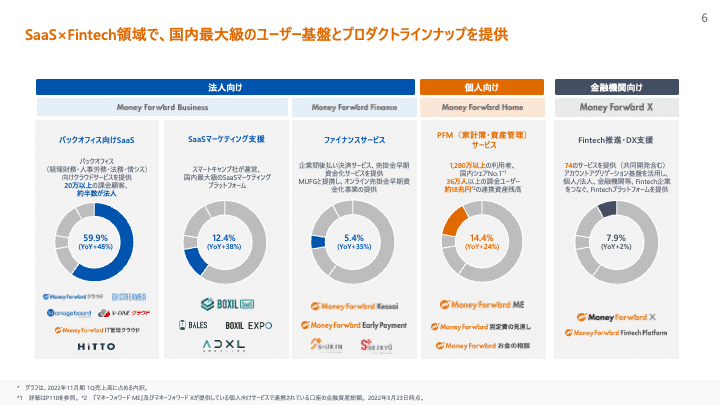
提供しているプロダクトのラインナップは非常に幅広く、家計簿アプリを中心とした一般消費者向けの事業領域とバックオフィスの生産性向上を支援するSaaSツールを中心とした法人向けの事業領域に加え、銀行等の金融機関のDX支援を通じた金融サービスの価値向上という事業領域も展開しています。
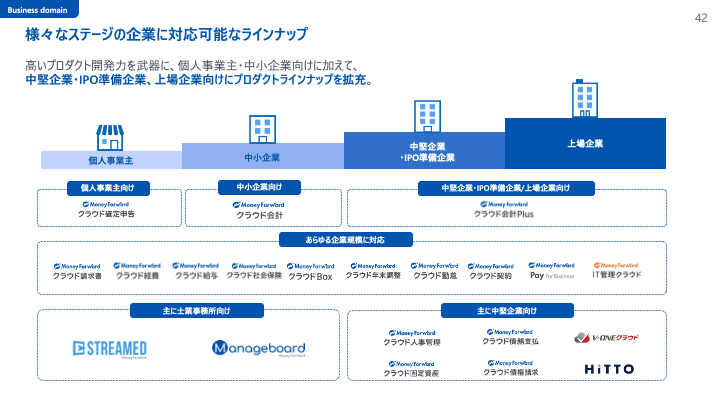
それぞれの領域でも複数のプロダクトが提供されており、バックオフィス向けSaaSの領域だけでも10を超えるプロダクトを提供しています。が、これはまだ道半ばであり、今後もプロダクトが増えていき、提供できる価値領域が拡大していくことが見込まれています。
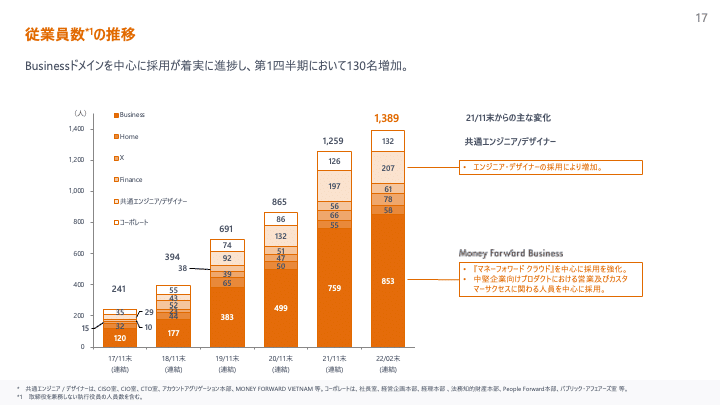
組織の規模としても拡大しており、2022年2月末時点で約1,400名が在籍しています。私が入社した2019年11月時点では700名弱だったため、2年半でだいたい倍の規模になったというスピード感です。(ちなみに私の前職は100名弱の企業だったため入社した時に社内ですれ違う人の多さに震えていましたが、今でも出社すると人の多さに震えています。)
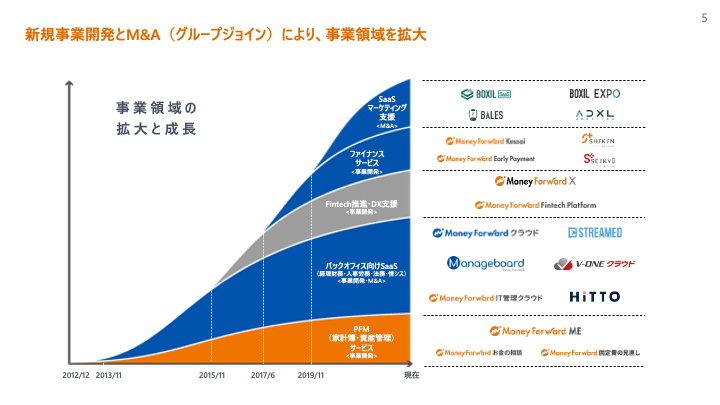
また、マネーフォワードはM&A(社内ではグループジョインという表現を使っています)も継続的に行なって価値提供領域を拡大しており、プロダクトもチームも増えているという状況です。
と、長くなりましたがここまでが前段の話で、そんなマネーフォワードの中で我々分析推進室がどんなことを考えて動いているかをここから書いていきます。
事業と組織の数が増えると、横断的な指標管理の難易度が上がる🤔
提供するサービス数が多くなるとそのサービスを取り扱うチームが増えていきます。これは言い換えるとそのサービスに対する投資対効果に責任を持つ人間が増えていくことを意味しています。
投資対効果をシンプルに分解すると売上とその売上をあげるためにかけた投資コストが構成要素になりますが、この集計は文章で表現するより遥かに難易度が高いです。理由はいくつかありますが、例えば売上という言葉を一つ取ってもその定義には人(組織)によって解釈の幅があることが挙げられます。
売上は組織のKPIとして扱われることが多く、KPIとして設定することはメンバーに期待される動きを決める(≒そのKPIを達成しようとするインセンティブとして働く)効果があります。そのため、組織によって税込や税抜、受注日ベースか入金日ベースかといった点で定義がばらついてしまう可能性があります。
具体例を挙げると、フィールドセールス部隊がいるチームでは受注した月をベースに受注した金額を売上としてKPIに設定している一方で、オンラインで契約が完結するためフィールドセールス部隊がいないチームでは受注の概念より実際の利用に基づく請求を重視し、請求月をベースに請求金額を売上としてKPIに設定している、ということが起こり得るのです。
さらに、実際にはサービスごとに組織体制が組まれているわけではなく、様々な戦略的要因によって組織体制が決まっているため、この議論はより複雑化しています。
経営管理観点からするとこれは大変に由々しき事態です。チームごとの売上を横断的に比較したいのにも関わらず、当月の受注売上と請求売上が混在していたとすると意思決定を誤ってしまいます。
分析推進室の設立とBI導入の経緯👶
そこで経営企画部からスピンアウトして設立されたのが我々分析推進室でした。
分析推進室は、上述のような状況下で横断的に指標を統一するのみでなく、その集計定義やデータソースも含め管理することを目的にデータ統合基盤を構築しています。これはまさにデータマネジメントと言える取り組みそのものです。求められる要件は多岐に渡り、集計結果が経営の意思決定に利用されることを考えるとデータ自体の品質に加えパイプライン全体の高い品質管理が要求されます。この品質管理の思想をSingle Source of Truth(通称SSOT)と呼んでおり、SSOTなデータ統合基盤を管理・運用・育成していくことを目指しています。(前任者による詳細記事は以下。)
前段でも説明したとおり、事業・組織数が多く、加えて継続的に拡大している環境において品質を担保しつつデータによる意思決定がカバーできる範囲を拡げていくのは非常に難易度が高い取り組みです。(一方、一般的には現場の意思決定をデータドリブンに行うためにデータマネジメントを考え始めることが多いのかなと想像しますが、経営管理を行うという目的からトップダウンにデータマネジメントを進め始められたのは幸運だったとも思っています。)
また、データ統合基盤をSSOTに構築できればそれで終わりかというとそうではないのがさらに難しいポイント。データユーザーは経営レイヤーのみではなく現場レイヤーにも多くいるので、その方々にも使ってもらえるような構造で構築しなければいけません。
ここで考慮すべきは、経営レイヤーで見る粒度の大きな数字のみを管理するのではなく、その大きな数字が現場の方のアクションにまでブレイクダウンできる世界を作ることが重要です。この件については簡単な紹介に止め、詳しくは別の記事に書こうと思います。
ここでお伝えしたきことは、データ統合基盤は構築するのみではなく、データユーザーにどうやって届けるかも考慮すべきという点です。経営・現場での意思決定の場にデータアナリストがいつでもいられるのであればその場でSQLを書いて問い合わせればそれで良いかもしれませんが、現実的にはなかなか実現が難しいことが多いかと思います。そこで解決策となるのがBIツールの導入でした。
LookerとSSOT🧩
分析推進室では、データ統合基盤へのアクセス方法としてLookerというBIツールを導入しデータユーザーに提供しています。この記事の締めくくりとして、なぜLookerを選んだかというポイントをお伝えできればと思います。
Lookerは第三世代BIに分類されるBIツールで、データの可視化のみではなくLookMLと呼ばれる言語でデータベースへの接続やデータ抽出・集計の定義を記述することが特徴です。コードベースで集計定義が管理できるということは、GitHubを使うことでバージョン管理を頑健に行うことができます。これは、SSOTの実現において大きなメリットです。
マネーフォワードでは、本番環境でのLookML改修時はレビュー必須にしており、集計軸や集計方法の設定はもちろん、命名規則についてもレビューを行いマージしています。これは成果物自体のクオリティだけでなく、レビュー時に理解しにくかった項目について質問することで集計ナレッジの形式知化につながるという意味でも有用なプロセスだなという副産物的な気づきもありました。
余談ですが、私自身も前職で別のBIツールを利用していましたが、他人が作ったダッシュボードの読み解きに時間がかかったり、自分が作ったものであっても過去の定義に戻すことに苦戦したりした経験があります。
他の特徴として、Looker自体にデータを保持しないということもSSOTと親和性が高いと言えます。接続先のデータベースに格納されているデータが常に参照されるため、手元で見ていた数字が古かった!という辛いあるあるが発生しません。
以上がLooker導入の理由です。
スケールし続ける組織におけるデータマネジメント🚀
一方で、頑健であることは裏を返すと自由度が低いということでもあります。
LookML自体は出来ることもかなり多いのですが、手元にあるデータを可視化し、集計の定義自体もいじりながら試行錯誤し探索的に分析するためにはLookerだと道のりが長すぎるという課題もあります。
今までは分析推進室が中心にLookMLの記述とLookerでの可視化・分析双方を行なっていましたが、徐々に事業部のデータユーザーが自ら可視化・分析を進めてくださる事例が増えてきており、ここのステップを登っていくハードルをいかに下げるかということに向き合い始めています。データガバナンスとデータの民主化を両立する難しさがここにあります。
実際問題として、中途入社のメンバーが前職で利用していたBIツールを利用して仕事をしたいと相談してくださるケースもあり、それ自体を禁止するのも違うよなと思ったりもしています。これはデータ統合基盤自体にも似た話が発生しており、事業部側にいるデータアナリストが自らの分析用データマートを作りたいが、分析推進室としては個別性の高い要件に基づくデータマートはあまり増やしたくないというコンフリクトが発生しています。
最近だとデータ基盤をマイクロサービス化していくというData Meshと呼ばれる考え方が話題になっており、我々でも特徴をキャッチアップしていかなければと思っています。上のようなコンフリクトを解決する手段としては理解できる一方で、データマネジメントという幅広く奥深い領域のリテラシーを専門組織が提供せずにボトムアップに実現することは可能なのだろうかという疑問もあります。
このあたりの話はまた別の機会にでも整理できればと。他社さんの事例も是非聞いてみたいポイントです。
ということで、仲間も募集中です🙏
なんでもかんでも仲間募集で終わるのもなと思ったのですが、ここまで読んでいただいた方であればきっとデータマネジメントに何かしらの興味を持っているはず…!ということでポジションも貼っておきます。

難易度は高いですがチャレンジングで、かつ自身の意思決定が中長期的に影響力もあるという意味でとても面白いポジションかなと思います。
少しでも興味ある方はmeetyでも良いのでお気軽にご連絡ください。
是非お話ししましょう〜👋
この記事が気に入ったらサポートをしてみませんか?