
自然言語処理(NLP)について知りたくなったら~形態素解析 コード実践編~

どうも! データテクノロジーラボです。
前回、自然言語処理の雰囲気をつかめるように概要を解説しました。
今回から「実際にプログラムで動かす」ことを中心として、解説していきます(という想定です。補足や必要な知識があれば随時書いていく予定です。)
使う言語はpythonを使用します。
今回は自然言語処理の最初のステップである「形態素解析」を実際にしていこうと思います。
※実践から入りたい方は③からどうぞ!
①形態素解析のおさらい
文章を最小構成の単語(これを形態素といいます)に分けてばらばらにして、それぞれの単語に品詞の情報や原型の単語などの情報を付与する方法です。
詳しくは以下からどうぞ
②形態素解析のライブラリの種類
形態素解析をする際に使用するpythonのライブラリは結構あります。
大体は
・MeCab(めかぶ)
・janome(じゃのめ)
・JUMAN(じゅまん)
・SudachiPy(すだちぱい)
・GiNZA(ぎんざ)
・spaCy(すぺーしー)
etc..
それぞれいろんな特徴がありますが、だいたいネットではMeCabで形態素解析している記事がよく出てきます。
MeCab、janome、JUMANくらいを最初は知っておくと、とっかかりとしては良いと思います。
・MeCab
処理速度も速く、NEologd(ねおろぐでぃー)などの辞書を使えば、最新の新語なども随時追加・更新されているので、精度も十分です。
※難点として、ちょっとインストールにひと癖あるところで、
pip install mecabでドン!みたいにはならないです。しかし、エラーが出ても調べれば出てきますので、そこまで構えなくても問題ありません。
・janome
形態素解析解析だけをとりあえずやりたい!という方は比較的おすすめ。
MeCabに比べ、精度に関しては多少劣るものの、インストールはかなり簡単(pip install janomeでドン!)なため、最初に動かしたいと思ったらすぐにできるのが良い点です。
・JUMAN
MeCabよりも実は歴史が古く、最近はJUMAN++というライブラリも登場しております。
特徴の一つにKNPというシステムが使えることが他にない特徴です。
KNPと(Kurohashi Nagao Parser)というのは、日本語の構文を解析してくれるものです。
係り受け解析であり、文章の各形態素がどのように係り受けされているかを出力してくれます。
実際のサイト
例文を打つと。。

③実際にコードを書いて、形態素解析に挑戦!その1
さっそく始めたいとき、インストールで手間取って萎える、みたいなことにならないように、今回はjanomeを使用して形態素解析の世界に触れてみましょう。
今回は多少の補足説明はしているものの、for文の説明やimportとは?みたいな説明は省いております。
まず初めにコマンドプロンプトやターミナルで
pip install janomeと打って実行すれば、とりあえずインストール完了です。(簡単!)
※私が今回使用するversionは「janome 0.4.1」です。
自分がどのバージョンを使用しているかは、コマンドプロンプトなどで
janome --versionを実行すれば確認ができます~
これが終われば、jupyter notebookなどの普段お使いのnotebookでさっそく書いていきましょう。
まずは、ざっくりとコード全体から
#janomeのインポート
import janome
from janome import tokenizer
#Tokernizerのインスタンス作成
tokenizer = tokenizer.Tokenizer()
#形態素解析したい文字列
sentence = "形態素解析をjanomeで触ってみましたよ!"
#形態素解析を実行!
morphological_analysis = tokenizer.tokenize(sentence)
#実行結果の確認
for text in morphological_analysis:
print(text)それぞれ説明します。
まず、janomeのライブラリをインポートします。
import janome
from janome import tokenizer次に、janomeのtokenizer.Tokenizerでインスタンス化を行います
tokenizer = tokenizer.Tokenizer()次にsentenceの中に形態素解析に用いたい文章を入れて、tokenizeという関数で解析を行います。
sentence = "形態素解析をjanomeで触ってみましたよ!"
morphological_analysis = tokenizer.tokenize(sentence)ちなみに、tokenizer.tokenizeはイテレータのため、for文などで順番に取り出していく必要があります。
※イテレータとは、リストなどの複数の要素やデータを順番に取り出していく機能のようなものと思ってください。
for token in morphological_analysis:
print(token)では、コードを理解したうえで、実行結果を見てみると、

精度はともあれ、形態素解析として、一歩踏み出しましたね!!!
基本的に出力されている情報は左から
・表層形
・品詞
・品詞細分類1
・品詞細分類2
・品詞細分類3
・活用型
・活用形
・読み
・読み
・発音
となります。
ちょっとわかりやすいように、print文を調整して体裁を整えてみました。

例えば、
表層系だけを取り出したいときは、token.surface
原形だけを取り出したいときは、token.base_form
などで抽出できます。
④実際にコードを書いて、形態素解析に挑戦!その2
・分かち書き
文章の品詞などはいらないから、とりあえず形態素ごとに区切りたいときに分かち書きという方法があります。
実際にコードはtokenize関数で解析を行う際に、引数にwakati=Trueと指定すればOKです!
#分かち書きを実行!
wakati_list = tokenizer.tokenize(sentence,wakati=True)
#実行結果の確認
for token in wakati_list:
print(token)では、見てみましょう。
※ちなみに、自分の現行の「janome 0.4.1」では
tokenizer.tokenize(sentence, wakati=True)の返り値はイテレータとなっています(以前まではwakati=Trueと指定すればリスト形式で返ってきてたため、バージョンが違う場合はご注意を!)

いちいちfor文がめんどくさい場合はjoin関数でちゃんとした分かち書きを取得できます。

⑤実際にコードを書いて、形態素解析に挑戦!その3
・辞書の作成
おそらく「形態素」と「解析」が区切られていることにむずむずしていると思います(笑)
そのためには、「形態素解析」という言葉の辞書を作る必要があります
※ちなみにMeCabは辞書の単語追加もひと癖あります。。
janomeには二種類の作成方法がありますが、今回はちゃんとしたユーザー定義辞書を使う方法を採用します。
※ちゃんと知りたい方はjanomeの正式なページを参考にどうぞ!
読みやすいとは思います。
作成方法は(utf-8の)csvファイルを用意して、左から
表層形,左文脈ID,右文脈ID,コスト,品詞,品詞細分類1,品詞細分類2,品詞細分類3,活用型,活用形,原形,読み,発音
の順に追加していけば大丈夫です。
IDなどは具体的な数値はあまり関係なく「-1」で問題ありません(以下のサイトが参考になりました!)
参考までに私が作ったものを添付しております。ご自由に~
では、辞書を読み込ませたうえで再度形態素解析を行ってみましょう。
では、ざっくりとコード全体から。
#janomeのインポート
import janome
from janome import tokenizer
#Tokernizerのインスタンス作成
#辞書の読み込み
tokenizer = tokenizer.Tokenizer("user_simpledic_test3_2.csv", udic_enc="utf8")
#形態素解析したい文字列
sentence = "形態素解析をjanomeで触ってみましたよ!"
#形態素解析を実行!
morphological_analysis = tokenizer.tokenize(sentence)
#実行結果の確認
for token in morphological_analysis:
print(token)変更している箇所は以下の部分のみです。
tokenizer = tokenizer.Tokenizer("user_simpledic_test3_2.csv", udic_enc="utf8")Tokenizer("作った辞書がある場所のパス/辞書の名前", udic_enc="辞書のエンコード指定")
で読み込むことが可能です。
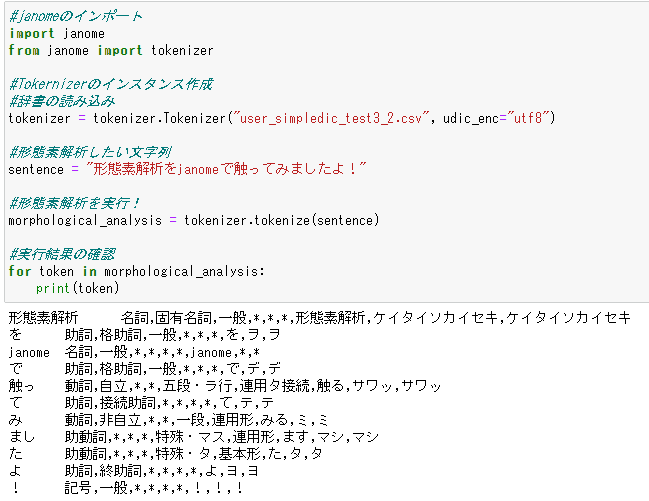
ちゃんと「形態素解析」として認識させることができました!
⑥もう少し踏み込みたいあなたに
・出現した文字のカウント
janomeには実は上記以外にも様々な機能があります。
すべてを網羅的に紹介することはできませんが、今回はそのうちの一つのAnalyzer フレームワークを利用して、ワードカウントを行ってみたいと思います。
たくさんの文章に名詞などの単語がどのくらい出てくるのか知りたい・分析したいと思ったときに役立ちます。
※基本的なフレームワークは公式ドキュメントを参照しております
では、コード全体から
from janome.analyzer import Analyzer
from janome import tokenfilter
text = "今日は天気ですね。そちらの天気はいかがですか?"
#名詞のみに絞り、単語の出現頻度を数える
token_filters = [tokenfilter.POSKeepFilter(['名詞']), tokenfilter.TokenCountFilter()]
#Analyzer実行!
analyzer = Analyzer(token_filters=token_filters)
for key, value in analyzer.analyze(text):
print('%s: %d' % (key, value))まずはAnalyzer フレームワークとtokenfilterのインポートをします(今回名詞のみのカウントをしたいため、tokenfilterをしています。)
カウントしたい文章をtextという変数に格納しています
text = "今日は天気ですね。そちらの天気はいかがですか?"次に、tokenfilter の中のPOSKeepFilterで今回は名詞に絞ってカウント、TokenCountFilterででてきた名詞をカウントしてくれます。
token_filters = [tokenfilter.POSKeepFilter(['名詞']), tokenfilter.TokenCountFilter()]※名詞以外にも動詞や形容詞などもカウントしたい場合は["名詞"]→["名詞","動詞"]のようにリストに要素を追加すればカウントの対象となります。
最後に、Analyzerを実行し、for文で見ていくと完成です。
analyzer = Analyzer(token_filters=token_filters)
for key, value in analyzer.analyze(text):
print('%s: %d' % (key, value))
ちゃんとカウントされていましたね!
・おまけ~ニュース記事で挑戦~
ちょっとだけ派生して、実際のニュースのような記事で頻出単語を調べてみました!
コードの説明は割愛しますが、よかったら参考に!
今回使用したテキストの元はこちら!
上の数行をsample.txtに入れて実際に形態素解析しています!
import re
sample_sentence = []
with open("sample.txt","r",encoding="utf-8") as file:
sample_sentence = file.read()
#少し文章を整形
sample_sentence = re.sub("\n","",sample_sentence)
sample_sentence =sample_sentence.split("。")
sample_sentence
from janome import tokenizer
noun_dict={}
char_filters =[]
#辞書を適用するためにtokenizerを定義
tokenizer = tokenizer.Tokenizer("user_simpledic_test3_2.csv", udic_enc="utf8")
token_filters = [tokenfilter.POSKeepFilter(['名詞']), tokenfilter.TokenCountFilter()]
#Analyzerフレームワークの際に、tokenizerを指定する
analyzer = Analyzer(tokenizer=tokenizer, token_filters=token_filters)
#辞書に順次追加!
for text in sample_sentence:
for key, value in analyzer.analyze(text):
if key in noun_dict:
noun_dict[key] +=value
else:
noun_dict[key] =value
#頻出順にソート
noun_dict = sorted(noun_dict.items(), key=lambda x:x[1], reverse=True)
noun_dict(※ちなみに単語はあらかじめ辞書登録しています)

上位に呪術廻戦が出てきたりタワーレコードが出てきました!
それでは、次回もまた自然言語処理に必要なコードなどを実践していきたいと思います
それでは~
この記事が気に入ったらサポートをしてみませんか?