Swiftでいこう! - Core ML

Swiftで機械学習です。
Core MLを使って、機械言語モデルをAppに統合します。Core MLはすべてのモデルを統一された方法で扱えます。Appは、Core ML APIとユーザーデータを使用して、予測の作成、モデルのトレーニングや微調整をすべてユーザーのデバイス上で行います。
Core ML modelを作ってそれをアプリに利用します。何よりも学習などを手軽にできる以下、Create MLアプリがあるのでとても簡単。
機械学習の専門知識がなくても、機械学習モデルを構築、トレーニング、デプロイすることができます。
今現在、Pythonなどで作ったトレーニング済みモデルがあれば変換して使えるようにします。
学習ずみモデルを用意してあるので試すのも簡単です。
簡単にPlaygroundでやっているのが以下のサイト。これ簡単。コピペでうまくいきます。アップルが用意しているモデルを使って画像認識させています。ちょっと手を加えて実行してみました。
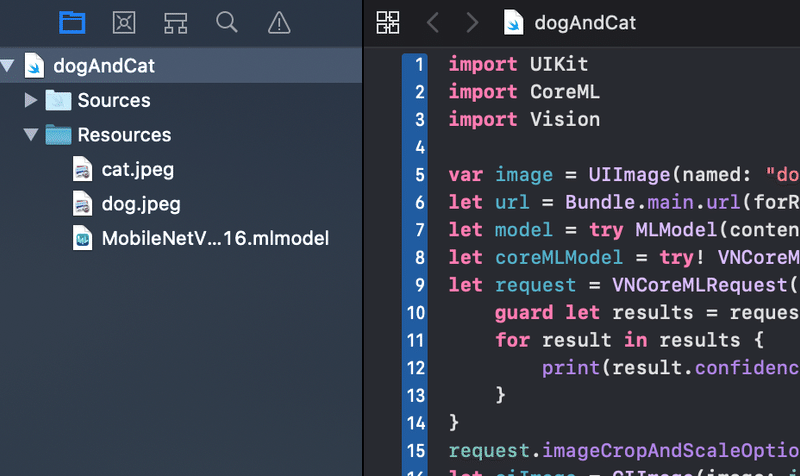
import UIKit
import Vision
var image = UIImage(named: "dog.jpeg")!
let url = Bundle.main.url(forResource: "MobileNetV2FP16", withExtension: "mlmodel")!
let model = try MLModel(contentsOf: url)
let coreMLModel = try! VNCoreMLModel(for: model)
let request = VNCoreMLRequest(model: coreMLModel) { request, error in
guard let results = request.results as? [VNClassificationObservation] else { return }
for result in results {
print(result.confidence * 100, result.identifier)
}
}
request.imageCropAndScaleOption = .centerCrop
let ciImage = CIImage(image: image)
let handler = VNImageRequestHandler(ciImage: ciImage!)
do {
try handler.perform([request])
} catch {
print(error)
}var image = UIImage(named: "dog.jpeg")!
動物の写真は犬、猫その他の動物なんでも良いですが、試したのは犬(dog.jpeg:ゴールデンレトリバー)です。
let url = Bundle.main.url(forResource: "MobileNetV2FP16", withExtension: "mlmodel")!
これが大事です。アップルの開発者サイトでダウンロードできます。
これをPlaygroundのリソースフォルダに入れて実行するとうまくいきます。ドラッグ&ドロップで入れることができます。
画像分類させるコードを書いていくのですが、まず必要なものとして、学習させたモデル、この場合だと"MobileNetV2FP16.mlmodel"が必要です。
モデルを用意した上で、そのモデルを使って認識させるコード、VNCoreMLRequest()を実体化させる、使えるようにするコードを書いていきます。
let request = VNCoreMLRequest(model: coreMLModel) { request, error in
guard let results = request.results as? [VNClassificationObservation] else { return }
for result in results {
print(result.confidence * 100, result.identifier)
}
}の部分になります。認識させる要求があると、認識したもの、精度をコンソールに出力します。
そして認識させたいもの、この場合画像ですが、これを認識できるデータに"VNImageRequestHandler()"で変換して、実行するコード
"try handler.perform([request])"を書きます。
let handler = VNImageRequestHandler(ciImage: ciImage!)
do {
try handler.perform([request])
} catch {
print(error)
}ということで大きく分けて2つ、学習ずみのモデルの処理と認識した画像の処理をすることが必要です。
実際に実行してみると、
92.06034 golden retriever
0.87132967 Labrador retriever
0.8220501 Brittany spaniel
0.62791127 cocker spaniel, English cocker spaniel, cocker
・
・
・
92%ゴールデンレトリバーと出てきました。
この記事が気に入ったらサポートをしてみませんか?