
PyTorchでDeep Learning実装。- 学習

https://note.com/dngri/n/n16991ef1f828
の続きです。まず流れですが、
クラスの実体化、データを読み込み、そして訓練(tranning),テスト(test)としていきます。最後にはグラフで学習率を可視化しています。
ネットワーク、データが用意できたので学習させる実行部分です。最初に基本的なものを決めていきます。学習回数、保存用の変数、ネットワークの実体化と変数にデータを読み込んでおきます。
if __name__ == '__main__':
# 学習回数
epoch = 20
# 学習結果の保存用
history = {'train_loss': [],'test_loss': [],'test_acc': [],
}
# ネットワークを構築
net: torch.nn.Module = MyNet()
# MNISTのデータローダーを取得
loaders = load_MNIST()最適化にはAdamを使います。
optimizer = torch.optim.Adam(params=net.parameters(), lr=0.001)最適化について詳しくは
for e in range(epoch):
です。for in ループで先に定義している回数"epoch"回繰り返し処理します。
ループの中身ですが、訓練(Trainnning)します。
net.train(True)
for i, (data, target) in enumerate(loaders['train']):
data = data.view(-1, 28*28)
optimizer.zero_grad()
output = net(data)
loss = f.nll_loss(output, target)
loss.backward()
optimizer.step()data.view()は1つ目の引数に-1を入れることで、2つ目の引数で指定した値にサイズ数を自動的に調整してくれます。詳細については以下参照。
optimizer.zero_grad()では保持しているデータを初期化します。詳細については、以下参照。
loss = f.nll_loss(output, target)
loss.backward()
optimizer.step()
で損失関数を使い微分、適正な勾配に更新します。
更新については以下を参考に。
次にテスト(Test)します。
net.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in loaders['test']:
data = data.view(-1, 28 * 28)
output = net(data)
test_loss += f.nll_loss(output, target, reduction='sum').item()
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= 10000全体のコードでについては最初に紹介した参考サイトにあります。ログの出力部分が追加で記述してあります。
" epoch = 2"として実行したので、
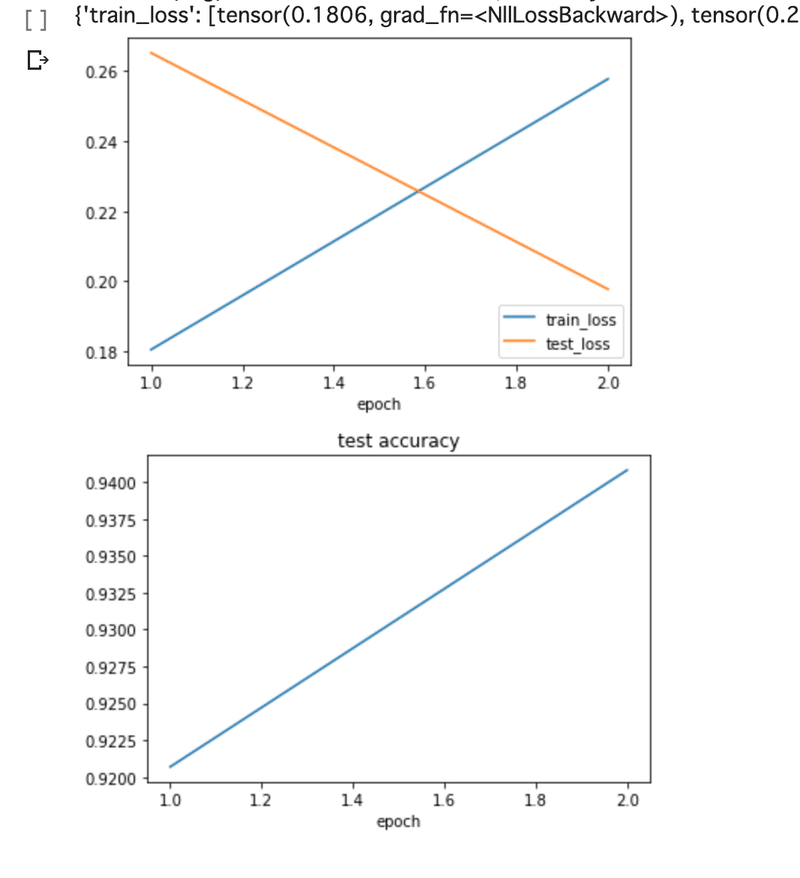
ロスが大きいですが94%ぐらいにまで精度が上がっているようです。
以下にも参考サイトを貼っておきます。さらに理解が深まります。
この記事が気に入ったらサポートをしてみませんか?