
【競馬AI開発#12】競馬予想AIには何年間のデータを学習させるべきか?

この【競馬AI開発】シリーズでは、競馬予想AIを作ることを通して、機械学習・データサイエンスの勉強になるコンテンツの発信や、筆者が行った実験の共有などを行っていきます。
■今回やること
今回は、機械学習モデルに学習させるデータを追加するためのコードを整えると同時に、データ量による精度を比較し、何年分のデータを学習に使用するのが最適なのか?検証していきます。
【実験設定】
・検証データ:2023年の1年間のレース
・学習データ:以下4つを比較
- 2022年の1年間のレース
- 2020~2022年の3年間のレース
- 2018~2022年の5年間のレース
- 2014~2022年の9年間のレース
機械学習ではこのように、一部のデータを学習させずに検証用とすることで、未知のデータに対する予測シミュレーションを行います。

■ポイント
データの追加ですが、一見するとただ追加すれば良いように思えます。
しかし、しっかりコードを整えておかないと、すぐに以下のような状況に陥ります。
使うテーブルをうまく更新できず、重複が発生したり一部のデータが欠損したりする
結果の比較がうまくできず、データを増やした結果精度が上がったのか分からなくなってしまう
データ追加前の結果が再現できなくなってしまう
今回のコードが完成すると、以下のように使用したい期間を指定するだけで一発でデータの追加ができるようになります。
population = create_population.create(from_="2018-01-01", to_="2023-12-31")もちろん、元の「2023年の1年間を使う状態」に戻すこともできます。
population = create_population.create(from_="2023-01-01", to_="2023-12-31")このように、本シリーズでは、一度きりの「機械学習で競馬予測してみた」で終わるものではなく、本格的に運用できる競馬予想AIの作成を目指し、ソースコードを解説付きで公開しています。
ソースコードは下に進むとダウンロードできますので、解凍してお使いください。
■動画(概要編)
■データ追加の流れ
ここからの内容は、動画(概要編)の2:04〜でも詳しく解説しています。
まずは、追加分のデータをnetkeiba.comからスクレイピングします。
学習時のデータの処理を復習しておくと、以下のような流れになっているのでした。
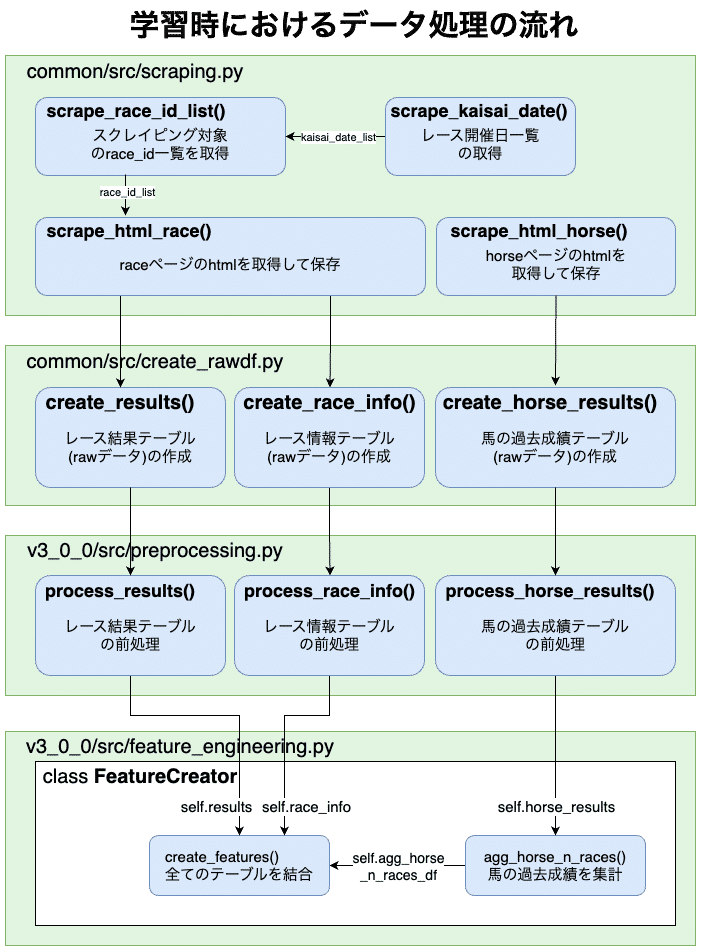
▼ディレクトリ構成
(詳細はソースコード中のREADME.md参照)
.
├── requirements.txt ・・・必要なライブラリを記載
├── README.md ・・・ディレクトリ構成を記載
├── common
│ ├── data
│ │ ├── html
│ │ │ ├── race
│ │ │ │ └── {race_id}.bin ・・・スクレイピングしたraceページのhtml
│ │ │ └── horse
│ │ │ └── {horse_id}.bin ・・・スクレイピングしたhorseページのhtml
│ │ ├── rawdf
│ │ │ ├── results.csv
│ │ │ ├── horse_results.csv
│ │ │ ├── horse_results_prediction.csv
│ │ │ ├── return_tables.csv
│ │ │ └── race_info.csv
│ │ ├── mapping ・・・カテゴリ変数から整数へのマッピング
│ │ └── prediction_population ・・・予測母集団
│ └── src
│ ├── create_rawdf.py ・・・htmlをDataFrameに変換する関数を定義
│ ├── main.ipynb ・・・コードを実行するnotebook
│ ├── dev.ipynb ・・・開発用notebook
│ └── scraping.py ・・・スクレイピングする関数を定義
├── v3_0_0
├── v3_exp1
└── v3_0_1
├── data
│ ├── 00_population ・・・学習母集団を保存するディレクトリ
│ │ └── population.csv
│ ├── 01_preprocessed ・・・前処理済みのデータを保存するディレクトリ
│ │ ├── horse_results.csv
│ │ ├── horse_results_prediction.csv
│ │ ├── return_tables.pickle
│ │ ├── results.csv
│ │ └── race_info.csv
│ ├── 02_features ・・・全てのテーブルを集計・結合した特徴量を保存するディレクトリ
│ │ └── features.csv
│ ├── 03_train ・・・学習結果を保存するディレクトリ
│ │ ├── model.pkl ・・・学習済みモデル
│ │ ├── evaluation.csv ・・・検証データに対する予測結果
│ │ └── importance.png ・・・特徴量重要度
│ └── 04_evaluation ・・・検証データに対する精度評価結果を保存するディレクトリ
└── src
├── dev.ipynb ・・・開発用notebook
├── main.ipynb ・・・コードを実行するnotebook
├── create_population.py ・・・学習母集団を作成する関数を定義
├── preprocessing.py ・・・/common/rawdf/のデータを前処理する関数を定義
├── feature_engineering.py ・・・機械学習モデルにインプットする特徴量を作成するクラスを定義
├── train.py ・・・学習処理を行うクラスを定義
├── evaluation.py ・・・モデルの精度評価を行うクラスを定義
└── prediction.py ・・・予測処理を行う関数を定義もし今回初めて来て同じように流れを追いたい方は、先に2023年データを作成しておいてください。
ソースコード(本記事の一番下からダウンロードできます)中のmain.ipynbを上から実行すれば、そのまま作ることができます。
▼common/src/main.ipynb
import pandas as pd
import scraping
import create_rawdf
import create_prediction_population
%load_ext autoreload
↓↓↓以下のコードまで、セルを順に実行↓↓↓
# 馬の過去成績テーブルの作成
horse_results = create_rawdf.create_horse_results(html_paths_horse)ここからは「2023年の1年間分のrawデータが既に存在する」前提で話を進めます。
まずは図の一番左上の「レース開催日一覧の取得」の部分から実行していきましょう。
ここでは、データ追加コードの挙動確認用に、2022年1月に絞って開催日を取得していきます。
▼common/src/main.ipynb
(動画のように別ファイルにコピーして使用しても良いです)
import pandas as pd
import scraping
import create_rawdf
import create_prediction_population
%load_ext autoreload
kaisai_date_list = scraping.scrape_kaisai_date(from_="2022-01", to_="2022-01")scrape_kaisai_date()の詳細や作り方については、以下の記事で詳しく解説しています。
次に、「スクレイピング対象のrace_id一覧取得」の部分です。
▼common/src/main.ipynb
# 一時保存ディレクトリ
TMP_DIR = scraping.DATA_DIR / "tmp"
race_id_list = scraping.scrape_race_id_list(kaisai_date_list, save_dir=TMP_DIR)scrape_race_id_list()の詳細は、以下の記事で詳しく解説しています。
取得したレースidを元に、レース結果ページのhtmlをスクレイピングしていきます。ただし、全て取得しようとすると時間がかかってしまうので、ここではサンプルとして5レース分だけ取得します。
▼common/src/main.ipynb
html_paths_race = scraping.scrape_html_race(
race_id_list=race_id_list[:5], skip=False
)このあたりの流れについては、以下の記事で詳しく扱っているので、この記事では省略します。
このhtmlを元にレース結果テーブルのrawデータを作成しますが、そのまま実行すると今あるresults.csvを上書きしてしまうため、以下のように別ファイル名を指定します。
▼common/src/main.ipynb
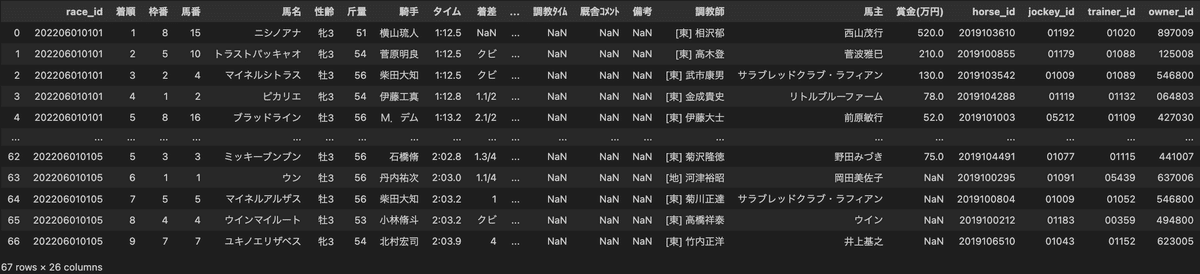
results = create_rawdf.create_results(
html_path_list=html_paths_race, save_filename="results_new.csv"
)
次に、resultsテーブルのhorse_id列の馬について、過去成績ページのhtmlをスクレイピングします。
▼common/src/main.ipynb
horse_id_list = results["horse_id"].unique()
html_paths_horse = scraping.scrape_html_horse(
horse_id_list=horse_id_list, skip=False
)このあたりの作り方は、以下の記事で詳しく解説しています。
さて、ここからがポイントですが、rawデータ作成の際に元のresults.csvやhorse_results.csvに重複が起きない形でデータ追加できるよう、create_rawdf.pyにupdate_rawdf()を作成し、元々to_csv()で保存していた部分を、自作のupdate_rawdf()に置き換えます。
▼common/src/create_rawdf.py
def create_results(
html_path_list: list[Path],
save_dir: Path = RAWDF_DIR,
save_filename: str = "results.csv",
) -> pd.DataFrame:
"""
raceページのhtmlを読み込んで、レース結果テーブルに加工する関数。
"""
dfs = {}
for html_path in tqdm(html_path_list):
# 省略
concat_df = pd.concat(dfs.values()) # 新たに作成したrawデータ
update_rawdf(concat_df, key="race_id", save_filename=save_filename)
return concat_df
def create_horse_results(
html_path_list: list[Path],
save_dir: Path = RAWDF_DIR,
save_filename: str = "horse_results.csv",
) -> pd.DataFrame:
"""
horseページのhtmlを読み込んで、馬の過去成績テーブルに加工する関数。
"""
dfs = {}
for html_path in tqdm(html_path_list):
# 省略
concat_df = pd.concat(dfs.values()) # 新たに作成したrawデータ
update_rawdf(concat_df, key="horse_id", save_filename=save_filename)
return concat_df
def update_rawdf(
new_df: pd.DataFrame,
key: str,
save_filename: str,
save_dir: Path = RAWDF_DIR,
):
"""
既存のrawdfに新しいデータを追加して保存する関数。
"""
if (save_dir / save_filename).exists():
old_df = pd.read_csv(save_dir / save_filename, sep="\t", dtype={f"{key}": str})
# 念の為、key列をstr型に変換
new_df[key] = new_df[key].astype(str)
df = pd.concat([old_df[~old_df[key].isin(new_df[key])], new_df])
df.to_csv(save_dir / save_filename, sep="\t", index=False)
else:
new_df.to_csv(save_dir / save_filename, sep="\t", index=False)
こうすることで、追加でスクレイピングした場合は既存のファイルを更新し、指定したファイル名のファイルがまだ存在しない場合は新しいテーブルとして作成することができます。
このあたりは動画で詳しく解説しているので、適宜参考にしてください。
▼common/src/main.ipynb
# create_rawdfモジュールの更新を反映
%autoreload
# レース結果テーブルを更新
results = create_rawdf.create_results(html_path_list=html_paths_race)
# レース情報テーブルを更新
race_info = create_rawdf.create_race_info(html_paths_race)
# 馬の過去成績テーブルを更新
horse_results = create_rawdf.create_horse_results(html_paths_horse)各ファイル、新たに取得したデータが追加されているか確認してみてください。
5年分のデータ追加の実行コード
これで新しくデータを追加してrawデータを更新する体制が整ったので、実際に2018年〜2022年のデータを追加していきます。
注)動画中のコードのままでは2018年のデータで一部エラーが発生する箇所があるので、本記事のコードに修正してください
定期購読をすると、今月の記事に加えて上で紹介した#1〜#4の記事が980円で全て読めるので大変お得です。
▼common/src/create_rawdf.py(修正版)

この記事が気に入ったらサポートをしてみませんか?