
けんちゃんのAI Quest攻略日記#15「ハンズオン講座(Day2)を開催しました」

こんにちは!デジテック運営事務局のケンタです。
本日は、やまぐちAI Questの開始から452日目です。攻略日誌もようやく15回目を迎えました。今回は、8月27日(土)にY‐BASEで開催したやまぐちAI Quest「ハンズオン講座」Day2の様子をお伝えします。
開催から1ヶ月近くが経過していますが、決してサボっていた訳ではありません。なるほど!と私なりに講座内容を理解して文章にするにはこれくらいの時間が必要だったのです。皆さんカルガモ親子の引っ越しを見守るようなやさしい目で応援していただけると嬉しいです。
【Day2】カリキュラム
9:40~11:10 実験してみよう!
11:10~12:00 Callback
13:00~13:30 Data Augmentation
13:30~14:00 転移学習
14:10~16:20 コンペチュートリアル
15:10~16:20 ワーク
16:20~16:30 まとめ
前回のおさらい

本講座では、画像処理の基礎とDeep Learningのキホンを理解して、Kerasを使った簡単な実装力とチューニング手法の習得を目標とします!
今回の講座では2つの課題が設定されています。
1つ目は、コンペ「画像ラベリング(20種類)」に挑戦します。
画像分類の課題に対して、何をすれば精度が上がるのか?たくさん試行錯誤して画像分類モデルの精度向上を目指します。
2つ目は、画像分類に関する自由研究に取組みます。
ご自身で画像分類に関するテーマを決定し、データを集め、画像分類モデルを作成して精度向上を目指します。最後に成果を発表いただきます。
(例:ダンゴムシとワラジムシの分類、男性と女性の分類など。)
実験してみよう!

まず、前回の復習も兼ねてディープラーニング実装のキホンを学びます。
好きな課題を選択してそれぞれチューニング方法を実験してみます。
①学習率を変更したときの違いを見てみる
(学習率:誤差が最小となる大域最適解を探索するための振り幅)
②活性化関数を変更したときの違いを見てみる
(活性化関数:入力信号に対しどのように活性化させるかを決める関数)
③オプティマイザーを変更したときの違いを見てみる
④層を深くしたときの違いを見てみる
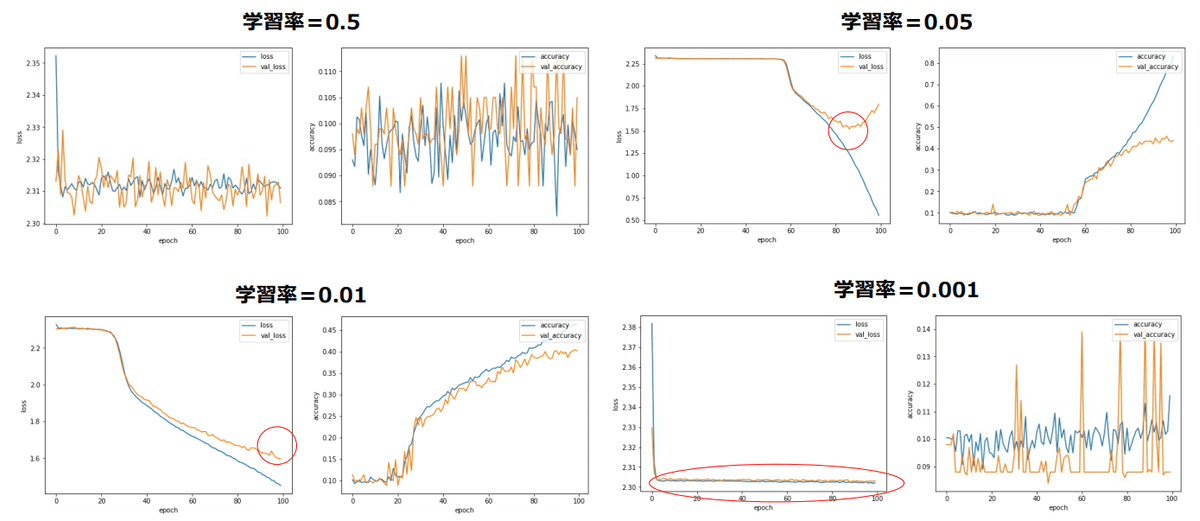
上図は、学習率を変化させた場合の例です。
学習率0.5では学習が全く進まずに精度はグチャグチャ。0.05ではエポック数80付近でようやく学習開始。0.01にすると少し早く学習が進みますが、0.001まで下げると全く学習が進んでいません。
学習率を小さくすると学習は進み易いが、その分多くのエポック数が必要となり、収束まで時間が掛かる!パラメータによって学習率をしっかりとみる必要がある!という実験でした。
Callback

次に、Callbackについて学習します。学習中モデルに対して何らかの関与をしたいときに利用する非常に便利な機能です。
学習途中で学習率を変更したいとき(Learning Rate Scheduler)、学習途中のモデルを保存したいとき(Model Checkpoint)、過学習が始まったら自動的に学習を止めたいとき(Early Stopping)などに利用します。
Data Augmentation
続いて、Data Augmentation(データオーギュメンテーション)です。
ディープラーニングの精度向上には、データの豊富さがカギとなります。
そこで、学習データを水増しして画像パターンを増やし、汎化性能を上げることで精度の向上を狙います。このような、実際のデータに下駄を履かせる作業のことをData Augmentation(データ拡張)と言います。
KerasではImage Generatorを利用して、画像回転、平行移動、反転、明暗転など、簡単にデータを嵩上げすることができます。


転移学習
最後に、ディープラーニングでよく使われる転移学習の実装です。
転移学習とは、ある領域(ドメイン)で学習させた知見・モデルを別の領域に適応させて使い回す技術のことを言います。
学習済みのモデルを有効活用することで、限られた教師データでも高精度なモデルを得ること、学習の収束が早くなることが期待できます。
転移学習には2つのパターンがあります。
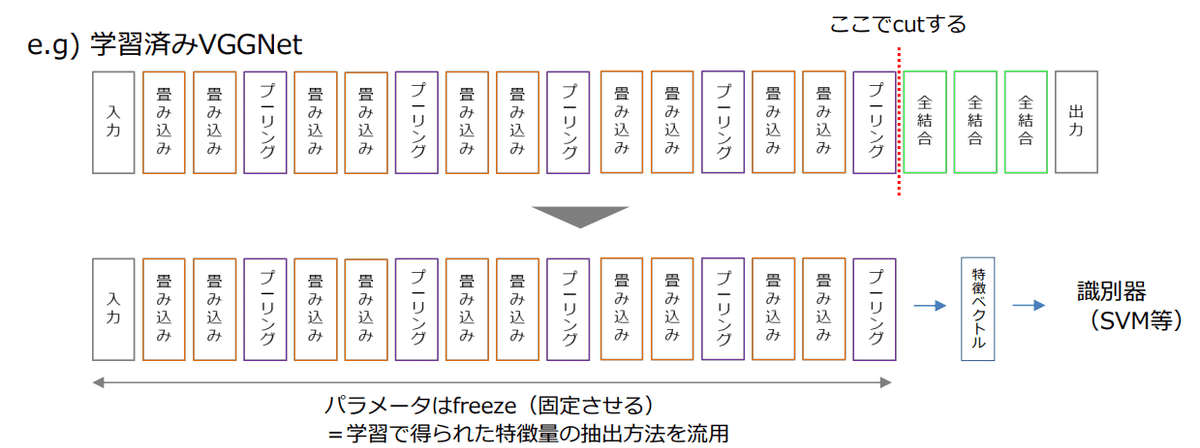
1つ目は、特徴量抽出器として使用します。ディープラーニングでは画像の特徴を学習しています。なので、画像の特徴だけ取り出して、後は分類問題にしてしまえば精度が上がるだろう!という考え方です。
学習済みモデルVGGNetの場合、後半のイメージネットを予測する部分をカットして前半部分だけをパラメータ固定のまま利用すると、画像の特徴を表す特徴ベクトルが抽出されます。この特徴量を使用して別の機械学習器で分類問題を解く、というのが転移学習パターン1です。
2つ目は、Fine Tuningです。学習済みモデルから、学習済み部分のパラメータを新しいデータを使用してある程度チューニングし直します。その際、どの層のパラメータまで再調整するのかが重要となります。入力層近くまで再調整すると事前学習の恩恵が無くなり、出力層近くのみの再学習であれば事前学習データに引っ張られる。というのがパターン2になります。

まとめ/Day3までのお願い

本日は、ディープラーニングの基本チューニング手法、Callback機能、データ拡張、転移学習についての講義。その後は各自ワークとなりました。
次回は、いよいよ成果報告会となります。
これまでに学習したチューニング手法は、次回舞債までの2ヶ月間、コンペ課題「画像ラベリング(20種類)」に挑戦する中で、何をすれば画像分類の精度が上がるのか、実際に試行錯誤することで身に付けていただきます。
報告会では、取組内容やスコア変遷、工夫した点や苦戦した点、今回の講座で学んだ点、などについて発表していただきます。
また、もう1つの課題「自由研究」についても発表いただきます。
・課題テーマ(何を入力として、何を予測する課題か?)
・テーマの選定理由
・データに関する説明(収集方法、画像サイズ、予測ラベルの説明など)
・予測結果(精度だけでなく、実際に予測したサンプルなど)
・考察(良い例、悪い例からどんなことが言えるかなど)
・今後、もっと試したいことやお仕事で活かせるなと考えられること
など報告してください。と説明したところで、本日の講座は終了です。

あとがき・次回予告
前回同様、内容の濃い1日でした。
色々な画像処理が出来て面白い!楽しそうだな~!と思いながら私も会場の端で聴講させていただきました。
自由研究の課題は、皆さん個性的で面白そうなテーマを考えておられるようです。どのような発表になるのか報告会が楽しみです。と思いつつ、今回はこのあたりで終わりとさせていただきます。
最後までお読みいただきありがとうございました。
「ハンズオン講座(Day3)」は、10月22日(土)に開催します。
次回は、その様子をお伝えする予定です。どうぞご期待ください。