
CATE推定のためのCausal Treeの仕組み

この記事について
電通デジタルでデータサイエンティストをしている中嶋です。この記事では統計的因果推論で出てくるConditional Average Treatment Effect (条件付き平均処置効果、以下CATEと略記します)を算出する手法の一種であるCausal Tree(因果木)の仕組みを論文[1]に沿って解説します。前提知識として、機械学習手法の決定木の概要と因果推論の基本的なフレームについて理解している必要があります。
CATEについて
最初に今回の手法で推定する対象となるCATEの定義を与えます。そのために記号の準備を行います。
記号の準備
今回扱うデータセットのサンプルサイズは N 件とし、各標本を i (=1,..,N) で表します。各標本に対する処置変数をWiで表し、Wi=1を処置ありの介入群、Wi=0 を処置無しの対照群とします。(Yi(1),Yi(0))を標本i に対する潜在結果変数の組とし、この差として標本ごとの潜在効果を τi=Yi(1)−Yi(0) と定義します。結果変数の実現値は以下のように表されます。
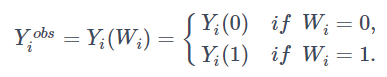
また、推定に使うXi は処置有無Wiの影響を受けない、K次元ベクトル特徴量とします。
CATEの定義
この後紹介するCausal treeで推定するCATEとは下記の式で定義される量で、変数Xで条件付けた局所的な因果効果を表します。
![]()
実務においては、マーケティングや広告などの文脈でABテストで施策を打つ時に、全体としての施策効果(いわゆるATE)のみならず、どのユーザーセグメントに最も効果があったかまでをCATEによって把握することができます。それにより、その後の施策検討時にターゲットセグメントを考える上で非常に役に立ちます。
以降はこのCATEを推定する方法を考えます。
CATEの算出方法について
CATEの算出に際しては、取り扱うデータの前提としてRCT(ランダム化比較試験)を行った上で推定するものと、バイアスを含む観測データから推定するものがあります。前者についてはuplift modelingの文脈で研究が盛んに行われており、test群/control群ごとにモデルを作成するTwo-Model Approachという手法があります。(Two-Model Approachについては弊社のこちらの記事でBigQueryによる実装を紹介しています。)後者については計量経済学の分野で研究されており、Microsoft Reserchが開発したEConMLというパッケージに含まれるMeta-Learners等が有名です。
今回は前者のRCTデータを扱ったCATE算出を扱い、Causal treeによる方法を説明します。この手法はTwo-Model ApproachではなくModeling Uplift Directlyというアプローチになります。これは決定木のようなメジャーな機械学習アルゴリズムを用いてCATEを直接推定するものです。
Causal treeについて
最初に今回説明するCausal treeに関してデータに要求する仮定を整理します。
データセットの仮定
Causal treeでは対象となるデータに下記の前提をおきます。
・(Yi^{obs}, Wi, Xi) は母集団からの i.i.d (独立同分布の)サンプルとする。(obsはobservation(観測)の略)
・Wiによる割付は無作為化されているか、もしくは次の式が成り立つ。
![]() つまりXi で条件付けたときに処置変数 Wi と潜在結果変数 (Yi(1),Yi(0)) は独立であるということである。
つまりXi で条件付けたときに処置変数 Wi と潜在結果変数 (Yi(1),Yi(0)) は独立であるということである。
アプローチ
Causal treeによるCATE推定のイメージとしては、決定木を作った時の各葉に含まれるデータはXiの性質が似通っていることから、その中で処置群と対照群を比較することでCATEが求められるという考え方です。

そして、この考え方を数式で表現します。
設定
まず、Treeモデルから得られるデータセットの分割をΠと定義します。
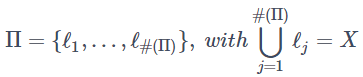
各 ℓj が木の末端の葉を表し、 #(Π)は分割された葉の数となります。XはK次元の特徴量空間を表しています。また、x∈Xに対して
![]()
とし、葉 ℓ(x;Π) における条件付平均関数を
![]()
と表します。これをサンプルデータセットSによって推定すると、不変推定量として
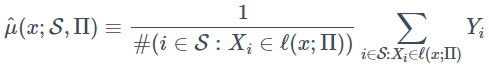
が得られます。ここまでは処置変数Wiが無かったのでここにWiを加えます。
分割Π 及び x,w が与えられたとき、葉 ℓ(x;Π) におけるYi(w)の期待値を
![]()
とします。この時、葉 ℓ(x;Π) におけるCATEは
![]()
となります。これをサンプリングしたデータS から推定するには、S_w={i∈S|Wi=w}として
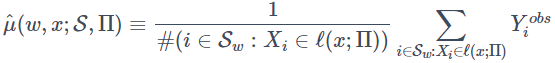
によって行い、これを用いて葉 ℓ(x;Π) 内でのCATEを
![]()
と定式化することができます。この推定量は不偏性を持つので
![]()
が成り立ちます。
ここからはこの ^τ を推定する方法を説明します。それにあたりCausal treeが通常の決定木と異なる点を紹介します。
データセットの使い方
通常の決定木では、最初にデータセットを学習用とテスト用に分けます。そして学習用データセットからから更に検証用データセットを切り出しクロスバリデーションを用いてモデリングを行います。この場合ツリーの作成と葉内の推定を同じ学習用データセットで行うことになります。
一方、Causal treeではこのデータの使い方ではバイアスがあるとして、次のような方法が提案されています。それはツリーの作成時及びそれによって得られる各葉ごとの推定時に使うデータをS^{tr}, S^{est}と異なるデータに分けて行うというものです(上付き添え字はそれぞれtrainとestimateの略)。図にまとめると下記のようになります。

ではなぜCausal treeではこのようなデータセットの使い方をするのでしょうか?それは、ツリーの作成と、各葉における推定に同じデータを用いる場合、葉内の推定がデータに含まれる外れ値に大きく影響されてしまうからです。データに含まれるノイズに対して、ツリーの作成時にはそれも込みでデータの性質と捉えて分割の閾値を決定してしまうので、分割後の葉内のY平均は同じデータを使う限りそのノイズの影響が乗ったものになってしまうということです。
Causal treeではこの対策としてデータを三つに分けたうえで、回帰木の最適化指標であるMSEにも改良を加えています。
最適化指標の修正
学習用データS^{tr}から作成した木によってある分割Πが与えられているとき、S^{est} による推定値を用いたテストデータS^{te}に対する平均二乗誤差を
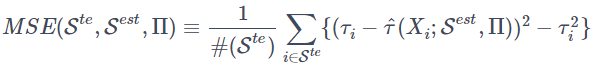
と定義し、Causal treeではこれを最適化指標として学習を行います。ここで右辺のτiは標本 i の潜在処置効果を表します。通常の機械学習と異なりこの値は本来観測できないものですが、後述の計算ではこれを観測可能な値で推定します。また式中の最後の項 τ_i^2 は本来不要な項ですが、のちの説明の都合上入れています。そしてこの最適化指標の特徴を調べるためにEMSE(Expected MSE 期待平均二乗誤差)を定義します。
![]()
以降このEMSEを解析してCausal treeが何を最適化しているのかを説明します。

ここで、最後の式の第二項について、τ(x;Π)=E_S[^τ(x;S,Π)] を使って S^{est}に関する期待値を先に計算すると
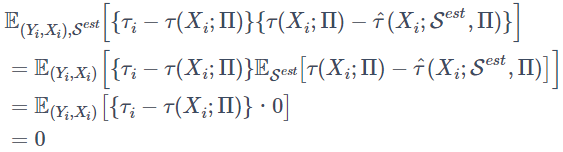
となります。よって、(1)式は第一項の期待値の中身の二乗を展開すると
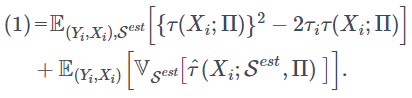
そして、
![]()
であることを踏まえると、結局

となります。
この式の第一項はCATEの二乗の期待値となっており、これが大きいほど作成したツリーの分割Πを高く評価します。また、第二項はCATEの分散の期待値となっておりこれが低くなるものを高く評価します。
まとめると、Causal treeでは最初にデータセットを(S^{tr}, S^{est}, S^{te})に分け、それに合わせて導入した新しい最適化指標 MSE(S^{te}, S^{est}, Π) を使って最適化を行います。上記の式変形で見た通り、これはCATE(の期待値)が大きくなるようにしつつ、CATEの分散(の期待値)が低くなるように分割Πを構成します。
実装
RによるCausal treeの実装を紹介します。今回はMineThatData Email-Analytics And Data Mining Challenge DatasetのRCTによりメールマーケティング施策を行ったデータを使用します。
データの前処理はこちらから(ほぼ)抜粋して、男性用メールを受け取ったユーザーとメールを受け取らなかったユーザーのみのデータセットを作成します。また、全体でのメール配信の効果(ATE)として、メール受信有無でconversion_rateを比較します。
# (1) パッケージをインストールする(初回のみ)
install.packages("tidyverse")
# (2) ライブラリの読み出し
library("tidyverse")
# (3) データの読み込み
email_data <- read_csv("http://www.minethatdata.com/Kevin_Hillstrom_MineThatData_E-MailAnalytics_DataMiningChallenge_2008.03.20.csv")
# (4) データの準備
## 女性向けメールが配信されたデータを削除したデータを作成
male_df <- email_data %>%
filter(segment != "Womens E-Mail") %>% # 女性向けメールが配信されたデータを削除
mutate(treatment = ifelse(segment == "Mens E-Mail", 1, 0)) #介入を表すtreatment変数を追加
# (5) 集計による比較
summary_by_segment <- male_df %>%
group_by(treatment) %>% # データのグループ化
summarise(conversion_rate = mean(conversion), # グループごとのconversionの平均
count = n()) # グループごとのデータ数
summary_by_segment
この結果より全体で0.68%分だけconversion_rateが向上していることが分かりました。
次にCausal Treeのパッケージをインストールします。これはdevtoolsを使ってgithubからインストールすることができます。
install.packages("devtools")
library(devtools)
install_github("susanathey/causalTree")RによるCausal treeの実行は下記のようにして行います。causalTreeの関数内にあるsplit.Honestはツリーを作成する際の分割の基準として今回紹介した最適化指標を使うか、通常の決定木と同じ基準を使うかを選択できるものです。論文中では今回紹介した最適化指標による分割をhonest splitting(偽りのない、正直な分割)という呼称で説明されています。その他、関数内で指定するパラメータの詳細についてはCausal treeの元論文の著者(Susan Athey, Guido Imbensら)による説明資料をご参照ください。
X = select(male_df,-11,-13) # conversionとtreatment列を除外
W = male_df$treatment
Y = male_df$conversion
ct <- causalTree( Y ~ ., data=X,
treatment=W, minsize=2000,
split.Rule = "CT", cv.option="CT", split.Honest=TRUE)
rpart.plot(ct)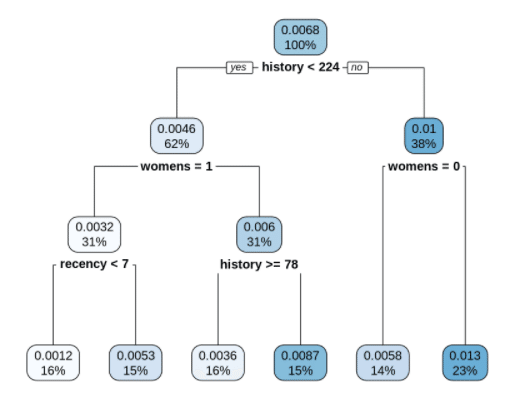
結果の見方ですが、各葉の中で上の数値がCATEを表し、下の数字が全体に対するデータボリュームを割合で表しています。また葉の色が濃いほどCATEが高いことを示しています。最も右下の葉は、
・history(昨年の購入額)が224$未満でない、すなわち224$以上
・womens(昨年に女性向け商品を購入しているか?)が0(=購入していない)でない、すなわち1(=購入している)
です。つまり、昨年の合計購入額が224$以上かつ女性向け商品を購入しているユーザーセグメントとなっており、ここで最もCATEが高いことが分かりました。全体のATEは0.68%であったのに対して、このセグメントは1.3%となっており全体と比べても2倍程度施策効果が大きいことがうかがえます。
最後に
今回は、ランダム化比較試験(RCT)での施策の効果検証分析として条件付き処置効果(CATE)を求める際に使えるCausal tree(因果木)という手法を紹介しました。この手法の特徴として、通常の決定木における学習時のバイアスの問題を指摘したうえで、新しいデータセットの使い方と最適化指標を採用している点を説明しました。また今回は取り上げられませんでしたが、Causal treeを基本学習器としたrandam forestによるCATE推定手法もCausal treeの論文著者(Susan Athey)によって提案されています。是非実務でも使ってみてください。
参考文献
・Causal treeの元論文
[1] Recursive partitioning for heterogeneous causal effects. Susan Athey and Guido Imbens. 2016 PNAS
https://www.pnas.org/content/113/27/7353
[2] 著者によるgithub実装コード
https://github.com/susanathey/causalTree
・Causal treeの解説記事
[3] causal forest & r-learner
https://speakerdeck.com/masa_asa/mian-qiang-hui-zhun-bei-zi-liao-bei-wang-causal-forest-and-r-learner
[4] Causal Treeはどうやって個別の因果効果を推定しているのかを整理(しきれなかった)
https://saltcooky.hatenablog.com/entry/2020/01/17/021448
[5] ランダムフォレストによる因果推論(著:慶応義塾大学 中村 知繁 2020)
https://ies.keio.ac.jp/upload/20201201econo_nakamura_Slide.pdf
・因果推論とuplift modelingの概観
[6] Causal Inference and Uplift Modeling A review of the literature. Pierre Gutierrez and Jean-Yves G´erardy. 2016 JMLR
https://proceedings.mlr.press/v67/gutierrez17a/gutierrez17a.pdf