
独自知識を組み込んだチャットボットを作る - OpenAI + Llamaindex + Gradioで遊んでみる

データミックスの代表の堅田です。シルバーウィークの1日を使って、気になっていたLlamaindexとGradioを触ってみました。
注意
できるだけ平易な言葉で、かつ技術ワードを避けながら記載しています。その結果、厳密性に欠いた説明になっている部分もありますが、ご容赦ください。
いずれのライブラリ・サービスも記事作成時点のものです。それらがアップデートされることで、記載したコードが動かない、有料・無料の変更等が起こり得ますので、ご注意ください。
この記事で紹介するOpen AIのAPIは有料です。事前にクレジットを購入する必要がありますので、ご留意ください。
この記事のゴール
この記事のゴールは以下のような、チャットボットを作ることです。
ご覧いただいた通り、データミックスのことを聞いてもちゃんと答えてくれています。

ちなみに、ChatGPTに、「データミックスでは、どんなことが学べますか?」と聞いたのが、こちらの画面です。もはや、データミックスを、会社とも思われていない回答しか得られません。
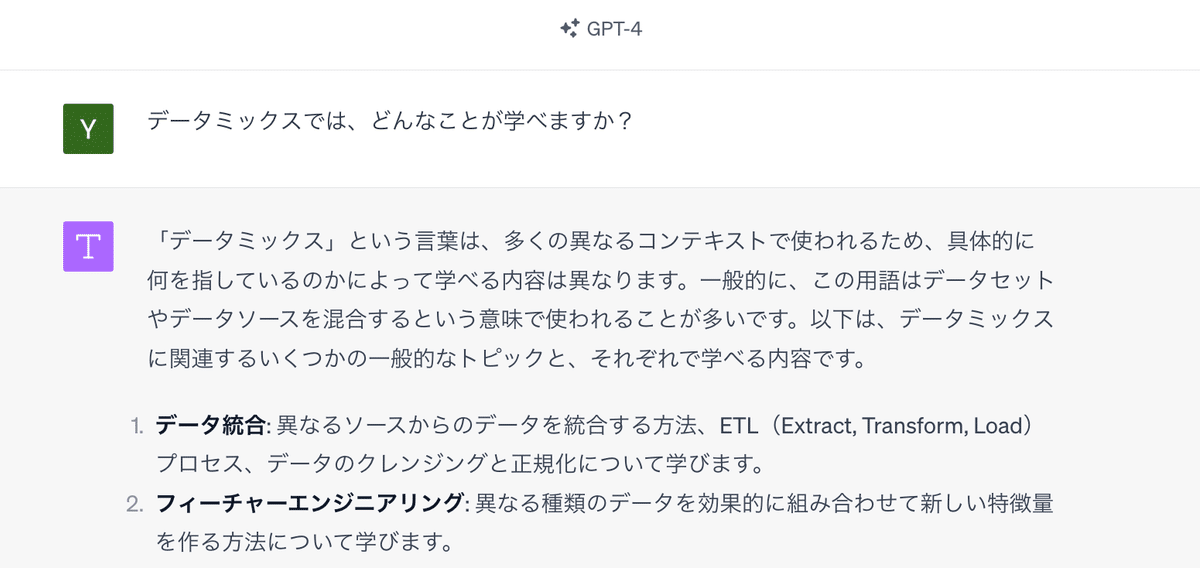
ChatGPTは、大量のテキストを学習し、その学習した文章から、質問に対して適切な文章を生成しているわけなので、データミックスのことはよく知らなくても不思議ではありません。
そうなると、自社の持っている独自の文章データを踏まえて、質問に対する回答を生成してもらいたいと思うわけです。
そこで、登場するのが、Llamaindexです。
Llamaindexとは?
Llamaindexとは、大規模言語モデル(LLM)を拡張させるためのフレームワークです。ウェブサイトによると、以下3つの機能を提供すると記載されています。
Data Ingestion - 自身が持つ多様なデータを外部データとして、LLMに接続する
Data Indexing - Indexとは「目次」のことです。LLMでは大規模データを処理しなくてはならないわけですが、その際に「目次」があったほうが高速に探せます。Llamaindexを使うことで、文書をベクトル化し、インデックスにしてくれます。
Query Interface - プロンプト(質問や命令)を扱うインターフェースも用意してくれています。
ということで、Llamaindexを使うことで、独自の文章データを読み込んだチャットボットなどを作ることも可能になります。
作成手順 - 早速、コードを見ていきましょう
環境は、Google Colabを使います。
ライブラリをインストール & インポート
Colabにはこれから使用するOpenAIやLlamaindexなどのライブラリが入っていませんので、pip installでインストールします。
!pip install llama-index
!pip install openai上記を実行したら、以下のように、ライブラリをインポートします。
import openai
import os
import getpass
from pathlib import Path
from llama_index import download_loader
from llama_index import GPTVectorStoreIndexOpen AIのAPI Keyを取得する
Open AIのウェブサイトにある右上の「Log in」を押して、ログインします。
そして、一番右に「API」というボタンがありますので、そのボタンをクリックします。すると、以下のような画面になります。

右上の自身のアカウント名のあるボタンをクリックし、「View API Key」をクリックします。すると、以下の画面になります。
「Create new secrete key」のボタンをクリックして、好きなKeyの名前を入れましょう(例えば、「my_demo」など)。すると、Keyが生成されますので、そのKeyをコピーして保管します。Key = 鍵ですから、誰かに共有したり、公開したりしないように、注意してください。
ColabからOpen AIへアクセスできるようにする
以下のコードを実行すると、Open AIのAPI Keyを入力するように求められます。上記で取得したAPI keyを入力しましょう。
os.environ["OPENAI_API_KEY"] = getpass.getpass('OpenAI API Key:')
#このコードを入れないと、後でエラーが出る
openai.api_key = os.environ["OPENAI_API_KEY"]独自に保有するPowerPointを読み込む
さて、独自に保有するデータを読み込んでいきます。今回は、データミックスのデータサイエンティスト育成講座、気象データアナリスト養成講座、HRデータアナリスト育成講座の説明会資料を読み込んでいきます(こちらの資料は、datamixのウェブサイトでも公開しています)。
ここで、PowerPointを読み込む必要があるので、Llamaindexでは、PowerPointを読み込むための機能も提供しています。
PptxReader = download_loader("PptxReader")
loader = PptxReader()ちなみに、PowerPoint以外のデータを読み込みたい場合は、Llama hubをみてみましょう。多様なデータを読み込むためのコネクターが多数提供されています。Llama Hubを見ると、slack、salesforce、google calendarなどさまざまなデータコネクタがあります。

話を戻して、PowerPointを読み込んでみましょう。ここで、test_dataフォルダに各種説明会の資料(PowerPoint)をアップロードしてある前提です。
ただし、今後の同一フォルダ内に、PDFなどPowerPoint以外のファイルも入れることを想定して、「PowerPointかどうかを判定する関数」として「check_extension」も作っておきました。
# フォルダ内には様々なファイルがあるので、拡張子がPowerPointかどうかを判定する関数を用意
def check_extension(filename):
_, ext = os.path.splitext(filename)
return ext in ['.ppt', '.pptx']
# test_dataフォルダにあるPowerPointを読み込む
folder_path = "./test_data/"
documents = []
for file in os.listdir(folder_path):
pptx_flag = check_extension(file)
if pptx_flag:
documents += loader.load_data(file=Path(folder_path + file))Indexを作り、質問を投げかける
読み込んだPowerPointで、インデックスを作ります。
index = GPTVectorStoreIndex.from_documents(documents)そして、質問を投げかけるための準備をします。ここでは、Q&A用のquery_engineを使いますが、Llamaindexでは、それ以外に、チャットボット用のchat_engineという機能も提供されています。
query_engine = index.as_query_engine()
ここでは、「データサイエンティスト育成講座の特徴を教えてください」という質問をしてみます。すると、以下のような回答が返ってきました。
response = query_engine.query("データサイエンティスト育成講座の特徴を教えてください")
print(response)
# 以下出力結果
# データサイエンティスト育成講座の特徴は、以下のような点があります。
# 1. 想定受講者は、社内でデータ分析チームへ異動したい方、データサイエンティストとして転職したい方、ゼロから社内でデータ分析チームを立ち上げる際の推進者になりたい方です。
# 2. カリキュラムは、データサイエンスによってビジネス課題を解決する内容であり、ツールの使い方だけでなく、思考の回し方も身につけることができます。
# 3. 学習ゴールは、「自分で答えを作り出す姿勢」「データを見て考え抜く姿勢」を身につけることや、各手法の仮定を理解し、アンチパターンや制約事項を理解することです。
# 4. 学習時間は、毎週3時間の講義(オフライン講義またはオンライン講義)と毎週10時間程度の予習・復習が必要です。初学者の場合は、毎週20時間ほどかかる場合もあります。
# 5. 学習開始は、1月、3月、5月、7月、9月、11月の期入学があります。
# 6. フォロー体制として、Slackで質問投稿が可能であり、オフィスアワーやキャリアサービスも提供されます。
# 7. カリキュラムは予告なく変更されることがあります。読み込ませた文書を使って回答していることがわかります。
Gradioで画面を用意する
Gradioとは、機械学習モデルをデモする際のウェブUIを簡単に作成できるライブラリです。Google Colab上でも動作します。
Gradio is the fastest way to demo your machine learning model with a friendly web interface so that anyone can use it, anywhere!
Gradioをインストールして使ってみましょう
まず、Gradioをインストールします。
!pip install gradioGradioでは今回のようなチャットボットに必要なUIも提供しており、ChatInterfaceを使うと簡単にUIを作成することができます。
import gradio as gr
def inquiry_datamix(message, history):
response = query_engine.query(message)
return response.response
demo = gr.ChatInterface(inquiry_datamix)
demo.launch()上記のコードを実行すると、以下のような画面が立ち上がります。「https://localhost:XXX」のURLをクリックすると、新しいタブが開き、Colab内ではなくウェブアプリ単体で起動します。

私たちは「面白い」と思えば、能動的に継続的に学んでいける。
ここまで、いかがでしたでしょうか?
「難しそう」と思ったかもしれませんが、「面白そう」「役に立ちそう」と思ってもらえたなら、とても嬉しく思います。
そして、AIやデータサイエンスの世界は日進月歩で、全ての技術を深めることは不可能です。そのため、日々の観察から問題を発見し、上手に課題を設定する力が何より大切になります。そして、課題を設定できたら、技術をリサーチして、自分でも触ってみる・やってみる、そこから新しい発見や、別の課題設定を考える、そんなサイクルを回していくことが大事です。
そのサイクルを回す原動力は2つあると思っています。
ひとつは、技術や事例に触れて「面白い!」「自分でもやってみたい!」と感じることだと思っています。
もう一つは、体系的に基礎スキルを身につけていることです。どんなに面白そうだと思っていても、基礎がないと実行することができませんし、学ぶにしても大変です。
データミックスでは、受講生の知的好奇心を引出し、そしてビジネスシーンで実行できるデータサイエンスやAIに関する知識・スキルを身につける講座を行っています。
ご興味を持った方は、ぜひこちらのウェブサイトを見てみてください!
Special Thanks:データミックスのMLエンジニア、データサイエンティスト