
[競馬予想AI] 競馬予想AIをつくる(概要)

競馬予想AIをつくるに当たっての概要についてnoteします。
▼詳細な開発過程はこちらのマガジンに随時追加しています。
なぜ競馬予想AIなのか
なぜ競馬予想を選んだかというと、やはり競馬の予想が難しいという点と、成功した暁にはリターンがありモチベーションがあるという点です。
オープンデータを含み今やネット上で大量のデータに触れることができます。肺疾患者のレントゲン画像データなんてものもあります。このデータから何かを高い精度で診断できるAIが作れたとすればそれは凄いことです。しかし、ドメイン知識の無い我々が医学に関するAIを作ろうとすると必ず限界がありますし命に係わる分野について無責任にかかわることはできません。
その点、競馬は多くの人に親しみがあり、1位を当てれば良いというわかりやすさと、多少の知識は必要となるにせよこれらのAIを作ったことによって誰かの命にかかわることもありません。
また、機械学習界隈の企業では競馬予想AIを社員の技術研鑽の機会として作っているところもあります。
競馬予想AIをつくる
私が今作っているAIについて、どう作っているかとどのくらいの精度なのかという点についてお話していきます。結論から言うと、精度は3割ほどと高くないです。(精度の定義については後ほど)
まだまだ改善の余地があり、試すべき手法はたくさんあるので、ここからどれくらい精度が上がっていくのか楽しみにしていただければと思います。
データの準備
まずはデータ集めです。これが無いと始まりません。
データについては、競馬をやられている方はお気に入りのサイトなどから取得されればよいと思います。取得にはAPIの操作かスクレイピングができる必要があります。
まずは綺麗に取れるデータを中心に取得していきます。綺麗に取れるとは、表形式のデータのようなものですね。レース表などがそれに該当します。データのバリエーションについては、足りないようなら後から追加していくスタイルで良いと思います。スモールスタートの方が時間の無駄にもなりません。
今回は馬に関するデータとレースに関するデータを取得しました。それぞれ100MBと6MBほどです。テキストデータなのでレコード数ほど重くありません。
取得先のサーバに負担がかからないように細心の注意を払います。負荷にならないようにすべてのデータを取得するのに半日ほどかかりました。
データ加工
機械学習モデルに入力するためにデータを整えます。
データを整える際は文字列加工や正規表現が扱えるとすごく便利です。生データは例えば「1600(左)/(ダ)」のようになっているので、「1600」「左」「ダート」と分割する必要があります。
また、統計を取ったり経験則からこういうデータが有用だと思ったものはこの時点で特徴量を作成してもよいです。時間と計算リソースがある場合は「とりあえずこんなデータ使えそうだから作っておくか」くらいのノリで特徴量を増やしておいてもよいかと思います。
データ分析において、ここまでの「データ準備」と「データ加工」に多くの時間と労力を使うことになります。データを持っていて扱うことができる大手企業が有利なのはそういう理由からですね。
学習モデルを作成、学習させる
深層学習ではなく機械学習であれば、データをそのまま入れるとそれらしい出力をしてくれるものはたくさんあります。まずは試してみるのがよいと思います。そこから改善をしていく方針を取ります。
今回のAIではモデルとしてxgboostを使っています。欠損値が多少あってもうまく扱ってくれます。設定するパラメータも神経質に調整する必要もありません。もちろん今後パラメータの調整も必要にはなってきます。このあたりの調整は評価指標を使って調整することになります。
深層学習の場合は、シンプルな構造から試していきます。使用するライブラリにより作り方は異なりますが、レイヤー数やノード数、出力関数、コスト関数等の設定が必要になります。
時には論文を見て適したアルゴリズムを探す必要があるかもしれません。
予測をする
xgboostの出力は確率です。なので0.5以上は1、それ未満は0のように閾値を決定する必要があります。この閾値の設定次第でも精度は大きく変わります。
1着の馬をラベル1、それ以外をラベル0としてラベル1の馬を予測したい場合、このデータは不均衡データとなり適切な評価指標を選択しなければまったく使い物にならないAIになってしまいます。具体的には、すべて「この馬はラベル0」としても正解率は9割を超えてしまいます。この時の混同行列は下の画像になります。
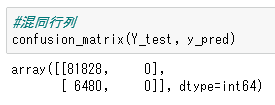
横軸は予測値で左から0, 1、縦軸は正解値で上から0, 1です。正解が1で予測も1であったものは0(全く予測できてない)ですが、この時の正解率は92.7%です。
閾値だけを変更してみます。上の例では0.5でしたが、0.12に変更してみます。結果は下の通りです。
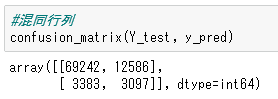
正解は1で予測も1だった数が3,097個と大幅に増えています。しかし、今度は正解は0なのに予測は1としてしまった数が12,586個と大幅に増えてしまいました。閾値を下げすぎたために、0のものも1であると緩い判定をするようになったからです。
この閾値の設定に正解はありません。厳しく判定してもいいのか、緩く判定えもいいのか、これは予測対象の性質によって異なります。例えば、ウィルス検査で陽性の人を陰性だとしてしまっては問題です。顔認証システムで本人以外の人を認証する緩いシステムでは困ります。昨今話題になっているウィルスで偽陽性や偽陰性などの言葉をよく耳にすると思いますが、それがこの問題です。もちろんこの問題は閾値だけが原因ではなく、モデルの性能も関係しています。
混同行列に関する使用として、Precision(適合率)、Recoll(再現率)、F1スコアなどがあります。
モデルの性能をよくしつつ、最後に閾値を調整するのが一般的です。
性能をよくするためのアプローチ
性能向上のためのアプローチはいくつもあります。
まず、データレベルでの改善です。適切な特徴量を増やしたりもう少しデータを増やしてみるなどです。特徴量の選択については回帰問題の場合は相関が薄い変数を削除したり、主成分分析で次元削減を行ったりします。
アルゴリズムレベルでの改善は、データの分布を考慮した適切なモデルの選択やパラメータ調整などがあります。また、複数のモデルを組み合わせたアンサンブル学習という手法があります。これらの手法をうまく組み合わせて性能向上を目指します。
今後の予定
今回はAI開発の概要について紹介しました。次回からはもう少し中身について、どのような施策を試したのかなどについて紹介できたらと思います。また、競馬開催日には少しずつ予想も発表できたらと思いますので楽しみにしていてください。
サポートのお願い
AI作成にあたり、PCリソースや技術習得のための書籍などの費用が必要となるため、もし余裕がございましたらご支援いただけると幸いです。将来は予想結果をお知らせしたり、サポートしていただいた方限定で何かお返しができたらと考えております。
今後とも当noteをよろしくお願い致します。
よろしければサポートをよろしくお願い致します。いただいたサポートは今後の技術向上のために書籍費用等に当てられ、このnoteで還元できればと思います。