
DATAFLUCTの事業を支えるデータレイクとは

皆さん、こんにちは!DATAFLUCTの石田です。
エンジニアとして、データレイクを活用したDATAFLUCT service platform. の開発・運用を担当しています。
service platform は、データの収集・蓄積・加工・活用まで企業のデータ活用をトータルでサポートすることが可能なプラットフォームです。顧客のデータ活用ニーズに合わせて、必要な環境を組み合わせて提供することも可能です。
「データを商いに」(datascience for everybusiness.)をvisionとして掲げるDATAFLUCTでは、膨大かつ多種多様なデータを日々取り扱っています。
データを扱うプラットフォームは、主に以下の階層から構築されており、提供するサービスの構造は4つ(Vertical SaaS/with Partners SaaS/Algorithm as aServide/Data Platform as a Service)に分けられます。
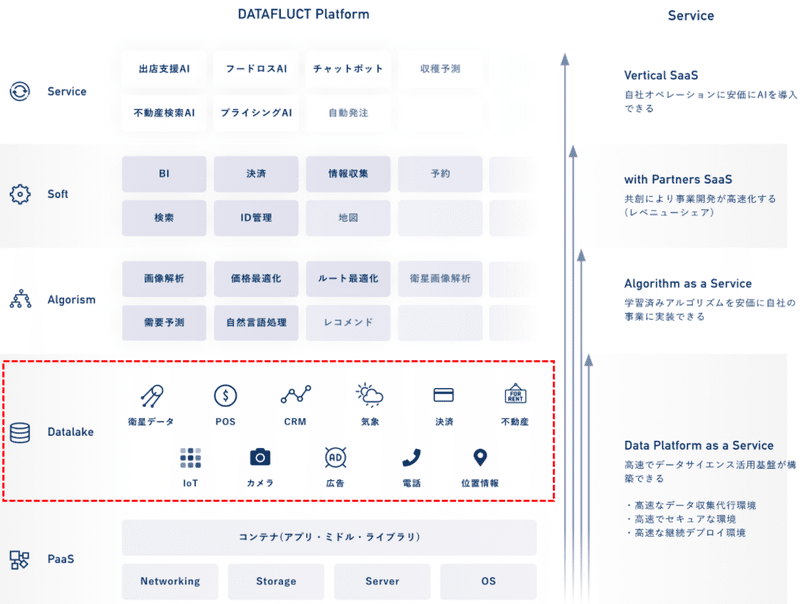
図1:DATAFLUCT platform構造
出典:https://datafluct.com/#service
プラットフォームの中でも、上図赤枠で囲っているデータレイクが、各提供サービスを支える重要な機能となっています。
今回の記事では、データレイクの説明を中心に行い、プラットフォームとしてどのような機能を果たしているのかを紹介していきます。
と言っても、データレイクの概念自体は 2010年からあるもので、参考となる情報は世にたくさん出ています。
本記事では、初めてデータレイクを知ったという方向けに説明するとともに、DATAFLUCTならではの特徴をお伝えします!!
データレイクのことなら既に知っているよ!って方は、ぜひ「3. DATAFLUCT service platform.でのデータレイク活用方法」からお読みください。
<目次>
1. データレイクって何もの?
2. どのように作られている?
3. DATAFLUCT service platform.でのデータレイク活用方法
4. 最後に
1. データレイクって何もの?
本章では、データレイクとは何ものなのか?ということをハッキリさせていきましょう。
「データレイク」という概念は、2010年にPentaho 最高技術責任者の James Dixon 氏が提唱したと言われています。
英語に直して、読んで字の如く翻訳すると、「データの湖」(DATA-LAKE)になります!
ヘッダーの画像が湖(LAKE)なのは、そのためです。
これだけでは内容が分からないので、Wikipediaにも聞いてみましょう。(笑)
「データレイク (Data lake) は構造化/非構造化データやバイナリ等のファイル含めたデータを一元的に格納するデータリポジトリ。一般的に、データレイクはレポート、可視化、分析、機械学習に利用されるエンタープライズのデータのコピーや返還後のデータを一カ所に集約する。データレイクはリレーショナルデータベースの構造化データ(列と行)や、半構造化データ(CSV、ログ、XML、JSON)、非構造化データ(Eメール、ドキュメント、PDF)、バイナリデータ(画像、音声、映像)を含めることができる。」
引用元:https://ja.wikipedia.org/wiki/%E3%83%87%E3%83%BC%E3%82%BF%E3%83%AC%E3%82%A4%E3%82%AF
いろいろ書いてありますが、ポイントとしては「生のデータを1つの場所に集めて管理する」です!
“生のデータ”というのは、用途や分析要件に合わせて加工されてないデータの状態を指します。例えば、センサーから取得したログ、GPS情報など、生成された状態のデータが”生データ”にあたります。
データの湖(lake)と例えているのは、山地の複数の水源から湧き出た水が自然な状態のまま湖に流れ込むように、加工されていない生データが1個所に溜まっていくことを表しています。
DATAFLUCTでは以下のように定義しています。
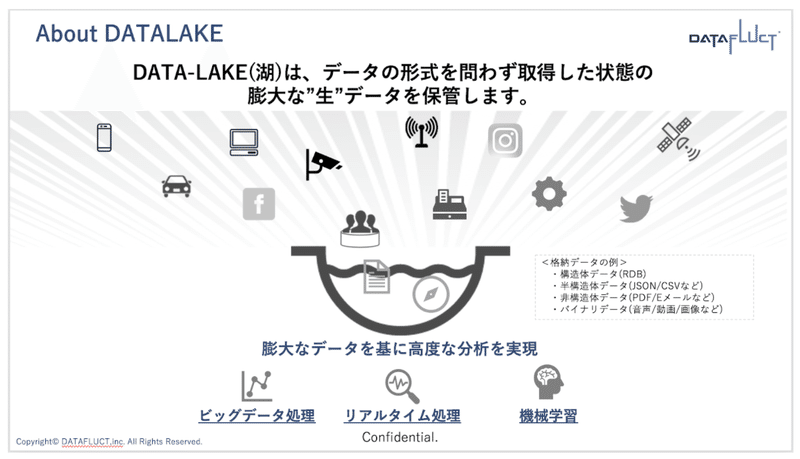
図2:データレイク定義
加工していない生データなので、保持するデータの形式は様々です。以下のようなデータをまとめて保管することになります。
<保管データの例>
・構造体*1データ(RDB内のデータ)
・半構造体データ(ログや定義情報などで使用するJSON/CSV/XMLなど)
・非構造体データ(PDF/Eメールなど)
・バイナリデータ(音声/動画/画像など)
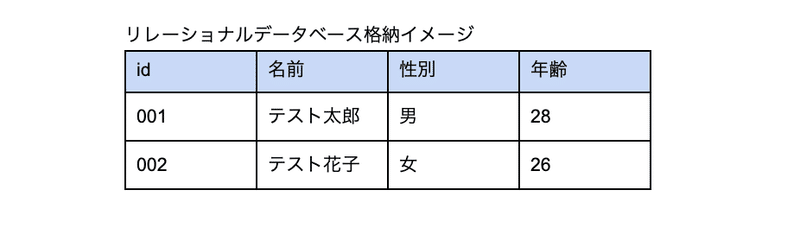
(*1)構造体とは、「いろいろな種類のデータをまとめて、1つにしたもの」です。
MySQLなどのリレーショナルデータベースに格納されている以下のようなデータイメージです。
データレイクは生データを保管すると説明しましたが、企業内などのシステムで保持しているデータを収集する際は構造体データも1次情報として取り扱います。
では、何故生データを1個所に集めると良いのでしょうか?
従来はデータ分析の要件に基づき、事前にデータ構造を設計し、集計、保管をしていました。このデータベースをデータウェアハウス(DWH)と言います。
データレイクの話をする際に、よく比較として用いられます。
データウェアハウスでは、過去の実績を基に分析対象の状況を正確に把握することに適しており、マーケティングやweb広告などの施策に繋げます。
ただし、データをどのような観点で分析するかが決まっているので、他の用途には使いにくいデータの集まりとなってしまいます。
近年のビッグデータ時代において、事前に分析の要件を全て網羅しておくことはほぼ不可能であるため、データウェアハウスだけでは新たなインサイトの発見やデータの分析観点を柔軟に替えて検証することが出来ません。
そこで、データレイクでは生データを1個所に保管し、データを活用するときに必要な切り口で取り出せるようにしています。
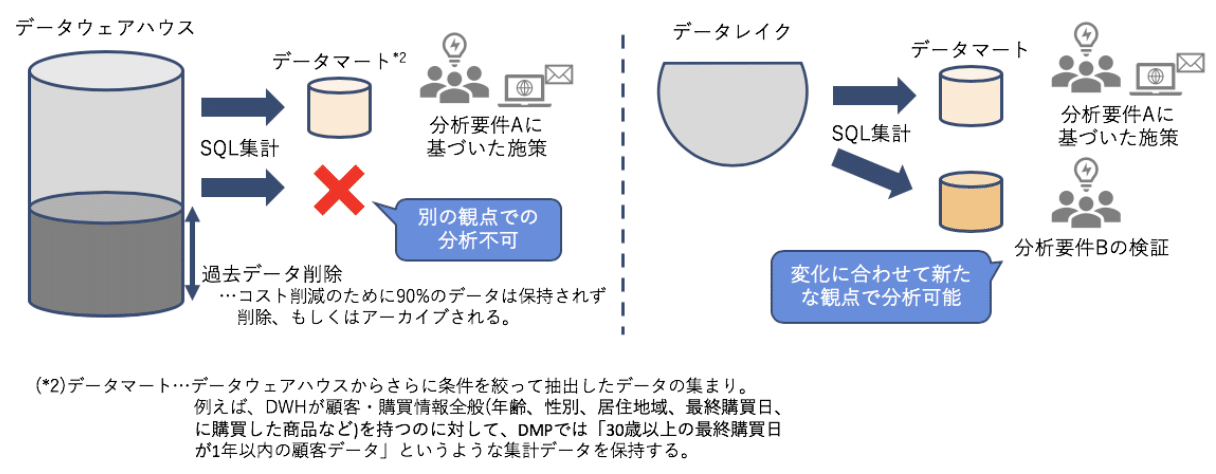
図3:データウェアハウスとデータレイクの違い
データウェアハウスでは、過去実績に基づいた演繹的アプローチに対して、データレイクでは複数の具体的事実から同一の傾向を抽出し分析する帰納的アプローチが可能となります。
今後さらに情報が増え続けるIT社会では、帰納的アプローチがこれからは必要な領域になり、その土台となるデータレイク環境が重要な位置付けになってきます。
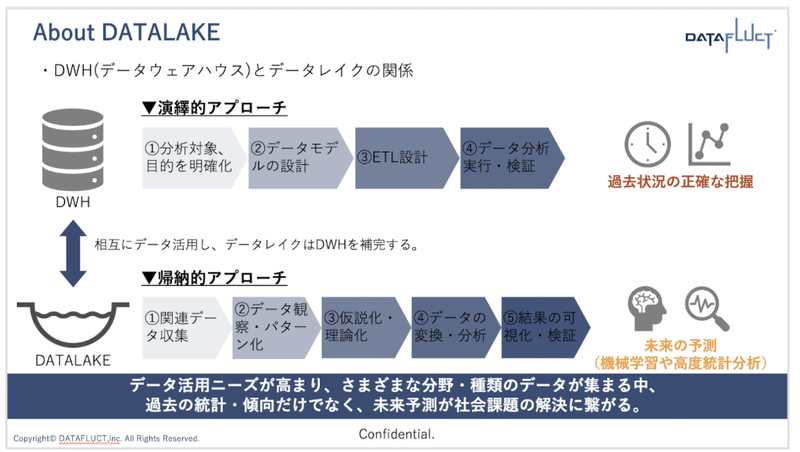
図4:データウェアハウスとデータレイクの分析アプローチの違い
だからといって、データレイクだけあれば良いのかと言うとそうではありません。
データレイクはデータウェアハウスを補完する立場にいます。データレイクで予測した未来をデータウェアハウスで分析・把握して検証するなど、相互に利用することでより高度な分析や機械学習をすることが可能となります。
データレイクの考え方は難しいものではなく、まとめると以下の通りです。
・データレイクは、データの形式を問わず取得した状態の”生”データを保管する
・未来の予測のために利用でき、データウェアハウスを補完するもの
ひと通り、データレイクの考え方を理解いただいた上で、次の章ではどのように構成されているかを説明していきます。
データレイクといえば、これっ!
というようなソリューションが1つだけあるわけではありませんので、構成について概要に触れていきます。
2. どのように作られているの?
前章でデータレイクは、「データの形式を問わず取得した状態の”生”データを保管する」と説明しました。
データレイクを作るには、データを保管する場所(ストレージ)を構築する必要があります。
構築には通常、パブリッククラウドのストレージサービスを利用します。
当然、自前でサーバーを立てて運用することもできますが、ストレージ容量の拡張性・データの可用性・運用面を考慮すると断然パブリッククラウドを利用した方が効率的です。
また、パブリッククラウドではストレージだけでなく、データレイクを構成するのに必要な要素をトータルで提供してくれています。
要素というのは例えば、データへのアクセスコントロール制御、データの読み込み、データのカタログ化、暗号化作業およびキー管理など、データレイクの設定と管理に必要なタスクを一元的に管理することが可能です。
3大パブリッククラウドでは、以下のサービスを利用することで比較的簡単にデータレイクを構築することができます。詳細は公式HPを参照してみてください。
①Amazon Web Service
・AWS Lake Formation
https://aws.amazon.com/jp/lake-formation/?whats-new-cards.sort-by=item.additionalFields.postDateTime&whats-new-cards.sort-order=desc
②Azure
・Azure Data Lake Storage Gen2
https://docs.microsoft.com/ja-jp/azure/storage/blobs/data-lake-storage-introduction
③Google Cloud Platform
・Cloud Storage
https://cloud.google.com/solutions/build-a-data-lake-on-gcp?hl=ja
DATAFLUCTでは、メインとしてAmazon Web ServiceのAWS Lake Formationを利用してデータレイク環境を構築しています。
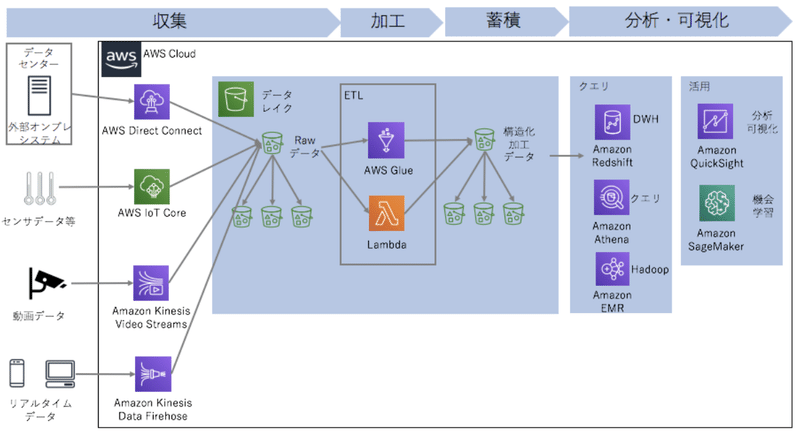
図5:構成イメージ
AWSのストレージ サービスであるSimple Storage Service(S3)を中心に非構造である生データを収集し、分析や可視化に必要なデータに加工します。
データレイクを活用し、分析基盤として、どのような処理をしているかの詳細は「データ基盤の作り方」の記事を参考ください。
データレイクだけ整備しても何の役にも立たず、上記記事でご紹介の「データ収集」→「ETL」→「メタデータ管理」→「データ抽出」→「分析・可視化」の過程を踏むことによって、初めて分析基盤としての価値を提供できることになります。
データレイクを理解し、構成をイメージできたところで最後にDATAFLUCT service platform.での活用方法をご紹介します!
3. DATAFLUCT service platform.でのデータレイク活用方法
DATAFLUCT service platform.では、主に以下の点でデータレイクを活用しています。
・あらゆる業界・業種の1次データ収集への活用
・自由度の高いデータマッシュアップの提供
3-1. あらゆる業界・業種の1次データ収集への活用
DATAFLUCTでは、「Data Science for every business.」を掲げています。
あらゆる業界・業種の枠を超え、企業との共創により多くのデータビジネスを生み出しており、取り扱うデータも多種・多様です。

図6:DX/DS/新規事業/支援経験のある業界
上図の通りデータの種類、量、形式は多岐にわたります。
データレイクの持つ特性を活かして膨大な生データである1次情報の保管を行い、データビジネスで必要な分析データの提供を実現します。
3-2. 自由度の高いデータマッシュアップの提供
3-1と同様にあらゆる業界・業種なデータを取り扱っていることに起因しますが、データレイクにて生データである1次情報を削除することなく保管できているため、異業種間や様々な切り口によるデータのマッシュアップ(組み合わせ)が可能となります。
マッシュアップには異業種間だけでなく、DATAFLUCTが収集した天気データや地図情報などと掛け合わせることも可能です。
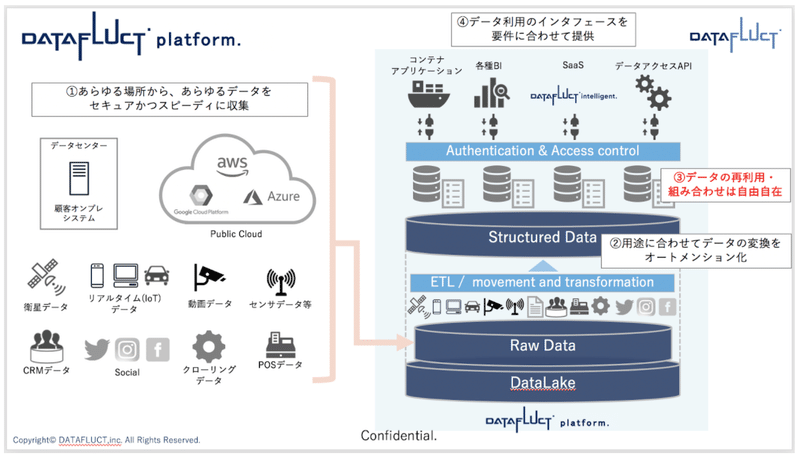
図7:platformのデータの流れ
上図では、データを収集して分析データを提供するまでの流れを表しています。
データマッシュアップ部分は「③データの再利用・組み合わせは自由自在」にあたり、データレイクの生データを抽出して、組み合わせたいセットでまとめた構造化データを簡単に取り出すことができるようになっています。
このデータを利用して、BIによる可視化やアプリケーション利用、機械学習を行うことができます。
4. 最後に
データレイクの概念を中心に、DATAFLUCTとしてどのような構成で、どのように活用しているのか、について説明してきました。
データレイクはデータ分析の環境を構成する1つの部品に過ぎません。その他に基盤を構成するインフラ環境、データ収集、データサイエンティスト確保など、必要なタスクは盛りだくさんです。
DATAFLUCT service platform.では、分析基盤の構築からサービス運営までのデータ活⽤に関するすべてのプロセスを⽀援できるサービスになっています。興味がある方は是非お問い合わせください。
また、DATAFLUCTではデータ活用に関わる様々な情報を発信していますので、宜しければフォローしてください!!