
pycaretで簡単プロ野球選手の年俸を機械学習で予測する

概要
機械学習やデータ分析するのにscikit-learnを使って学習して予測するのはいくらライブラリで楽になったとしても、
初心者にはややハードルが高いですね。
今はAUTOMLといった自動で複数の機械学習アルゴリズムを試せます。
2〜3年前は製品としてしかなく、無料で行うことはできませんでした。
しかし、今となってはpythonのライブラリで可能です。
今回はpycaretというライブラリを用いて、機械学習によるプロ野球年俸予測を行います。
環境
私の実行環境は以下になります。
Macbook air M1
メモリ 16GB
Anaconda jupyter notebook
Anacondaのインストールしたライブラリはrequirement.txtに示します。
ライブラリの依存関係でなかなか実行できなかったので、添付テキストファイルの環境を参考にすると良いと思います。
ライブラリインポート
今回使うライブラリをインポートします。
%matplotlib inline
from pycaret.regression import *
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
import japanize_matplotlib
データ準備
機械学習を行うにはまずデータがないといけません。
そこで、プロ野球のプロフィールデータと推定年俸をスクレイピングします。
df = pd.read_html('https://baseball-data.com/ranking-salary/all/')
撮ってきたデータの欲しい部分を抜き出し、データフレーム型として扱うように格納します。
df = df[0]
年俸トップ100選手を抜き出しました。
カラムに注目すると二重になってますね。
二重になってるカラムを外します。
df.columns = df.columns.droplevel(0)
df.head()
順位で年俸高い、低いがわかってしまうので外します。
df.drop('順位',axis=1,inplace=True)
df.columns年俸や年数、年齢などのデータが文字列型ですので整数型に直します。
df['年俸(推定)'] = df['年俸(推定)'].str.replace('万円','').str.replace(',','').astype('int32')
df['年数'] = df['年数'].str.replace('年','').astype('int16')
df['年齢'] = df['年齢'].str.replace('歳','').astype('int16')
df['身長'] = df['身長'].str.replace('cm','').astype('int16')
df['体重'] = df['体重'].str.replace('kg','').astype('int16')
df.head()
データの加工が終わりました。
学習データと未知データを分けます。
今回は100個のデータしかないので、5%だけ未知データとします。
data = df.sample(frac=0.95, random_state=123)
data_unseen = df.drop(data.index)
data.reset_index(drop=True, inplace=True)
data_unseen.reset_index(drop=True, inplace=True)
print('Data for Modeling: ' + str(data.shape))
print('Unseen Data For Predictions: ' + str(data_unseen.shape))
>>>Data for Modeling: (95, 12)
>>>Unseen Data For Predictions: (5, 12)モデリング
pycaretを使用していきます。
setupで使用データとターゲット変数(予測したいデータ)を入れるだけで実行できます。
実行するとカテゴリ変数、数値変数も自動で分けて前処理してくれます。
さらにKFold(交叉検定)も自動で作ってくれます。
デフォルトでは10Foldですので、Fold=5などと指定すれば分割数を指定できます。
今回はデフォルトで。
exp1 = setup(data=data,target='年俸(推定)',session_id=123)
compare_models()でAUTOML実行です。
最も良い精度のモデルは黄色でハイライトされます。
compare_models()
モデルを指定して交叉検定
モデルを指定して構築することができます。
compare_models()の結果のindex列がモデルの名前になります。
create_model(モデルの名前)で指定したモデルで学習、評価をしてくれます。
精度の平均と標準偏差を出してくれるので便利です。
ここでは最も精度が良かったknn(K近傍法)でモデルを作ります。
knn = create_model('knn')
モデル名を指定するだけです。
自分の好きなモデルを選択するもよし、データの性質やビジネスの性質等で必ずしも精度がよければ良いということはありません。
モデルを試行錯誤で色々試す必要があります。
そんな時も簡単にモデル選択ができます。
cat = create_model('catboost')
最適化
作ったモデルはより良い制度にするためにパラメータチューニングが必要です。
最適化も1行です。
ここではcatboostを最適化します。
tuned_cat = tune_model(cat)
精度が・・・・良くなっていませんねぇwww.
最適化した結果、得られたパラメータも確認可能です。
tuned_cat.get_params(){'depth': 3,
'l2_leaf_reg': 50,
'loss_function': 'RMSE',
'border_count': 254,
'verbose': False,
'random_strength': 0.7,
'task_type': 'CPU',
'n_estimators': 250,
'random_state': 123,
'eta': 0.15}残差プロットを出します。
高い年俸の選手が当てられてませんね。
どうしてもサンプル数も少なくなりますので、当てるのは厳しくなります。
また年俸も指数オーダーで変化していきますのでlogスケールにする必要があります。
これは、年収や残高でもよく起こりますね。
plot_model(tuned_cat)
モデル評価
作成したモデルの精度だけでなく、どの特徴量が効いているのかも重要です。
モデルの説明可能性を示すのに有名なSHAPも1行です。
赤い点が特徴量として重要な値を示します。
右に触れるほど年俸が高くなる要因、左に行くほど年俸が低くしていると捉えることができます。
結果を見るとどうやら身長、体重は特徴量の振れ幅が広いですね。
出身地が兵庫だと年俸が高い傾向が出ています。
2021年は兵庫出身の選手が年俸が高い!? また球団ではソフトバンクが年俸高い影響があるようです。
今シーズンは残念な結果となりましたが、2010年代無双していた球団だけあって活躍する選手も多く、
人気も出て球団もほくほくした結果があるかもしれませんね
interpret_model(tuned_cat)
未知データへの適用
学習データ内で分割して作成した未知データで精度を確認していきます。
未知データに対しての精度が確認できます。
学習データに対してより結果が良い!?
cat_holdout_pred = predict_model(tuned_cat)あらかじめ分割しておいたデータに対して予測をしていきます。
新しくきた未知データに対して予測をかける場合は、predict_model(作成したモデル、予測するデータ)で予測ができます。
predictions = predict_model(tuned_cat,data = data_unseen)
predictionsLabel列に予測結果が追加されます。

予測した結果の残差を確認してみます。
predictions['残差']=predictions['年俸(推定)']-predictions['Label']
plot_df
plot_df = predictions
plot_df.index = plot_df['選手名']
plot_df['残差'].plot(kind='bar',color='skyblue',alpha=0.5)
plt.ylabel('推定年俸[万円]')
plot_df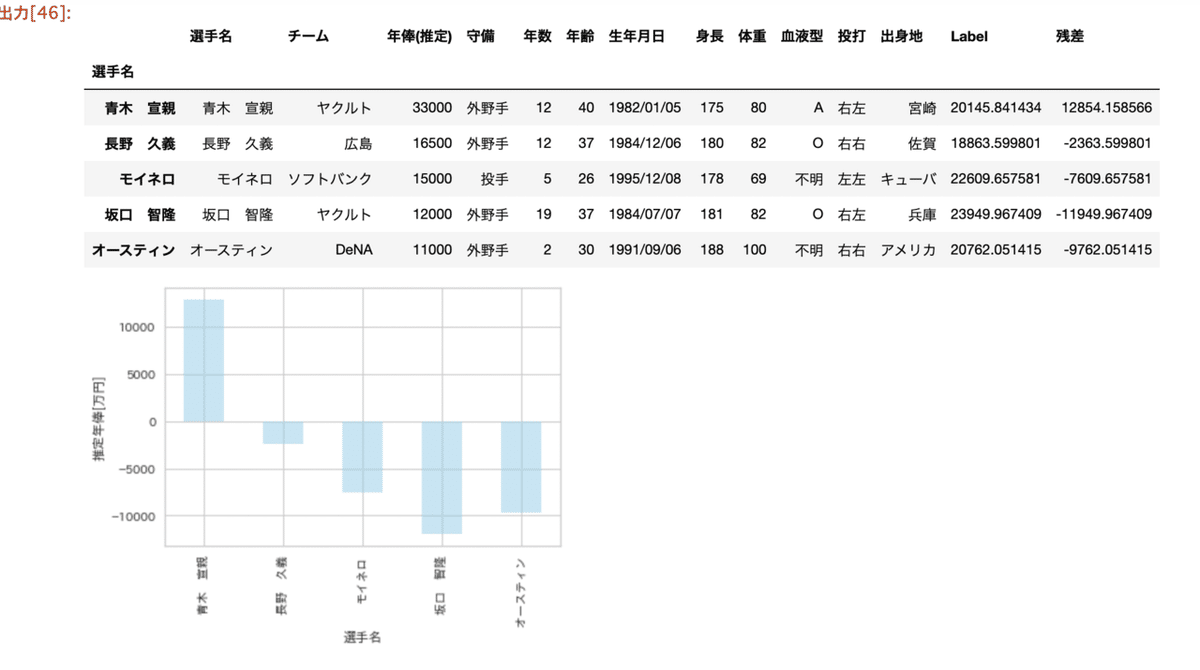
作成したモデルの通り、だいたい1億円くらいの誤差が出ていますね。
長野選手は2千万くらいの誤差にはなっています。
圧倒的なデータ不足ですね!!w
あと、logスケールにしましょうwww
参考URL
今回の記事のデータとnotebook(有料)
今回の記事のスクレイピングしたデータとjupyter notebookは下記からダウンロードできます。

よろしければサポートをよろしくお願いします。サポートいただいた資金は活動費に使わせていただきます。