
深層学習による画像分析(CNN, CAM, 物体検出)~D4cノウハウプレゼン大公開~

D4cグループで年3回行われているイベント「ノウハウプレゼン大会」から発表をピックアップするシリーズ。
今回は2023年1月の回から、入社3年目の私、瀬戸が発表した「Pythonデータ分析(画像系)」をお届けします!
はじめに
今回、私は深層学習を用いた画像系のタスクをまとめて紹介することにしました。題材にした理由は2つあります。
1つは自身の強みとしていきたい分野であること。もう1つは画像系のノウハウの蓄積が弊社の新規案件の獲得にもつながること。私個人と会社どちらにとっても良い発表になると考え、このテーマを選びました。
この記事で伝えたいこと
ー深層学習を用いた画像認識タスクの概要
ー画像分類(vgg16)のネットワーク構成について
ー分類根拠の可視化(CAM)の仕組みについて
ー物体検出(YOLO)の概要と実行結果の確認
一般的な画像認識にまつわる深層学習を用いたタスクを紹介します。みなさまの知識の整理に役立つと嬉しいです。
発表者について
学生時代:
・某大学院の地球科学系統の専攻
・プログラミングの経験 無 /データ分析の経験 有
発表時(入社2年目):
・主な業務はB to Cマーケティングに関するデータ分析業務
・使用言語はPythonが中心
発表の内容

内容ですが、深層学習と画像認識の基本事項を確認した後、画像分類・分類根拠の可視化・物体検出についてかいつまんで発表しました。
深層学習のサイクル
まず簡単に深層学習の学習から予測の流れをご紹介します。

上の図は深層学習のサイクルを示しています。
左上:様々なデータを入力して、ネットワークを順伝播させ出力を得る
右上:出力を目的変数と比較して損失を得る
右下:得た損失を誤差として、上位に逆伝播させ各ノードで勾配を計算
左下:得られた勾配から損失関数が最小となる点に近づくようにパラメータを更新
学習の段階では、この予測計算からパラメータの更新を繰り返すことで、パラメータを最適化させます。パラメータが最適化されたのち、予測を行います。
画像系タスクの整理
深層学習手法が得意とする画像系タスクを紹介します。

2つ以上のクラスから1クラスに分類する確率を求める画像分類
画像のどこに何が写っているかを予測する、物体検出
ピクセル単位で位置とクラスを予測するセグメンテーション
近年話題のGAN(敵対的生成ネットワーク)をベースにした画像生成
セグメンテーションには、インスタンスセグメンテーションやセマンティックセグメンテーション、パノプティックセグメンテーションがあります。それぞれの手法によって、分割する領域の細かさが異なります。
ちなみに余談ですが、近年話題の「ChatGPT」はGPT3.5やGPT4.0という大規模言語モデル(LLM)をベースにしたサービス名称です。文書生成AIと位置づけられています。GPT-1はOpenAIが2018年に公開した大規模言語モデル(LLM)です。その後、GPT-2(2019年)、GPT-3(2020)という流れで、GPT-3.5(2022)のリリースから間もなくChatGPTが発表されています。
画像の特徴を抽出するネットワーク
まずは、深層学習で画像情報を扱うために重要な、ネットワークについてご紹介します。
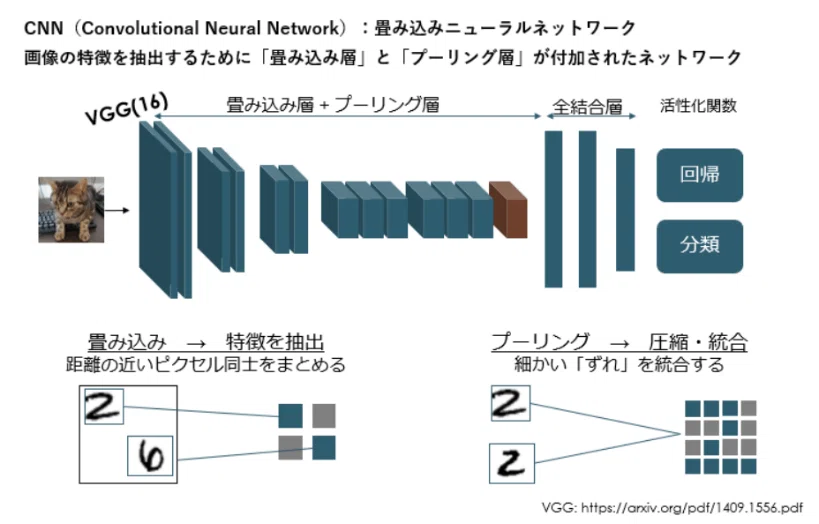
画像内の物体のクラス(犬or猫)や位置を予測するために、どのようなネットワークが必要になるのでしょうか。
画像分類自体はサポートベクトルマシンやDNN(Deep Neural Network)をモデルとすることも可能ですが、一般的に画像分類はCNN(Convolutional Neural Network)という「畳み込み層」と「プーリング層」が全結合層の上位に付加されたネットワークを使用します。これはCNNが画像の特徴量抽出に適しているためです。
今回はVGG16というモデルを例にします。※16は畳み込み層の数になります。入力する画像は我が家のザックちゃん(アメリカンショートヘア 5才)です。入力画像が畳み込み処理を経ることでサイズは小さくなります。それぞれの層の役割は以下になります。
・畳み込み層:画像上の空間的に近いピクセル同士をまとめる
・プーリング層:画像上の物体の細かいずれによる影響を緩和する
畳み込み処理が完了すると全結合層 で1次元配列に変換したのち、タスクごとに適切な活性化関数へ入力します。得られた出力は回帰・分類タスクでそれぞれ連続値や確率などになります。
ネットワークの各層で画像を出力
入力した画像が、層を通るごとにどのように変化するか見てみましょう。

ザックちゃんを入力し、各畳み込み層の出力を可視化したものです。
層が深くなるにつれて抽象的な特徴が得られています。途中の畳み込み層の出力は特徴量マップと呼ばれます。今回の例ではアメリカンショートヘアの特徴が抽象化されて、猫っぽさが特徴量マップに表れているといえます。
一般的に全結合層の一つ手前の層(上の画像で「これが有用!」の部分です)のパラメータが分類に有用とされているため、この層から得られる特徴量マップを用いて画像間の類似度を算出したり、クラスタリングなど他のタスクに展開することも可能です。
分類根拠の可視化
続いて、分類根拠の可視化の部分に入ります。

画像系のXAIとして最も基本的なCAM(Class Activation Map)を紹介します。
XAI(Explanable AI)は「説明可能なAI」と呼ばれます。CAMは入力に対して予測根拠を可視化する手法です。
まず上記の左図のザックちゃんを、”CAT”と分類するモデルを訓練します。右図のようにヒートマップを元画像に重ねて表示し、予測に寄与している部分を可視化することができます。
赤い部分ほど、”CAT”と予測した根拠として強い影響を及ぼしていることを示唆しています。ザックちゃんの胴体周辺の値が大きいため、このモデルはきちんとザックちゃんの特徴を学習し”CAT”と判定している可能性が高いことがわかります。
CAMの仕組み
CAMの構造の細かい部分を見ていきます。

CAMで可視化のヒートマップの作成に必要なのは、モデルの「最終畳み込み層の出力」と「GAP層(Global Average Pooling層)※上画像の茶色の層」の出力になります。GAP層は各チャンネルの平均を返します。
これを重みとして、最終出力層のチャネルにそれぞれかけてチャンネルの総和をとります。こうして得られる特徴量マップを元画像と同じサイズに拡大し、重ねることで可視化します。
転移学習
転移学習を実行する前後の可視化結果を比較してみます。

1は事前学習済みモデルをそのまま利用しました。2は事前学習済みモデルに転移学習を行ったものになります。
2はザックちゃんの額や中心部分が分類根拠として強いことが分かります。ここで1の画像についての結果を言語化すると、”CAT”と判定するにはキーボードが根拠になっていることが分かります。これは原因としてキーボートと一緒に写っている猫の画像が学習画像に含まれていたことが考えられます。
このように学習データに偏りが存在する可能性なども考慮できることが、CAMを利用するメリットです。
物体検出とは
最後に少しだけ物体検出についても触れてみたいと思います。

物体検出は画像をネットワークに入力すると、画像内の特定の物体のクラス分類とバウンディングボックス(BBox)のxy座標、そして確信度という数値を返します。
モデルの評価指標には1秒間に検出できる画像の枚数(FPS)もあります。リアルタイムで検出したい際は、処理速度もモデル選択のために重要な要素です。
物体検出モデルの沿革
物体検出の沿革をざっくりとまとめてみました。

上の画像(沿革)では「検出」がバウンディングボックスの位置を予測し、「識別」が分類タスクであることを示しています。
Two Stage Detectionは検出と識別を別々に行う一方、YOLOに代表されるOne Stage Detectionは検出と識別を同時に行うモデルで、FPSの面でTwo Stage Detectionのモデルよりも優れています。近年ではTransformerが導入されたモデルもPytorchなどを利用すれば比較的容易に利用することができます。
Hands on
ここで既存の学習済みモデルを利用して、以下の画像に対して物体検出を行ってみます。

画像にはザックちゃんとノート、PCなどが写っています。
物体検出に利用したモデルはYOLOv5です。
予測結果
実行結果がこちらです。

結果を見ますと、ザックちゃんとノートとPCに加え、キーボードも個別に検出されていることが分かります。
確信度も8割強でかなり高いことが示されています。今回は事前学習済みのモデルを使用したことにより比較的良い結果を得ることができました。実際にモデルを構築する際は、検出したい教師データを用意して転移学習やファインチューニングといった再学習の手順を踏むのが一般的になるかと思います。
使用したコードはGithubで公開されており、数行程度で実行可能なのでぜひ試してみてください。
参考:https://github.com/ultralytics/yolov5/issues/36
まとめ
今回の記事では深層学習で画像認識を行う一般的な手法について以下を紹介しました。
深層学習を用いた画像認識タスクの紹介
画像分類(vgg16)
分類根拠の可視化(CAM)
物体検出(YOLOv5)
私は現在、画像処理を用いる案件に従事しており、ノウハウプレゼン大会での発表に向けて整理したことは仕事にも活きています。
ノウハウプレゼン大会の準備と発表を通し、とても有意義な経験ができたと考えています。今後も精進していきます。
(執筆:瀬戸 )
少しでもお役に立てましたら、記事の下の♡を押していただく&フォローいただけますと励みになります!
▼採用情報TOP
▼この執筆者が書いた大会レポート記事はこちら
▼D4cノウハウプレゼン大会についてはこちら