AIで競馬予想をしてみよう(入門編)

コロナ禍による暇つぶしで勉強しはじめたAI。競馬の予想がしたくて、テキストとにらめっこして四苦八苦していたら、なんとなくですが使い方も分かってきました。
そこで、「初めての人はこの辺りからやればいいんじゃない?」的なものを(初心が残っているうちに)残しておこうと思いました。
(物理的に)必要なもの
・Windowsパソコン
・月額2,090円の会費
これらはいずれも、JRA-VAN データラボから各種データをダウンロードするため、言い換えるとJRAが提供している公式データを取得するために必要なものです。
「データは自分で手作りするぜ」とか「スクレイピング(クローリング)で収集するぜ」という場合は不要です。適当なパソコンにGoogle Chromeが入っていればOKです。
筆者は、データ取得をWindows機で、それ以外をMacで行っています。スクレイピングでデータを取得しない理由は、「情報にはそれなりの対価を支払うべき」という個人的な思想のためです。
(論理的に)必要なもの
・Google Chromeブラウザ
・Googleアカウント
通常、AIの開発にはPythonの開発環境を構築する必要がありますが、今回はGoogleが提供するColaboratoryを使用します。
これはPythonをブラウザ(Google Chrome)上で実行できるため、面倒な環境構築を行う必要がありません。PythonのソースコードはGoogleドライブ上に保存されるため、Googleアカウントが必要です。
(技術的に)必要なもの
・競馬の知識
・プログラミングの知識(とりあえずなんでもいい)
初歩的な競馬の知識は必要です。たとえば「人気」と書かれていて、「人気って何?"にんき"なの?"ひとけ"なの?」ってなるようなら少々厳しいです。
あとプログラミングの知識(経験)は多少ある方がいいです。ここには「プログラミングとはなにか」までは書いていません。
Pythonを使用しますが、プログラミング経験者であればPython未経験者でも多分大丈夫で、たとえば「ソースコメントはこう書きます」とか「CSVデータを取り込みます」とか言われて、何を言っているのかピンとくる人なら問題ないかと思います。
「そもそもパソコン使えないんだけど」という人はパソコン教室に行ってください。
JRA-VANの契約とソフトウェアのインストール

上記のリンクからJRA-VAN データラボを契約し、Windows機へTARGET frontier JV(ターゲット)をインストールしてください。手順はリンク先に従ってください。ここでは割愛します。
JRA-VAN データラボとは…
会員になると、JRAが提供する各種競馬データを使用できます。JV-Linkという機能を使えば自分で競馬予想ソフトウェアを作成することも可能ですが、ここでは人気No.1ソフトのTARGET frontier JV(ターゲット)を使用します。
TARGET frontier JV(ターゲット)とは…
JRA-VAN データラボ会員が使える競馬情報データ分析ソフトです。データをCSV出力するのに使います。
このソフトで予想するわけではありません。
注意:この手順は、予想で使うCSVデータを取得するためのものです。
ご自身でデータを準備できる場合は、不要です。
AI予想の流れ
教師あり機械学習により予想します。
簡単に説明すると以下の通りです。
・過去の出馬データとレース結果をAIに渡し、学習させる
・未来の出馬データをAI渡し、レース結果を予想させる
重要になるのが出馬データとレース結果です。
出馬データは出走する馬の情報で、人気や馬体重などいわゆる競馬新聞に書かれている情報です。出馬データとして何を渡すかによって、予想結果が左右されます。
また、レース結果をどう定義するかはとても重要です。
着順を予想する、走破タイムを予想する、などが考えられますが、ここでは「3着以内に入るかどうか」を予想することにします。
理由は、AIに分析をさせる際、結果をYes/Noで出力する(2値クラス分析)のがもっとも単純で分かりやすいためです。
同じYes/Noなら「1着になるかどうか」でもいいのですが、ご存知のとおり競馬の予想では、「1着を当てる」(単勝)よりも、「3着以内に入る馬を当てる」(複勝、ワイド、三連複)方が、購入する馬券の幅が広がります。
出馬データ・レース結果のCSV出力
TARGET frontier JV(ターゲット)から過去の出馬データ、過去のレース結果、未来の出馬データをCSV化して出力します。
1. ターゲットのデータを最新化
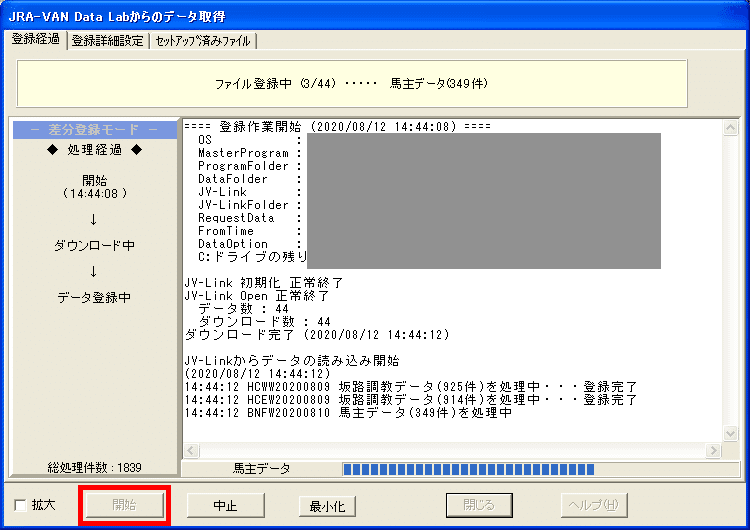
データ登録画面からJRA-VAN データラボの最新データをダウンロードします。開始ボタンを押すと、各種データが自動でダウンロードされます。
2.過去の出馬データ・過去のレース結果の出力


開催成績CSV出力画面で、出力する成績データを選択します。項目設定ボタンを押してください。

ここでは、出馬データとして人気を、レース結果として確定着順を出力します。馬番と馬名は、データを見たときに分かりやすいように出力します。


出力する年度を選択します。ここでは2019年、2020年を選択します。
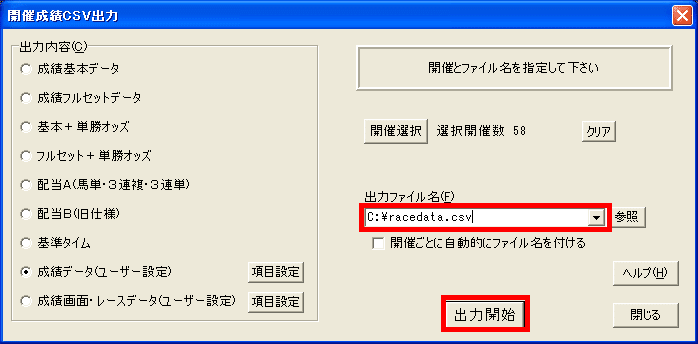
任意の出力ファイル名(ここではracedata.csv)を入力し、CSVを出力します。出力したCSVを表計算ソフトで開くと、以下のように見えます。

3.未来の出馬データの出力


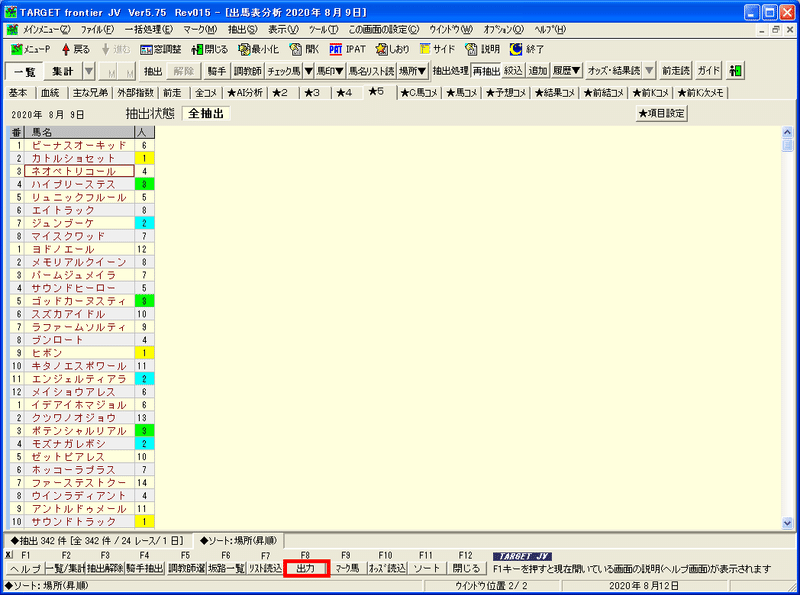
メインメニューから最新の出馬表を開きます。今回はこれを未来の出馬データとします。
出馬表分析画面で以下の操作を行ってください。
1.「★5」タブを選択する
2.「オッズ・結果読込」ボタンを押す
3.「★項目設定」ボタンを押す

項目設定画面で、成績データと同じ項目を選択します。ただし、未来の出馬データのため、当然ながら確定着順は出力できませんので、それ以外の項目を合わせるようにします。
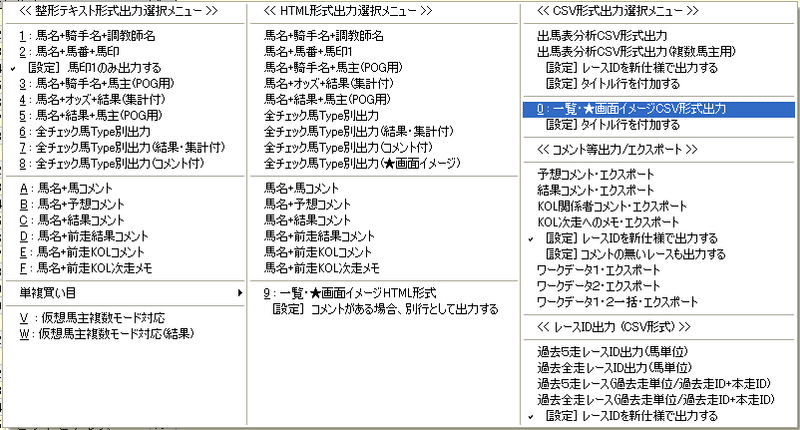

4.「出力」ボタンを押す
5.「一覧・★画面イメージCSV形式出力」を選択する
6.「指定ファイル名」に任意の値(ここではracecard.csv)を入力する
7.「OK」ボタンを押す
出力したCSVを表計算ソフトで開くと、以下のように見えます。

Colaboratoryを使えるようにする
AIのプログラムはColaboratoryに記述して実行します。
詳しく知りたい方は以下を参照してください。
Google ChromeからGoogleアカウントにログインし、GoogleドライブからColaboratoryのファイルを新規作成します。

タイトルを入力します。

コードを入力します。
# ←シャープをつけるとラインコメントになります
# print関数により、標準出力へ出力します
# 文字列はダブルまたはシングルクォーテーションで括ります
print("Hello, World !")入力後、コード左の「セルの実行」ボタンを押すと、下に結果が表示されます。「Hello, World !」と表示されれば成功です。

PythonでCSVデータを取り込む
Colaboratory(以下、colab)の左にあるフォルダをクリックし、出力したファイルをドラッグ&ドロップします。

「+コード」をクリックし、新しいコードセルを追加します。

Pandasをインポートします。詳しくはWikipediaをご確認ください。
# Pandasを「pd」という変数名でインポート
import pandas as pdPandasのread_csvを使って、過去の出馬データとレース結果を取り込みます。
# 過去の出馬データとレース結果(racedata.csv)の取込
# names CSVのヘッダ(馬番、馬名、人気、確定着順)
# encoding ファイルのエンコーディング
# skipinitialspace データの前後のスペースを除去する場合はTrue
rd = pd.read_csv("racedata.csv"
, names=["horsenumber", "horsename", "favorite", "official"]
, encoding="SHIFT_JIS"
, skipinitialspace=True
)
# 出馬データとレース結果を出力
print(rd)実行すると以下のように出力されます。

同様に、未来の出馬データを取り込みます。
# 未来の出馬データ(racecard.csv)の取込
# names CSVのヘッダ(馬番、馬名、人気)
# encoding ファイルのエンコーディング
# skipinitialspace データの前後のスペースを除去する場合はTrue
rc = pd.read_csv("racecard.csv"
, names=["horsenumber", "horsename", "favorite"]
, encoding="SHIFT_JIS"
, skipinitialspace=True
)
# 出馬表を出力
print(rc)
取り込んだデータを加工する
Numpyをインポートします。詳しくはWikipediaをご確認ください。
# Numpyを「np」という変数名でインポート
import numpy as np上記「AI予想の流れ」で記載したとおり、レース結果を「3着以内に入るかどうか」と定義しました。
現在のデータは「確定着順」のため、データに列を追加し、「3着以内であれば『1』、4着以降であれば『0』」を設定します。
# 3着以内かどうかの列を追加
rd = rd.assign(upto3 = (rd['official'] < 4).astype(np.int64))assign(…)によってrdに列を追加します。upto3が追加する列名です。
rd['official'] < 4というのが「確定着順が4未満かどうか」で、TrueまたはFalseが返ります。それを.astype(np.int64)で整数に変換しています。Trueが1、Falseが0に変換されます。
追加後のデータを出力すると以下のようになります。

出馬データとレース結果に分ける
加工したデータには、出馬データとレース結果が混在しています。
これらを分割し、不要な列を削除します。
# データをコピーし、出馬データとして必要な列以外を削除
X = rd.copy()
X = X.drop(['horsenumber', 'horsename', 'official', 'upto3'], axis=1)データをコピーし、出馬データとして必要な「人気」以外の列は削除します。列を削除する場合、dropの引数としてaxis=1を指定します。
補足:
馬番、馬名は削除します。共に予測には使用しないためです。
特に馬名については、AIに渡すとエラーになってしまいます。AIは数値項目しか受け取れないためです。
馬番の大小を予測に使ってほしい場合(内枠/外枠有利を見たい場合など)は、削除せずに残すこともあります。
同様にデータをコピーし、レース結果として必要な「3着以内かどうか」列以外を削除します。
# データをコピーし、結果データとして必要な列以外を削除
y = rd.copy()
y = y.drop(['horsenumber', 'horsename', 'favorite', 'official'], axis=1)出馬データ、レース結果を出力すると以下のようになります。

出馬データ、レース結果をさらに訓練データ、テストデータ、訓練セット、テストセットに分割します。
# sklearnからtrain_test_splitをインポート
from sklearn.model_selection import train_test_split
# 出馬データを訓練データと訓練セットに分割
# レース結果をテストデータとテストセットに分割
X_train, X_test, y_train, y_test = train_test_split(
X, y, random_state=0)scikit-learn(sklearn)は、機械学習においてもっとも重要なライブラリです。ここではscikit-learnのtrain_test_splitを使用し、データセットを分割しています。scikit-learnについて詳しくはWikipediaを参照してください。
train_test_splitを使用すると、訓練データ75%、テストデータ25%にデータが分割されます。この75%でAIを訓練し、残りの25%で結果を検証します。
つまり、75%の訓練データで「人気がこれくらいであれば、3着以内に入るはず」という分析をして、25%のテストデータでその答え合わせをします。
各データを出力すると以下のようになります(一部のみ)。
77,455件のデータのうち、58,901件が訓練データ、19,364件がテストデータになっていることが分かります。

データを分析する
実際にデータを分析します。
ここでは決定木と呼ばれるモデルを使って分析します。なぜ決定木を使うかというと、AIが分析する様子を可視化することができるからです。
# sklearnから決定木をインポート
from sklearn.tree import DecisionTreeClassifier
# 決定木による分析
tree = DecisionTreeClassifier(random_state=0)
tree.fit(X_train.values, y_train.values)
# 分析結果を出力
print("訓練セットの精度:{:.3f}".format(tree.score(X_train.values, y_train.values)))
print("テストセットの精度:{:.3f}".format(tree.score(X_test.values, y_test.values)))決定木を分析に使用するには、scikit-learnからDecisionTreeClassifierをインポートします。
treeという名前で決定木を定義し、fit(…)に訓練データと訓練セットを渡すことで分析が行われます。
分析結果の精度はscore(…)に訓練データと訓練セット、またはテストデータとテストセットを渡すことで分かります。
これを実際に実行すると、

エラーが発生してしまいました。
これは、決定木に渡したデータにNaN、つまり「空」の項目を含むレコードが存在する場合に発生します。
対象レコードを抽出してみましょう。
# 人気がNaN(空白)のレコードを抽出
print(rd[rd['favorite'].isnull()])
対象が336レコードありました。確定着順が「0」になっていることから、おそらく「競走除外」となったレコードと推測できます。これらは分析に悪影響を及ぼすため、削除します。
# データの件数を確認するため出力
print(rd)
# 人気がNaN(空白)のレコードを抽出
print(rd[rd['favorite'].isnull()])
# NaNを含むレコードを削除
rd = rd.dropna()
# 人気がNaN(空白)のレコードがなくなる
print(rd[rd['favorite'].isnull()])
# データの件数が減る
print(rd)
77,455件のデータに対し、NaNを含む336件を削除したことで、77,119件になったことが分かります。
あらためて分析を実行すると、以下の結果となります。

訓練セット、テストセット共に、精度が0.80前後でした。
これは「3着以内に入るかどうか」の出力結果がおおよそ80%正しい、というものです。(馬券が80%当たる、ということではありません。)
プロセスを可視化する
詳しい説明は省略しますが、以下のコードで決定木を可視化できます。
from sklearn.tree import export_graphviz
export_graphviz(tree, out_file="tree.dot", class_names=["4orless", "upto3"],
feature_names=X_train.columns, impurity=False, filled=True)
import graphviz
with open("tree.dot") as f:
dot_graph = f.read()
graphviz.Source(dot_graph)
これを見ると、どのように「3着以内かどうか」を判断しているのか分かります。
最初に「人気が4.5以下かどうか」を見て、Trueならば次に「人気が2.5以下かどうか」かどうかを見て…という流れです。
最終的に、人気が2.5以下の場合は3着以内、それ以外は4着以降、という判断になります。つまり人気だけで判断すると1、2番人気が3着以内に入る、ということです。
未来の出馬データの結果を予測する
この決定木を元に、未来の出馬データの結果を予想します。
# NaNを含むレコードを削除
rc = rc.dropna()
# データをコピーし、出馬データとして必要な列以外を削除
X_pred = rc.copy()
X_pred = X_pred.drop(['horsenumber', 'horsename'], axis=1)
# 予測結果の出力
y_pred = tree.predict(X_pred.values)
print(y_pred)過去の出馬データと同様に、NaNを含むレコードを削除し、不要な列を削除します。これをpredictの引数に渡すと、戻り値として予想結果が返ってきます。

これだと結果が分かりづらいので、元のデータに列を追加して格納します。

データ件数が多すぎて途中が省略されてしまうため、先頭の2レース分のみ出力します。

これを見ると、人気が1.0または2.0のレコード(1、2番人気の場合)のみ、結果が1(3着以内に入る)となっていることが分かります。
おわりに
AI(教師あり機械学習)を用いた競馬予想の基礎の基礎を説明しました。
今回は説明を簡単にするために、出馬データとして「人気」しか扱いませんでしたが、入力するデータの種類が多くなればなるほど、AIが真価を発揮します。ターゲットが出力できる様々なデータをAIに渡して、予想してみてください。
その際に注意しなければならないことは、AIに渡せるデータは「数値」のみであるということです。
たとえば、我々が競馬を予想する際には「騎手は誰か」ということを考慮しますが、AIに騎手名を渡しても、それを理解することができません。過去のレース結果から各騎手の勝利数や勝率を計算して渡す、などの手段でうまくデータを作る技術が必要となってきます。
機械学習についてもっと知りたい方は、以下のテキストを読むことをお勧めします。
最後に、本記事で使用したソースコードを参照できるようにしてあります。参考までに。
この記事が気に入ったらサポートをしてみませんか?