Andrew先生の分かりやすすぎるMachine Learning パート① (ともし)

久しぶりすぎて、庇(ひさし)を買おうか悩んでます、どうもおしとやか関西人のともしです。
本日より、
「Machine Learning(機械学習)を素人にでも分かるように
解説してみようシリーズ」を始めたいと思います〜〜〜(パチパチ)
僕自身、ウェズリアンでの1年目が終わった夏休みに、機械学習を先取りで学ぼうと思い、機械学習をタダで、でもしっかり学びたい人の多くが使っている教材として人気な、Stanford大学の教授&人工知能の第一人者とも言われたAndrew Ng先生の「Machine Learning」の授業をCOURSERAで受けました。日本語字幕もあって、日本人でも受講している人は結構いたりします。
ちなみにCOURSERAは、世界中の有名大学の授業がオンラインで無料で受けられるMOOC (Massive Open Online Course) の一つですね。しかも、Andrew先生ってCOURSERAの創始者の一人っていう(今日知った)。
ほんでそれはWeek11まであるんですけど、夏休みはお恥ずかしながら、難しくて途中(Week6)で挫折してしまい、冬休みにもう一度おさらいして挑戦したものの再び挫折してしまいました。聞いて分かってる状態と人に教えられる状態は実は全然理解度がちゃうぞとよく言われるじゃないですか。そこでですよ、僕がここで初学者の方にでも分かりやすく教えられる様になれば、僕の理解も深まるし、皆さんのタメになるし、お互いにwinwinやと思った訳です。いつか5年後くらいにこの記事がバズったらいいなー。
代表的な学習法
機械学習における代表的な学習方法として、
1. 教師あり学習(Supervised Learning)
2. 教師なし学習(Unsupervised Learning)
があります。
強化学習、半教師あり学習など他にも色々ありますが、とにかく今はこの二つから始めましょ。
0. 大前提
・機械学習のAIは、xを入力した時に、yを(予測として)出力する。
例)とあるAさんの年齢、体重、業種、役職をxとして入力すると、
y(予測)として、Aさんの年収を出力(予測)してくれる。
・機械学習のAIがそういう予測をできる「大人」になるように、「訓練データ(training set)」を使って学習させる(要は子育て)。
・教師あり/なし学習の違いは、訓練データの一つ一つに、
答え(=出力)がついているか、ついていないか。
1. 教師あり学習
教師あり学習の訓練データ
BさんからZさんのそれぞれの年齢、体重、業種、役職だけでなく
彼らの実際の年収も訓練データに含まれている。
できることの一例
・分類(classification): 出力が何択かのみ
・陽性か陰性か
・このお客さんの今の気分は魚か肉か野菜か
・回帰(regression): 出力が連続的な数値
・年収がいくらか
2. 教師なし学習
教師なし学習の訓練データ
500通のメールの文面しかデータにない。
そのメールが迷惑メールなのか、ビジネスメールなのか、
その答えは与えられない。
できることの一例
・クラスタリング
・大量のメールを何となく似ているもの同士でグループ分け
新しいメールを入力すると、それがどのグループに属すか出力。
さぁこっからが本番です。
線形回帰のモデル(Linear regression)
【今回の前提】
・訓練データの数をm個とします。
・まずはシンプルに、入力の変数が1つしかないとしましょう。
・入力データをx、出力をy とします。
つまり、「勉強時間」という一つの変数xで「テストの点数」yを予測するようなイメージ。
AIはxをもらって、yを予測する(仮説を立てる = hypothesize)ので、
![]()
つまり、yは「xを使ってAIがhypothesizeしたものだよ」言い換えられて、
![]()
AIの中身はこのように言える訳です。いやθって何やねんと思ったそこのあなた。
数式だけで考えずに、二次元のグラフ上で考えてみましょう。
横軸はx軸、勉強時間。
縦軸はy軸(もしくはh(x))、テストの点数。
m個のデータがもうすでにプロットされてるのをイメージしてください。
そう考えると、θ1は直線の傾き、θ0はy切片。
この二つのθを明らかにして直線の方程式を定めるのが、機械学習の中身なんです。
θを定めたい
じゃあどうやってθを定めるのか。テストの例で続けます。
● m = 1
仮に訓練データが1つしかなかったとして(m = 1)、
それが「20hで60点」のデータやとします。
このデータ一つやと、
60 = 0 + 3 * 20
や
60 = 20 + 2 * 20
など、θの組み合わせは無限に選択肢があるイメージ。むう。
● m = 2
もしm = 2で、もう一つのデータが「30hで80点」だったとすると...
それはもう
60 = 20 + 2 * 20
80 = 20 + 2 * 30 で
θ0 = 20, θ1 = 2 の一択です。二点を通る直線は一つしか存在しないですもんね。
ほうほう。
でも現実はそんなに甘くない。
● m = 3
もしm = 3で、もう一つのデータが「25hで75点」だったとすると...
直線上では20 + 2 * 25 = 70点なので、実際のデータとズレてますよね。
しかも現実のmはもっと大きい(訓練データの数は3つじゃ済まない)。
要は、全ての点を通れるような「直線」は初めから期待されていないんです。
じゃぁどうすればいいのか?
答えは、
「どの点からも、できる限り近くなるような、いい感じの直線を選ぶ」
ということです。
何やその曖昧な定義は! まぁまぁ餅ついて。
コスト関数
例えば、3つ目のデータの話で言うと、75-70で5点分ズレてる訳ですよね。つまり、直線に対して、m個のそれぞれのデータの「ズレ」を合計して、その合計が一番小さくなるような直線を最適解とする、ということです。
このズレの合計のことをコストと呼び、
コスト関数は以下になります:
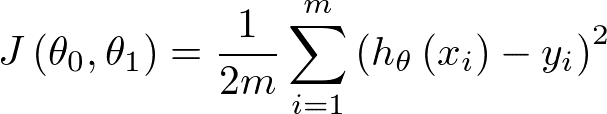
まず、x iはi番目のxの値のことです。yも同様。
よって、2乗の中身は、(i番目のxを入れた場合の直線が予想したy) - (実際のy)
なので、要は、先程の75-70のような、「ズレ」ですね。
先ほどは、その一つ一つのズレを単に合計すると言いましたが、
数式上ではうまくいきません。なぜかというと、
・予想75-実際は70 の場合、ズレは5で、正の値になりますが、
・予想65 - 実際は70の場合、ズレは-5で、
そのまま足し合わせてしまうと小さくなってしまうからですね。2乗する事でどちらも25と正の値に生まれ変わります。
それを1番目のデータのズレ(の2乗)から、最後のm番目のデータのズレ(の2乗)までを足し合わせて、2mで割っています。
mで割るのは、平均を取るイメージ。それに2がついているのは、後々の計算の関係上です。あまり気にしなくていいです。
Jにθがついてるのは、コスト関数がθの関数だよっていうサインです。
高校数学でも f(x) = x + 1 とか、f(x, y) = x + 2y + 1 みたいな感じで
これはxとかy(のみ)を変数にもつ関数だよーって書き方しますよね。
だから、コスト関数は、θ1とθ2(のみ)を変数にもつ関数だという事です。
まぁよく考えていれば当たり前で、
コストは、直線の移動(直線をずらす(θ0の変化)、直線を回転させる(θ1の変化))によって変化しますからね。
さてさて、というわけでこちらが、
先生が描いていたコスト関数のイメージグラフになります。
赤い矢印や黒いバツは無視してください!
2変数に加えてJの軸で、3次元なので、ギリギリ可視化できますね。
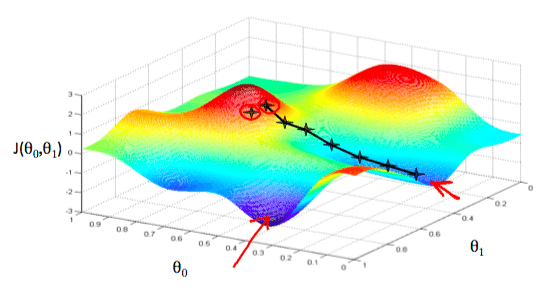
お盆型になるので、お盆の底が、コストJの最小値であり、
その点におけるθ0とθ1が(その直線が)、最適な解として
見事AIさんに使われるわけです。(パチパチ)
今回は「勉強量」という1変数だったのでグラフで可視化できましたが、
変数が増えれば増えるほどもっとややこしくなります。
でも、基本的なイメージはこれで掴めたのではないでしょうか。
じゃぁ一体どうやって、そのお盆の底を計算で見つけるのか?
その手法を次回はご説明したいと思います!
最後に雑談
先日見た夢
おじさん: 君、アーリーアダプターにならないかね..?
僕: いやぁ〜どうでしょう、お金ないし、やっぱリスクあるじゃないですか。(いやお前誰やねん)
おじさん: 300円で良いんだよ、300円で。
僕: (え、安ない?)
僕: (300円でアーリーアダプターになれるとか、これはなるしかないやろ..)
色々訳わからんやろ
この記事が気に入ったらサポートをしてみませんか?