AWS エバンジェリストシリーズ AWSの基礎を学ぼう 「人を笑わせるAIをつくってみる AWS Summit 直前Special 電笑戦のモデルをつくる」 に参加したよ #awsbasics #電笑戦 #AIでボケた

TL;DR
今日はこちらの勉強会に参加しました
AWS Summitとの連動企画 「ボケて電笑戦」
来週開催されるAWS Summitの企画「ボケて電笑戦」との連動企画です。
boketeというお笑いWebサービスを運営されている、オモロキさんが保管されているボケ画像のデータを利用されるそうです。
AWS Summitの情報はこちら。
ちなみに、「ボケて電笑戦」のホストはFUJIWARAさんです。








AWSのAI/MLスタックが提供されています

今回のハンズオンでは以下のサービスを使います
SageMaker Studio
SageMaker Processing = 前処理
SageMaker Training Jobs = トレーニング
SageMaker Endpoints
事前作業
事前作業として、SageMakerの上限緩和申請を行いました。
ハンズオン
ノートブックインスタンスの作成
今回はノートブックインスタンスを作成しました


ここで git clone https://github.com/aws-samples/bokete-denshosen.git することもできます

上から順に一つずつ実行(Shift + Enter)します

↓のコードが出たら、前処理が進行中です…
The above processing job will upload the training data to Amazon S3. Let's retrieve the path for the next step.結局完遂できなかった
はい。ブログをイベント当日に公開することを目標としていたんですが、できませんでした。そして公開しないまま2週間が経とうとしている…。
結論から言うと、ハンズオンを完遂できませんでした。なぜかというと、前処理までは完了したんですが、、、
その後の手順でエラー発生
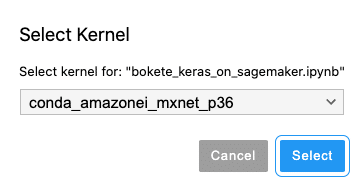
Kernelの選択を間違っていた事が判明
Kernelを選択し直し、手順をリランしたものの、グチャグチャになって時間切れ
となりました。ちょっと時間を見つけてリトライしようと思います。
AWS Summit アーカイブ見れますね
AWS Summitも先週開催されて、ここで取り上げた電笑戦も、ライブ配信されました。
私は当日ライブ配信を見れなかったので、アーカイブ配信を見ようと思います!
#電笑戦 のセッションは、#AWSSummit のオンデマンド配信でもご覧いただけます。
— AWS/アマゾン ウェブ サービス/クラウド (@awscloud_jp) June 2, 2022
閲覧はこちらからどうぞ➡️https://t.co/ej1Ac1DZNn
※配信は 6 月 30 日(木)まで
※閲覧にはイベントへの登録が必要です pic.twitter.com/3HDDOeQ4pP
この記事が気に入ったらサポートをしてみませんか?