
【Pythonコード】Webスクレイピングで高配当株 スクリーニング自動化ツールを作成してみた①

どうも、こじまるです。
日本の個別株への高配当株投資を始めました。毎日株価をスクリーニングツールなどで確認しているのですが、スクリーニングツールで検索条件を設定していちいち検索作業をするのが面倒です。そのため、スクリーニング条件と一致する株価情報を配信してくれるツールを作成しようと思いました。
1.はじめに
対象読者
・Webスクレイピングを始めたいと思っている方
・高配当株のスクリーニングツールに興味がある方
この記事を見てわかること
・Webスクレイピングの事前準備、実施方法、実装方法
2.スクリーニング条件
私が高配当株の購入をするための目安にしているスクリーニングの条件は、下記になります。
1.配当利回り : 3.75%以上
2.PBR : 1.5倍以下
3.配当性向 : 50%以下
4.自己資本比率 : 50%以上
5.売上営業利益率 : 10%以上
6.配当実績(増配傾向)
この中でも、1.配当利回り、6.配当実績(増配傾向)を最も重要視しています。こちらのスクリーニング条件は、こびと株さんのブログを参考に決定しました。
3.事前調査
調査の進め方は、下記の記事を参考に調査を進めました。詳しく知りたい方は確認してください。
プログラムで株の情報を取得する方法
プログラムで株の情報を取得する方法として、下記の2通りの方法があります。
1.APIの利用
2.Webスクレイピングの利用
Webスクレイピングが禁止されているにも関わらず、それを実施してしまうことは問題になります。事前に情報提供元に確認するようにしましょう。
APIの利用
情報提供元がAPIを提供している場合には、それを活用した方がいいです。
株価の情報が取得できるAPIとして、下記が見つかりました。
・Yahoo financial API
・Alpha Vantage
上記のAPIを確認しましたが、株価の情報は取得できましたが、配当金情報の取得は出来ませんでした。APIを公開しているサービスの情報は下記を参考にしました。
Webスクレイピングの利用
APIが利用できない場合には、Webスクレイピングの利用を検討します。ただし、Webスクレイピングは情報提供元が禁止している場合もありますので、事前に確認が必要です。
Webスクレイピングが可能かどうかは、robots.txtを確認することで判断できます。たいていは、https://minkabu.jp/robots.txt のようにFQDNの直下にあります。robots.txtには、Webスクレイピングを行うロボットに対して、禁止している事項などが記載されています。下記は今回使用するみんなの株式のrobots.txtになります。
User-Agent: *
Allow: /
Sitemap: https://assets.minkabu.jp/concerns/sitemap/sitemap.xml.gz
Sitemap: https://assets.minkabu.jp/concerns/sitemap/news/sitemap.xml.gz
Sitemap: https://minkabu.jp/hikaku/sitemap.xml
Sitemap: https://minkabu.jp/beginner/sitemap.xml
Disallow: /user/follow/
Disallow: /user/unfollow/
Disallow: /user/add_favorite_user/
Disallow: /user/add_favorite_stock/
Disallow: /user/add_respect_user/
Disallow: /user/switch/
Disallow: /user/resign/
Disallow: /message/to/
Disallow: /blog/edit
Disallow: /stocks/pick/open_form
Disallow: /stock/*/community/edit
Disallow: /simulation/simple/start
Disallow: /community/join/
Disallow: /groups/topic/edit
Disallow: /invite/group/
Disallow: /home
Disallow: /top/report/
Disallow: /94446337/
Disallow: /hikaku/redirect/上記の場合、Allowですべての公開ページを許可していますが、Disallowにはその中でもアクセスさせたくないページを記載しています。
情報取得先
上記の調査より、情報取得先を決定しました。
・日本取引所グループ
・みんなの株式
・IP BANK
・おかねまみれ
銘柄コードとスクリーニング条件に含まれる株価・配当金情報は下記より取得します。
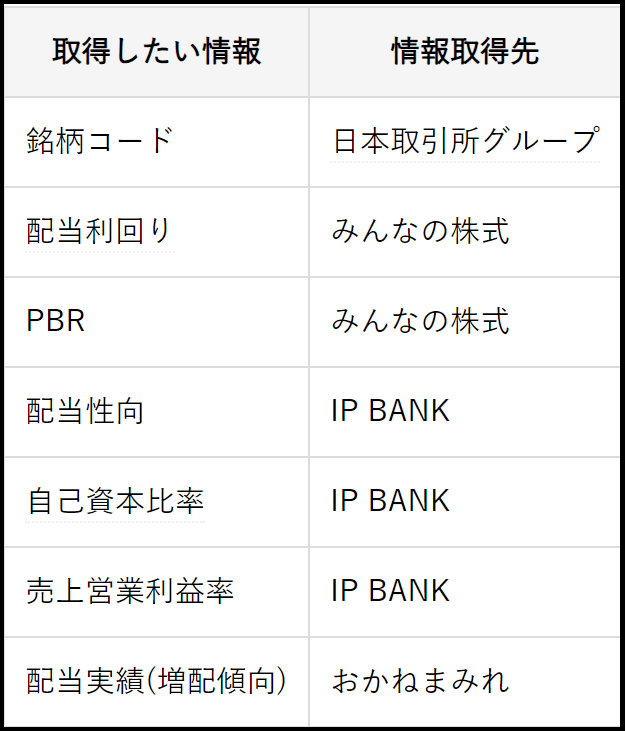
取得ページ・ファイル
情報を取得したページ・ファイルは下記の通りになります。
・日本取引所グループ
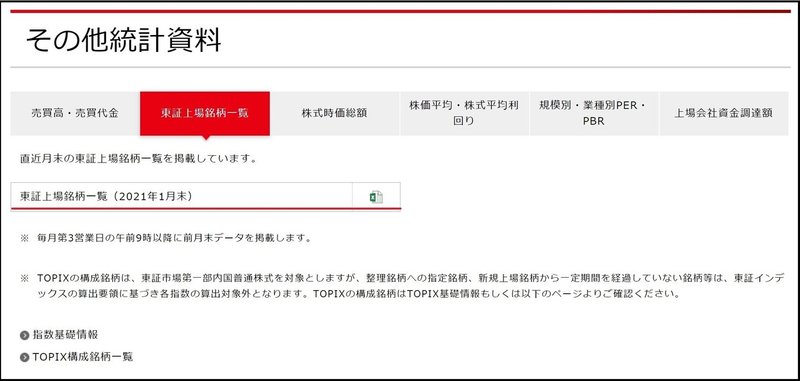
出典 : https://www.jpx.co.jp/markets/statistics-equities/misc/01.html
・みんなの株式
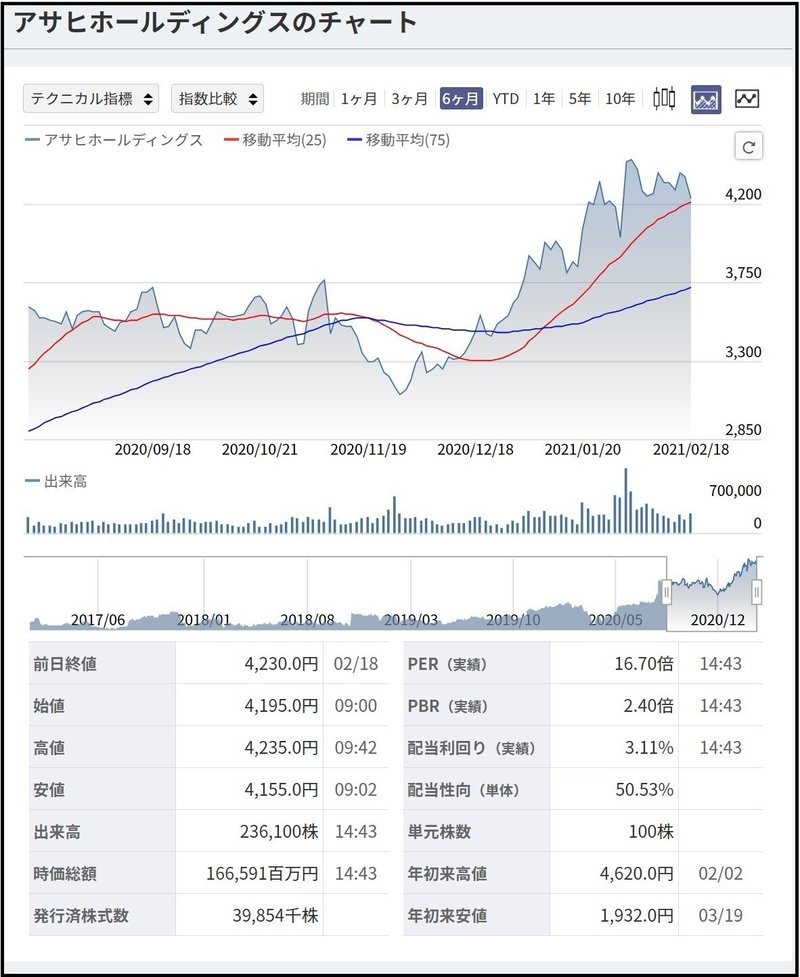
出典 : https://minkabu.jp/stock/5857/chart
・IP BANK
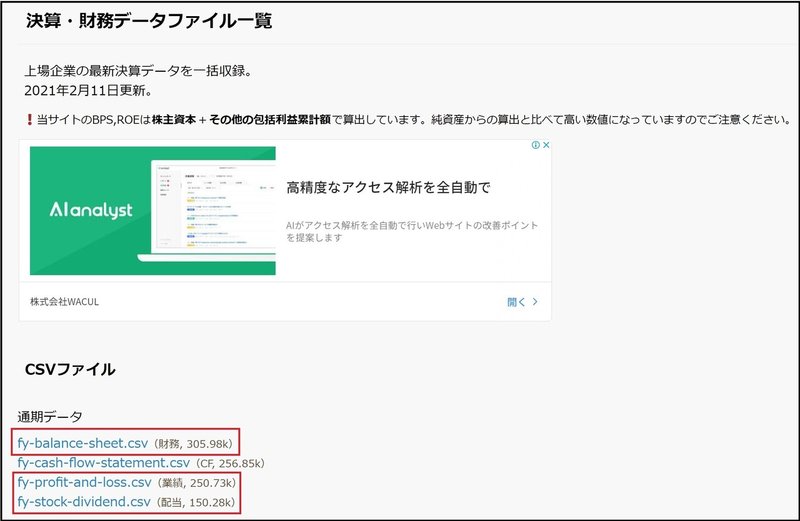
出典 : https://irbank.net/download
・おかねまみれ

出典 : https://okanemamire.net/check-stocks-dividend/
4.スクリーニングツール作成
要件定義
ツール作成に定めた要件としては、下記になります。
要件1.平日の特定の時間帯にツールが自動で動作すること。
要件2.東証一部上場の株式情報を取得すること。
環境構築
今回はPythonを使って作成しました。pipで下記のパッケージをインストールしています。
pip install requests
pip install pandas
pip install lxml
pip install xlrd
pip install openpyxlファイルの連結
IP BANK、おかねまみれから取得する情報は決算情報や配当金の情報になります。この情報を平日に毎回取得する必要はないので、事前にcsvファイルをマージしたものを作ります。
下記のコードで必要な列情報のみを読み取り、コードにより連結しました。(各csvファイルは1行目にヘッダが表示されるように事前処理しています。)
import pandas as pd
stock_dividend_path = 'fy-stock-dividend.csv'
profit_loss_path = 'fy-profit-and-loss.csv'
blance_path = 'fy-balance-sheet.csv'
dividend_record_path = '国内株配当実績取得ツール_20200513.xlsm'
target_path = 'fy-merged-sheet.csv'
blance_data_frame = pd.read_csv(blance_path,usecols=['コード','年度','自己資本比率'])
profit_data_frame = pd.read_csv(profit_loss_path,usecols=['コード','売上高','営業利益'])
stock_data_frame = pd.read_csv(stock_dividend_path,usecols=['コード','一株配当','配当性向'])
dividend_record_data_frame = pd.read_excel(dividend_record_path,usecols=['コード','連続増配','減配なし'])
data_list = [blance_data_frame, profit_data_frame, stock_data_frame, dividend_record_data_frame]
tmp = data_list[0]
for data in data_list[1:]:
tmp = pd.merge(tmp,data,on='コード')
tmp.to_csv(target_path,index=False,encoding='shift-jis')連結したcsvファイルは下記の通りです。
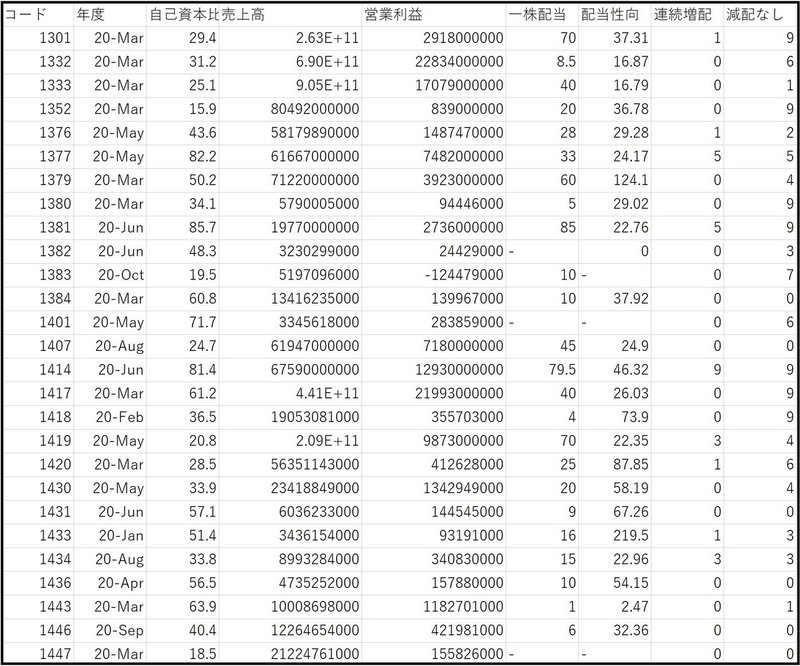
東証一部上場の銘柄のコード取得
要件として、東証一部上場の株式情報を取得するとしています。事前準備で用意したファイルには、東証一部上場以外の企業も含まれていますので、銘柄コードを取得します。
日本取引所グループのサイトからDeveloper Toolを使用して、東証上場銘柄一覧のファイルパスを取得します。
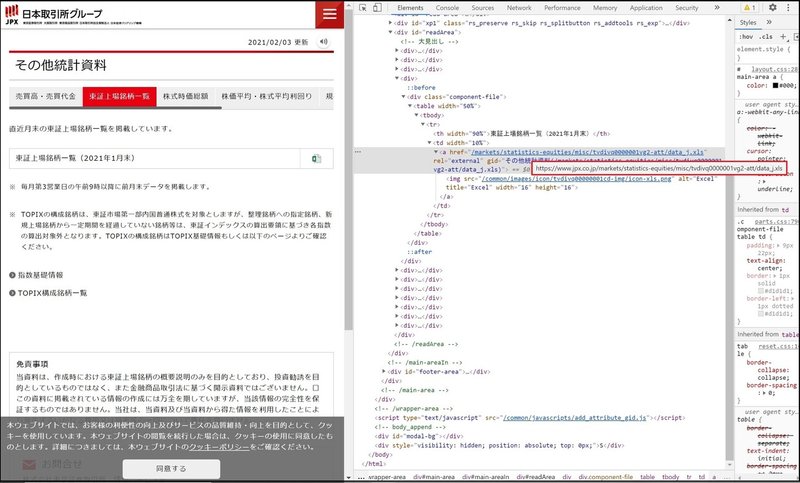
そのExcelシートから、"コード"、"銘柄名"、"市場・商品区分"、"17業種区分"を取得します。
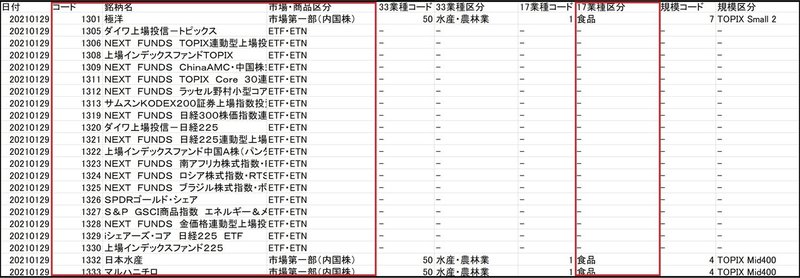
ソースコードは下記の通りになっています。
# Obtain the code and stock information listed on the First Section of the Tokyo Stock Exchange from https://www.jpx.co.jp/.
source_path = 'https://www.jpx.co.jp/markets/statistics-equities/misc/tvdivq0000001vg2-att/data_j.xls'
data_frame = pd.read_excel(source_path,usecols=['コード','銘柄名','市場・商品区分','17業種区分'],sheet_name='Sheet1')
stock_data_frame = data_frame[data_frame['市場・商品区分']=='市場第一部(内国株)']Webスクレイピング
みんなの株式の株価、配当金情報を取得します。
下記のサイトのURLは、https://minkabu.jp/stock/5857/chartのようになっています。この5857が銘柄コードになっており、他の銘柄の情報を取得する場合には銘柄のコードを変更する必要があります。
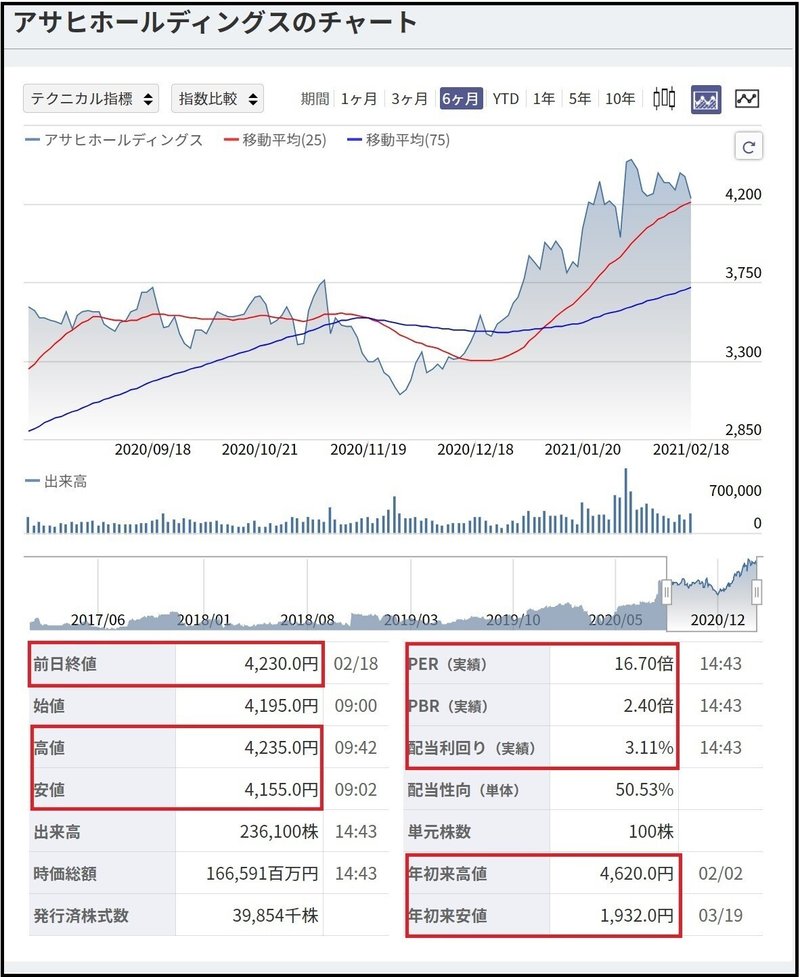
そのため、"東証一部上場のコード取得"で取得した銘柄コードを使って、URLを作ります。その後に、requestsのgetメソッドを使ってHTMLページを取得する形で実装しました。
chart_url = "https://minkabu.jp/stock/" + str(stock_code) + "/chart"
try:
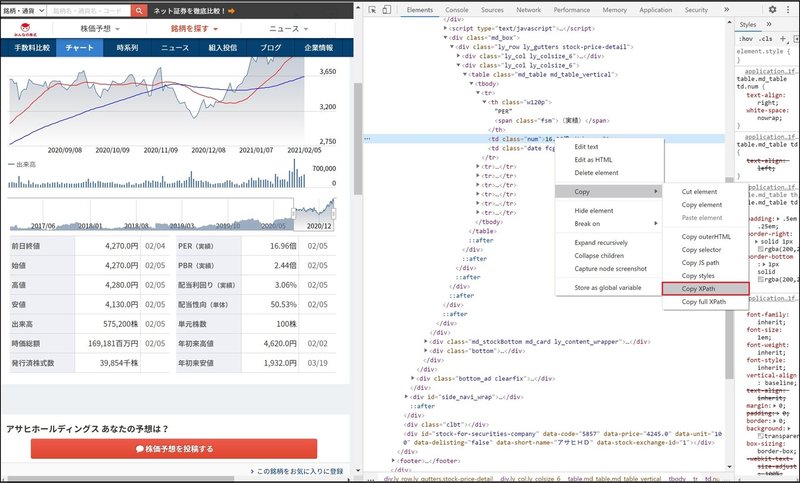
chart_html = requests.get(chart_url)取得する株の情報は、下記の形でXPathで参照しています。
# 配当利回り
stock_dividend_yield = parse_dom_tree(chart_dom_tree,'//*[@id="contents"]/div[3]/div[1]/div/div/div[2]/div/div[2]//tr[3]/td[1]','%','')XPathはDeveloper Toolで取得することができます。
スクリーニング
配当利回りと配当実績(増配傾向)は、優先度が高いので、それらが空になっているものはExcelデータに出力しないようにしています。
スクリーニングの定義と条件は下記のように実装しました。
# スクリーニングの定義
ENABLE_DIVIDEND_YIELD = True
TARGET_DIVIDEND_YIELD = 3.75
...
# スクリーニングの条件
def util_screening(dividend_yield,dividend_payout_ratio,pbr,capital_adequacy_ratio,operating_profit_ratio,continuous_dividend_increase):
if ENABLE_DIVIDEND_YIELD:
# Dividend_yield has a high priority and does not allow None.
if dividend_yield is not None and dividend_yield >= TARGET_DIVIDEND_YIELD:
pass
else:
return False
...スクリーニング結果
"市場第一部(内国株)"の2191件の中から3件の株式情報が取得できました。配当利回りの高い銘柄から順に確認するため、配当利回りでソートするようにしています。
![]()
※上記のキャプチャでは一部の情報のみ表示しています。実際には、下記の情報が表示されます。
columns = ['コード',\
'銘柄',\
'前日終値',\
'高値',\
'安値',\
'年初来高値',\
'年初来安値',\
'PER(倍)',\
'PBR(倍)',\
'配当利回り(%)',\
'年度',\
'売上高',\
'営業利益',\
'営業利益率',\
'自己資本率',\
'一株配当',\
'配当性向(%)',\
'連続増配',\
'減配なし',\
'業種']ソースコード
ソースコードは下記のようになります。
import requests
import pandas as pd
import lxml.html
import sys
import time
from time import strftime
SCREENING = True
ENABLE_DIVIDEND_YIELD = True
TARGET_DIVIDEND_YIELD = 3.75
ENABLE_PAYOUT_RATIO = True
TARGET_PAYOUT_RATIO = 50
ENABLE_PBR = True
TARGET_PBR = 1.5
ENABLE_CAPTIAL_ADEQUACY_RATIO = True
TARGET_CAPTIAL_ADEQUACY_RATIO = 50
ENABLE_OPERATING_PROFIT_RATIO = True
TARGET_OPERATING_PROFIT_RATIO = 10
ENABLE_CONTINUOUS_DIVIDEND_INCREASE = True
TARGET_CONTINUOUS_DIVIDEND_INCREASE = 3
"""
# Purpose
Convert source variable contained in str variable to destination variable.
"""
def util_replace(text, source, destination):
# if text has source
if text.find(source) > 0:
# remove unnecessary ','
tmp = text.replace(',','')
return float(tmp.replace(source, destination))
else:
# Replace non-valued data with None.
return None
"""
# Purpose
Confirm that it matches the following conditions.
"""
def util_screening(dividend_yield,dividend_payout_ratio,pbr,capital_adequacy_ratio,operating_profit_ratio,continuous_dividend_increase):
if ENABLE_DIVIDEND_YIELD:
# Dividend_yield has a high priority and does not allow None.
if dividend_yield is not None and dividend_yield >= TARGET_DIVIDEND_YIELD:
pass
else:
return False
if ENABLE_PAYOUT_RATIO:
# Since dividend_payout_ratio has a low priority, allow None.
if dividend_payout_ratio is None or dividend_payout_ratio <= TARGET_PAYOUT_RATIO:
pass
else:
return False
if ENABLE_PBR:
# Since pbr has a low priority, allow None.
if pbr is None or pbr <= TARGET_PBR:
pass
else:
return False
if ENABLE_CAPTIAL_ADEQUACY_RATIO:
if capital_adequacy_ratio is None or capital_adequacy_ratio >= TARGET_CAPTIAL_ADEQUACY_RATIO:
pass
else:
return False
if ENABLE_OPERATING_PROFIT_RATIO:
# Since operating_profit_ratio has a low priority, allow None.
if operating_profit_ratio is None or operating_profit_ratio >= TARGET_OPERATING_PROFIT_RATIO:
pass
else:
return False
if ENABLE_CONTINUOUS_DIVIDEND_INCREASE:
# Since continuous_dividend_increase has a high priority, does not allow None.
if continuous_dividend_increase is not None and continuous_dividend_increase >= TARGET_CONTINUOUS_DIVIDEND_INCREASE:
pass
else:
return False
return True
"""
# Purpose
Parse dom_tree and get text data.
"""
def parse_dom_tree(dom_tree, xpath, source, destination):
raw_data = dom_tree.xpath(xpath)
data = util_replace(raw_data[0].text,source,destination)
return data
"""
# Purpose
Confirm that the string can be converted to float type.
"""
def isfloat(text):
try:
float(text)
except ValueError:
return False
else:
return True
"""
# Purpose
Convert string type to float type.
"""
def convert_string_float(text):
if isfloat(text):
return float(text)
else:
return None
if __name__ == '__main__':
# Obtain the code and stock information listed on the First Section of the Tokyo Stock Exchange from https://www.jpx.co.jp/.
source_path = 'https://www.jpx.co.jp/markets/statistics-equities/misc/tvdivq0000001vg2-att/data_j.xls'
data_frame = pd.read_excel(source_path,usecols=['コード','銘柄名','市場・商品区分','17業種区分'],sheet_name='Sheet1')
stock_data_frame = data_frame[data_frame['市場・商品区分']=='市場第一部(内国株)']
merged_data_path = 'fy-merged-sheet.csv'
merged_data_frame = pd.read_csv(merged_data_path,encoding='shift-jis',usecols=['コード','年度','自己資本比率','売上高','営業利益','一株配当','配当性向','連続増配','減配なし'])
stock_merged_data_frame = merged_data_frame.set_index('コード')
output_list = []
for index,row in stock_data_frame.iterrows():
stock_code = row[0]
stock_name = str(row[1])
stock_industry_type = str(row[3])
if stock_code in stock_merged_data_frame.index:
merged_data_list = stock_merged_data_frame.loc[int(stock_code)]
else:
continue
chart_url = "https://minkabu.jp/stock/" + str(stock_code) + "/chart"
try:
chart_html = requests.get(chart_url)
chart_html.raise_for_status()
chart_dom_tree = lxml.html.fromstring(chart_html.content)
print(stock_code)
# 前日終値
stock_previous_closing_place = parse_dom_tree(chart_dom_tree,'//*[@id="contents"]/div[3]/div[1]/div/div/div[2]/div/div[1]//tr[1]/td[1]','円','')
#print('stock_previous_closing_place : ' + str(stock_previous_closing_place))
# 高値
stock_high_place = parse_dom_tree(chart_dom_tree,'//*[@id="contents"]/div[3]/div[1]/div/div/div[2]/div/div[1]//tr[3]/td[1]','円','')
#print('stock_high_place : ' + str(stock_high_place))
# 安値
stock_low_place = parse_dom_tree(chart_dom_tree,'//*[@id="contents"]/div[3]/div[1]/div/div/div[2]/div/div[1]//tr[4]/td[1]','円','')
#print('stock_low_place : ' + str(stock_low_place))
# PER
stock_per = parse_dom_tree(chart_dom_tree,'//*[@id="contents"]/div[3]/div[1]/div/div/div[2]/div/div[2]//tr[1]/td[1]','倍','')
#print('stock_per : ' + str(stock_per))
# PBR
stock_pbr = parse_dom_tree(chart_dom_tree,'//*[@id="contents"]/div[3]/div[1]/div/div/div[2]/div/div[2]//tr[2]/td[1]','倍','')
#print('stock_pbr : ' + str(stock_pbr))
# 年初来高値
stock_high_place_per_year = parse_dom_tree(chart_dom_tree,'//*[@id="contents"]/div[3]/div[1]/div/div/div[2]/div/div[2]//tr[6]/td[1]','円','')
#print('stock_high_place_per_year : ' + str(stock_high_place_per_year))
# 年初来安値
stock_low_place_per_year = parse_dom_tree(chart_dom_tree,'//*[@id="contents"]/div[3]/div[1]/div/div/div[2]/div/div[2]//tr[7]/td[1]','円','')
#print('stock_low_place_per_year : ' + str(stock_low_place_per_year))
# 配当利回り
stock_dividend_yield = parse_dom_tree(chart_dom_tree,'//*[@id="contents"]/div[3]/div[1]/div/div/div[2]/div/div[2]//tr[3]/td[1]','%','')
#print('stock_dividend_yield : ' + str(stock_dividend_yield))
# 年度
stock_term = merged_data_list['年度']
# 自己資本比率
stock_capital_adequacy_ratio = merged_data_list['自己資本比率']
# 売上高営業利益率 営業利益 / 売上高
stock_operating_profit = convert_string_float(merged_data_list['営業利益'])
stock_sales = convert_string_float(merged_data_list['売上高'])
if stock_operating_profit is None or stock_sales is None:
stock_operating_profit_ratio = None
else:
stock_operating_profit_ratio = (stock_operating_profit / stock_sales) * 100
# 一株配当
stock_dividend_per_share = convert_string_float(merged_data_list['一株配当'])
# 配当性向
stock_dividend_payout_ratio = convert_string_float(merged_data_list['配当性向'])
# 連続増配
stock_continuous_dividend_increase = merged_data_list['連続増配']
# 減配なし
stock_dividend_reduction = merged_data_list['減配なし']
if(SCREENING == True):
if(util_screening(stock_dividend_yield,stock_dividend_payout_ratio,\
stock_pbr,stock_capital_adequacy_ratio,\
stock_operating_profit_ratio,stock_continuous_dividend_increase)):
list = [stock_code,\
stock_name,\
stock_previous_closing_place,\
stock_high_place,\
stock_low_place,\
stock_high_place_per_year,\
stock_low_place_per_year,\
stock_per,\
stock_pbr,\
stock_dividend_yield,\
stock_term,\
stock_sales,\
stock_operating_profit,\
stock_operating_profit_ratio,\
stock_capital_adequacy_ratio,\
stock_dividend_per_share,\
stock_dividend_payout_ratio,\
stock_continuous_dividend_increase,\
stock_dividend_reduction,\
stock_industry_type]
else:
continue
else:
list = [stock_code,\
stock_name,\
stock_previous_closing_place,\
stock_high_place,\
stock_low_place,\
stock_high_place_per_year,\
stock_low_place_per_year,\
stock_per,\
stock_pbr,\
stock_dividend_yield,\
stock_term,\
stock_sales,\
stock_operating_profit,\
stock_operating_profit_ratio,\
stock_capital_adequacy_ratio,\
stock_dividend_per_share,\
stock_dividend_payout_ratio,\
stock_continuous_dividend_increase,\
stock_dividend_reduction,\
stock_industry_type]
output_list.append(list)
except requests.exceptions.RequestException as e:
print(e)
columns = ['コード',\
'銘柄',\
'前日終値(円)',\
'高値(円)',\
'安値(円)',\
'年初来高値(円)',\
'年初来安値(円)',\
'PER(倍)',\
'PBR(倍)',\
'配当利回り(%)',\
'年度',\
'売上高',\
'営業利益',\
'売上高営業利益率',\
'自己資本率',\
'一株配当',\
'配当性向(%)',\
'連続増配',\
'減配なし',\
'業種']
output_data_frame = pd.DataFrame(data=output_list,columns=columns)
sorted_output_data_frame = output_data_frame.sort_values('配当利回り(%)',ascending=False)
localtime = strftime("%y%m%d_%H%M%S",time.localtime())
output_file_name = './stock_' + localtime + '.xlsx'
sorted_output_data_frame.to_excel(output_file_name,index=None,engine='openpyxl')
||<5.まとめ
Webスクレイピングを行って、高配当株の管理に使用するスクリーニングツールを作成しました。要件2を満たすものは出来たので、続きとして要件1を満たすように実装したいと思います。
続編はこちらになります。
この記事が気に入ったらサポートをしてみませんか?