
並列処理入門 Pythonでの大規模データの爆速処理をDaskではじめよう

こんにちは。コグラフ株式会社データアナリティクス事業部のワダです。
データ分析関連の業務で多くの人が遭遇するのが「大きなサイズのデータをどう処理するか」問題だと思います。Pythonのデータ分析用ライブラリであるPandasは便利ではありますが、大きなデータになると処理が遅い、挙句にはメモリ不足でクラッシュしてしまう等の状況に出くわします。
今回はそんなビッグデータを扱う上で便利な手法である「並列処理」「平行処理」の概要とその具体的な実装についてご紹介します。今回はテーブルデータを並列処理で実行できるライブラリ「Dask」を用いて、高速データ処理を初めて学ぶ人でも無理なく実装でき、効果を体感できる内容を目指します。
※WindowsPC上のjupyter notebookで動作を確認しています
※まずは実装する、というところを目指すため、CPU等の詳細説明は割愛します
並列処理とは
逐次処理との違い
基本的なPythonコードは、上から下へと順々に実行されます。これを逐次処理と呼び、前の処理が終了してから次の処理へと移っていきます。
#pandasでの実行例
import pandas as pd
df_a = pd.read_csv('hoge/hoge/file1.csv')
df_b = pd.read_csv('hoge/hoge/file2.csv')
df_c = pd.read_csv('hoge/hoge/fil.csv')上記はPandasでCSVファイルを読み込む例ですが、file1の読み込みが終了してからfile2、file2が終わってからfile3の読み込みが始まります。これを同時に読み込んで処理時間を短縮させる、というのが並列処理の発想です。
並行処理との違い
並列処理と似た概念として「並行処理」というものがあります。同時に複数タスクを処理するというところまでは共通なのですが、
並行処理は「単一の」コアで「複数のタスクを交互に実行する」のに対し、「複数の」コアで「複数のタスクを同時に処理する」というのが並列処理です。以下が概念図です。
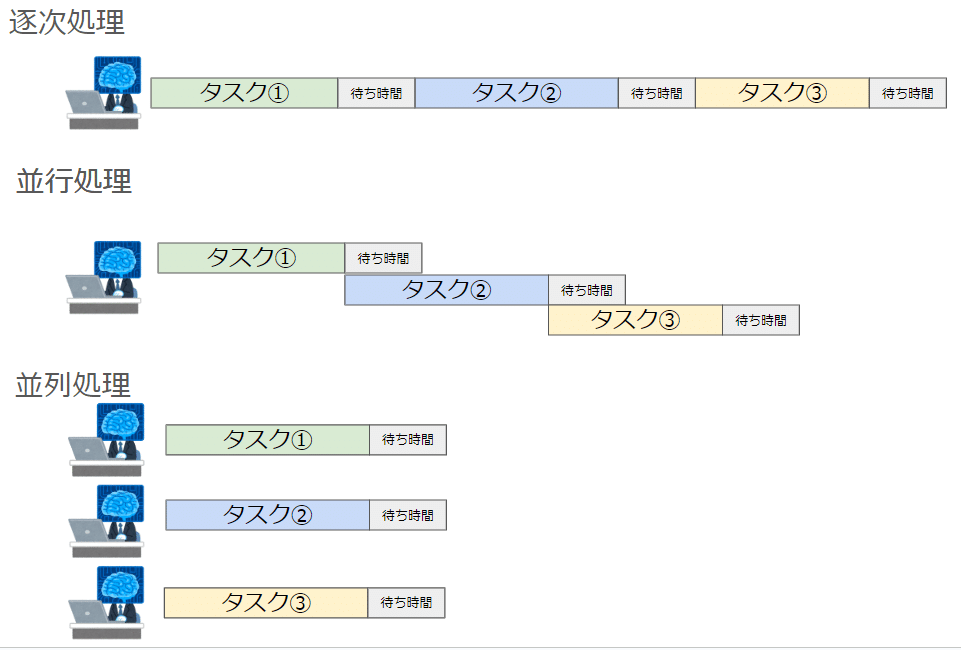
図をみれば、なんとなく処理の速度に違いが出そうなイメージを持てるのではないでしょうか。
並列処理は大量の数値計算処理といったCPUのリソースを大量に必要とする処理に向いており、並行処理はWebAPIの利用など待ち時間の長い処理に使われます。
次章以降では実際にどう実装するのか、どのくらい処理時間に違いが出てくるのかについて詳しく見ていきます。
Daskの概要
Daskとは並列処理、分散処理に特化した分析ライブラリです。NumpyやPandasと同じような書き方で、大規模データの分析の実装が可能です。

デモデータ
今回はランダムに生成した巨大データを用います。以下のコードで作成しました。容量は約1.88GBです。
# データのサイズ
num_rows = 10**7 # 1,000万行
num_cols = 10 # 列数
# ランダムデータの生成
data = np.random.rand(num_rows, num_cols)
# DataFrameの作成
df = pd.DataFrame(data, columns=[f'col_{i}' for i in range(num_cols)])
# データの保存
df.to_csv('large_dataset.csv', index=False)実装と速度比較
Daskは機能ごとにライブラリが分かれています。ひとまずすべての機能を入れるには以下の通りpipでインストールします。
pip install "dask[complete]"Daskを用いてデータフレームを操作するにはdask.dataframeをインポートします。そのままデータを読み込んでみます。
import pandas as pd
import dask.dataframe as dd
train_df = pd.read_csv('/hoge/hoge/large_dataset.csv')
train_ddf = dd.read_csv('/hoge/hoge/large_dataset.csv')
train_ddf2 = dd.from_pandas(train_df,2)
基本的にはpandasと同じです。
ちなみにpandasデータフレームからdaskデータフレームに変換することもでき、from_pandasメソッドを用います。引数でいくつにデータを分割するのか指定することができます。
集計もpandasと同様に行うことができますが、.compute()を終わりに着けるのが特徴です。describe()メソッドを使って、通常のpandasと実行時間がどう変わるのか見てみましょう。今回はjupyter notebook のマジックコマンド%%timeを用いて実行時間を計測します。


同じ処理ですが、Pandasでは17.2秒、Daskは5.41秒でした。Daskの方が3倍以上速く計算することができました。今回のような巨大なデータであればあるほど、差が開いてくるのかもしれません。事前にiris等小さなデータで試した際はpandasの方がはるかに速かったので、扱うデータによって使い分けることを推奨します。
Daskのデメリット
ここまで、Daskのよさについてご説明しましたが、以下のような点に注意が必要です。自分の扱うデータセットと相性が良いか、よく確かめてみる必要がありそうです。
日本語のドキュメントが少ない
爆速Python等の書籍で紹介があるものの、まだまだ機能の詳細についてはドキュメント数が乏しいです。英語の公式ドキュメントから逃げずに向き合うことが必要になってきます。
小規模データは普通にpandasの方が速い場合がある
あくまでもpandas APIを利用したもののため、立ち上がりに時間がかかってしまっている場合もあるようです。
まとめ
今回は並列処理に関して簡単な概要と具体的な実装についてご紹介しました。巨大なデータを処理する際にはぜひ並列処理を駆使してみてください。スケジューラやタスクグラフの作成機能など、まだまだ沢山の機能がありますので、またの機会にご紹介できればと思います。
データ分析に興味のある方募集中!
コグラフ株式会社データアナリティクス事業部ではPythonやSQLの研修を行った後、実務に着手します。
研修内容の充実はもちろん、経験者に相談できる環境が備わっています。
このようにコグラフの研修には、実務を想定し着実にスキルアップを目指す環境があります。
興味がある方は、下記リンクよりお問い合わせください。

X(Twitter)もやってます!
コグラフデータ事業部ではX(Twitter)でも情報を発信しています。
データ分析に興味がある、データアナリストになりたい人など、ぜひフォローお願いします!
📢Wantedly新掲載!
— アラリコ@コグラフ株式会社 | データ事業部 (@CographData) July 14, 2023
「データに興味がある」
「データに携わる仕事がしたい」
そこのあなた!
私たちと一緒にデータ分析しませんか?
IT業界未経験の方も大歓迎です☺️#エンジニア転職 #データ分析 #駆け出しエンジニアと繋がりたいhttps://t.co/S9o7VSjGRt