webスクレイピングを知識0から始めて習得するま⑦【Scrapyでの複数ページへの対処】

2022/1/30【7日目】
最初のページからのデータの取得方法検討
1ページだけのサイトではなく、複雑な構造のサイトへの対処を学んでいきます。
https://www.yodobashi.com/category/19531/11970/34646/

ヨドバシ.comのサイトから、人気順で並んでいる商品の情報を取得していきます。
データ取得方法の検討・確認

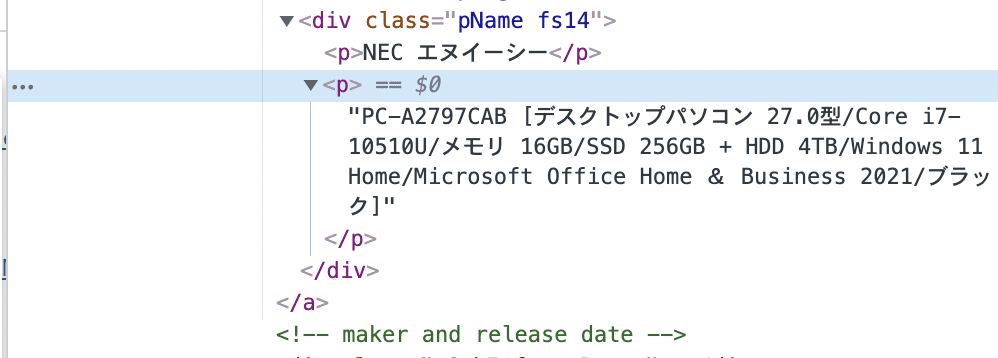
調べたい消費を右クリックし検証を押す。するとhtmlコードを確認できる。商品名はp要素に含まれている。メーカー名は同じ階層で上に含まれるp要素に含まれている。

価格についても右クリック検証で確認できる。
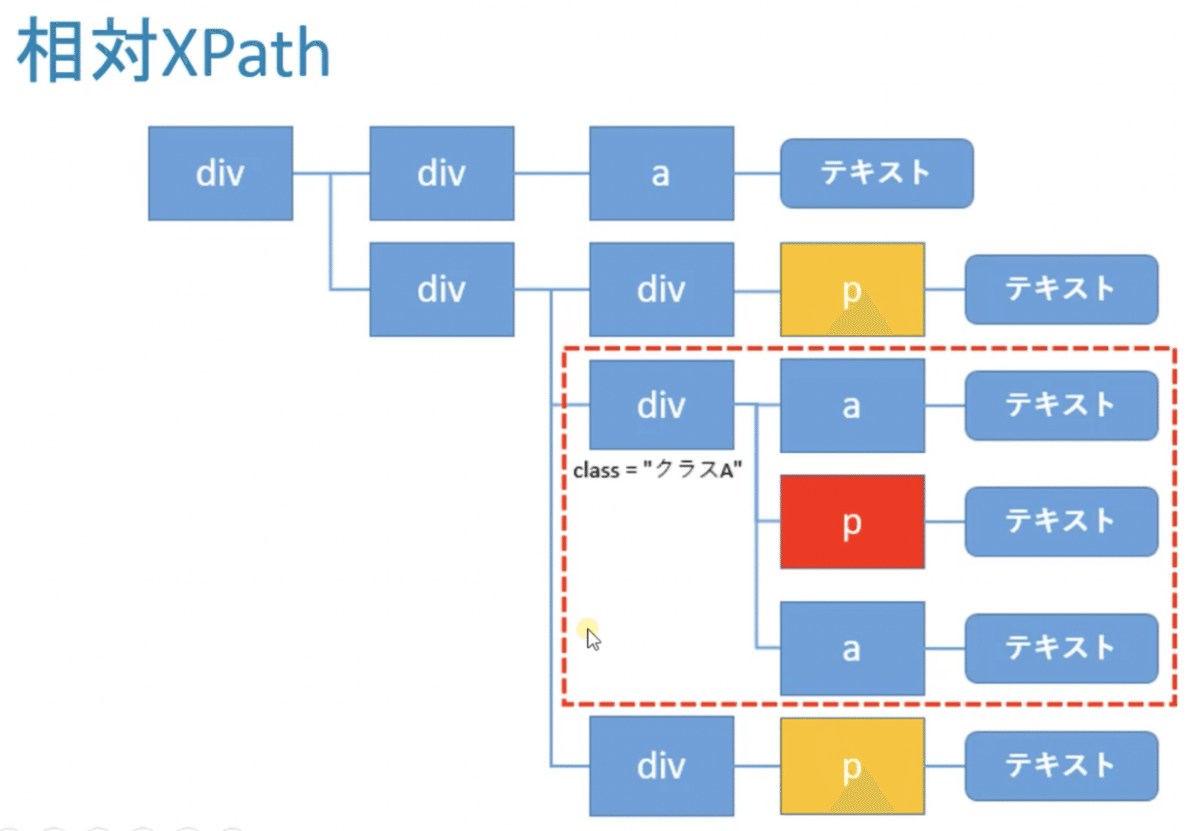
単純にp要素を指定すると黄色いp要素も抽出されてしまう。一旦、その上の階層のdiv要素をclass属性の値を元に指定し抽出する。すると赤枠のhtmlが抽出される。Scrapyではここからさらにxpathで絞り込んでいける。ここでは、メーカー名、商品名、価格を取得していく。
![]()
command+Fで検索欄を表示。

//div[contains(@class,"productListTile")]とある属性値を含むという曖昧検索には、contains(属性,属性値)を使う。@はclass属性を表す。これでヒット数が48件になる。↓ボタンを押していくと商品情報を含むdiv要素にヒットしていることがわかる。1ページあたりの表示件数と一致している。

メーカー名と商品名は、div要素の配下のp要素のテキストから取得できる。
//div[contains(@class,"pName")]/p/text()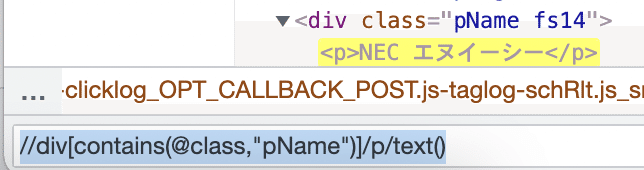
これで、メーカー名を取得できる。
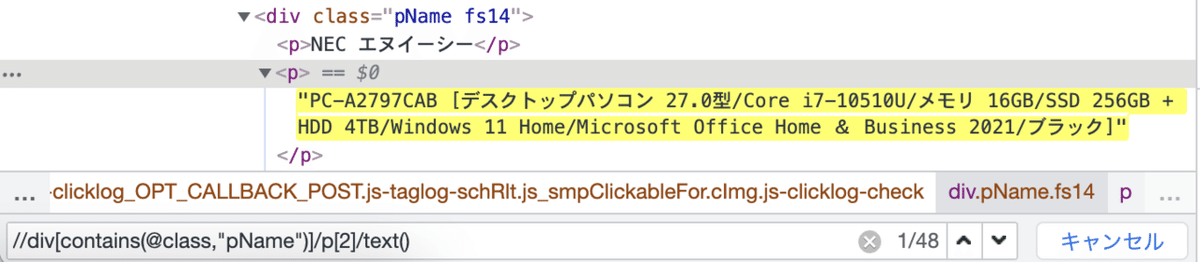
//div[contains(@class,"pName")]/p[2]/text()商品名は2つ目のq要素なので、[2]と指定する。
価格は、class属性の値に、productPriceの値を持つspan要素の配下のテキストから取得できる。
![]()
値をダブルクリックすると選択できるようになる。コピーできる。
//span[@class="procuctPrice"]/text()
これで価格が取得できる。
プロジェクトの作成からsettings.pyの編集(HTTPキャッシュ)
アナコンダナビゲーターから、作成した仮想環境でターミナルを開く。
projects ディレクトリに移動。
scrapy startproject yodobashi


プロジェクトに必要なディレクトリ、ファイルが自動で作成される。yodobashiディレクトリの中にもう1つyodobashiディレクトリができるけどそれで問題ない。
scrapy genspider desktop www.yodobashi.com/category/19531/11970/34646最後の/とhttps://を削除する。


spidersディレクトリの下にファイルが作成される。

アナコンダナビゲーターから仮想環境を選んでVS Codeを起動する。
projects配下1つ目のyodobashiディレクトリを選択して、開くをクリック。

よくわからないワーニングが出るけどtrustで大丈夫。
まずは、settings.pyを編集する。パラメーターでScrapyのさまざまなオプションを指定する。command+Bでエクスプローラーを閉じられる。
FEED_EXPORT_ENCODING='utf-8'
一番下の余白で、出力ファイルの文字コードを指定する。これを指定しないと文字化けする可能性あり。標準的なutf-8を指定。

download_delayのコメントアウトをcommand+/で解除。download_delayは1つのページをダウンロードしてから次のページをダウンロードするまでの間隔(秒)で指定する。

ロボットテキストがある場合はそれに従うかを指定するパラメータ。ロボットテキストでアクセスが禁止されているページにアクセスしないようにする。このままTrueでいい。

HTTPCACHE_ENABLEDコメントアウトを外す。複雑なwebサイトの場合、トライ&エラーが必要で都度ダウンロードしていると時間がかかる。ローカルのコンピュータにHttpキャッシュとして保存してくれる。2回目からはキャッシュからwebページを取得してくれるから早くなる。

HTTPCACHE_DIRで、キャッシュを保存するディレクトリを指定できる。
![]()
HTTPCACHE_EXPIRATION_SECSを指定すると、キャッシュの有効期限を指定できる。頻繁に更新されるページだと、古いキャッシュを使っていると情報が変わってきてしまうので、目的によって指定する。ここでは、1日=86,400(秒)を指定。
変更内容をcommand+sで保存する。
最初のページからのデータ取得のコーディング
続いて、desktop.pyのスパイダーを編集する。

スパイダーには3つの属性が定義されている。
![]()
allowed_domainsはスパイダーがアクセスできるドメイン。.com移行を削除してドメイン名だけにする。
![]()
start_urlsにはスパイダーがスクレイピングを開始するurlを設定する。初期設定ではhttp:になっているので、https:にする。

メソッドとして、parseメソッドが定義されている。
スクレイピーの一連の処理は、
①リクエスツがurlに送られる。
②webサイトからのレスポンスをparseメソッドでキャッチする。
③この中でxpathを用いて情報の抽出を行う。
従って、parseメソッドにはChromeの開発者ツールで確認したxpathのコードを入力していく。
products=response.xpath('//div[contains(@class,"productListTile")]')![]()
xpathで取得した値は、変数に格納する。ここではproducts。このdiv要素には、メーカー、商品名、価格が格納されている要素が含まれている。
yield{
'products':products
}
戻り値は、yieldで辞書で出力していく。キーをproducts、値を変数productsとする。
このファイルを上書き保存する。このスパイダーを実行していく。
メニューバーからターミナルを開く。


スパイダーの実行には、scrapy.cfgファイルと同じレベルにいる必要がある。lsで確認できる。
scrapy crawl desktop
出力結果を確認すると、キーproductsの値として、selectorオブジェクトリストの形で取得できている。selectorオブジェクトには取得した情報が格納されている。htmlの特定の部分を選択(select)するためセレクターオブジェクトと言われている。データは省略されて表示されているが、div要素とその配下の情報が格納されている。この中から、メーカー、商品名、価格を取得していく。
for product in products:
maker=product.xpath('.//div[contains(@class,"pName")]/p/text()').get()
name=product.xpath('.//div[contains(@class,"pName")]/p[2]/text()').get()
price=product.xpath('.//span[@class="productPrice"]/text()').get()
for文でproductsから商品ごとの情報を取り出していく。
productにはSelectorオブジェクトが格納されている。Selectorオブジェクトに対してxpathを記述する場合。最初に. をつける必要がある。

赤枠がSelectorオブジェクトに格納されている。そこから絞り込むときには. をつける必要がある。レスポンスに対してxpathを記述する場合は不要だけど、Selectorオブジェクトに対して記述する場合は先頭に. が必要になる。
テキストで出力するので、xpathメソッドの最後に.get()をつけてテキストで取得するようにする。
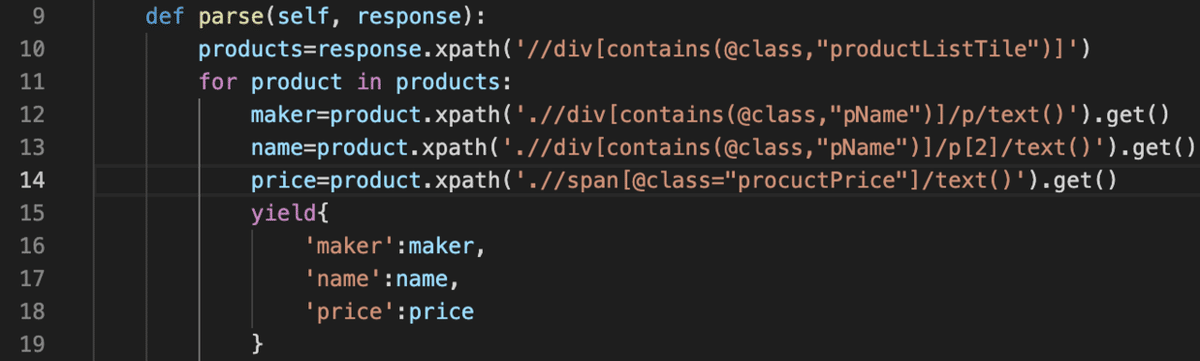
yieldもfor文内に含めるためインデントを下げる。
clear一旦、ターミナルをクリアする。
scrapy crawl desktop再度、スパイダーを実行。

これでデスクトップパソコンの情報が取得できた。1ページ目だけの情報が取得できるようになった。
次のページ以降からのデータの取得方法検討
「次へ」を右クリックし、検証をクリック。

クラス属性の値にnextの値を持つa要素に次のページへのリンクが格納されている。リンクはhref属性の値として格納されている。
//a[@class="next"]/@href
これで次のページへのリンクが抽出ができる。
次のページ以降からのデータ取得のコーディング

格納されているURLにはドメイン名が含まれていない。このような形式を相対URLという。
絶対URLのページに相対URLを記述すると、一番下のようなURLに変換される。

next_page=response.xpath('//a[@class="next"]/@href').get()
if next_page:
yield response.follow(url=next_page, callback=self.parse)
次へのボタンが存在し次へのリンクが取得できる場合のみ、次のページに遷移する。URLはテキストで取得するので、.get()をつける。
最後のページでは次へのボタンが存在しないので、変数next_pageはnullになり、処理を実行しない。callbackメソッドには、このparseメソッドと同じ内容を実行するので、self.parseを入れる。つまり、最初のページで商品の情報を取得し、次のページを辿って、また次のページで商品の情報を取得し、次のページを辿ってという作業を、最後のページまで続ける。
import logging
pythonでログを出力するためのモジュール。

商品を取得するコードはコメントアウトしておく。
logging.info(response.url)

情報レベルのログとしてinfoがある。引数は出力内容を渡す。
scrapy crawl desktop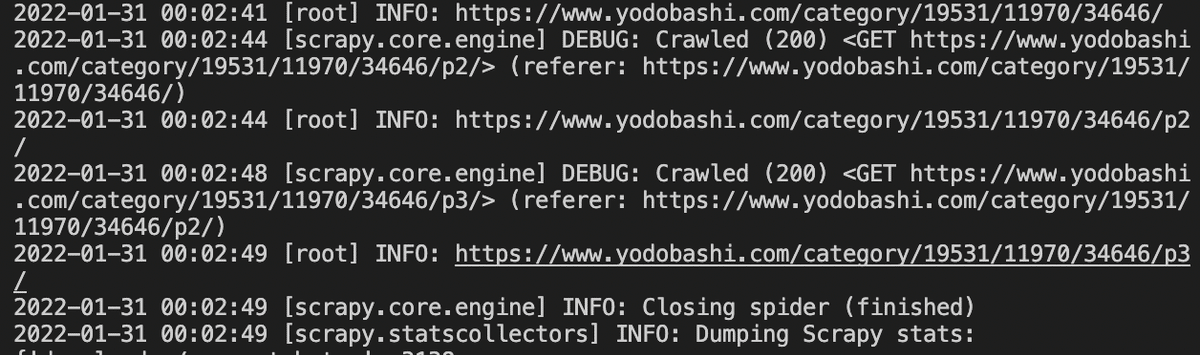
ファイルを実行すると、infoレベルのログとして1ページ目、2ページ目、3ページ目のURLが表示されている。

実際に3ページ目が最後のページになっている。
next_page=response.xpath('//a[@class="next"]')
if next_page:
yield response.follow(url=next_page[0], callback=self.parse)
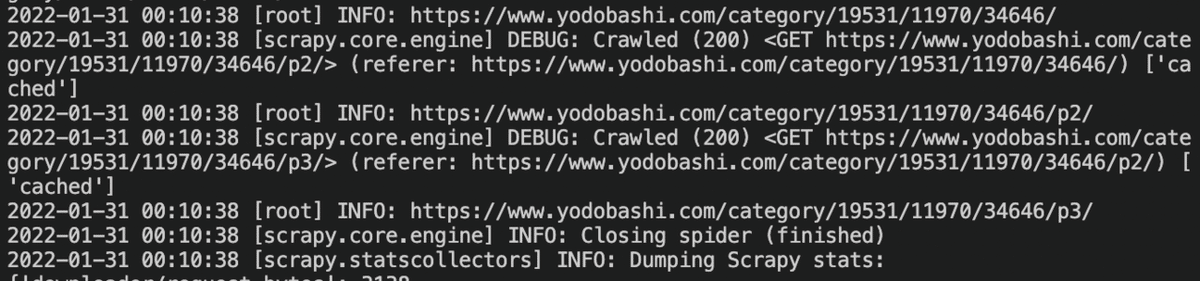
response.follow引数には、a要素のセレクタを渡してもOK。自動的にhref属性からURLを抽出してくれる。同様に取得できた。
import scrapy
import logging
class DesktopSpider(scrapy.Spider):
name = 'desktop'
allowed_domains = ['www.yodobashi.com']
start_urls = ['https://www.yodobashi.com/category/19531/11970/34646/']
def parse(self, response):
logging.info(response.url)
products=response.xpath('//div[contains(@class,"productListTile")]')
for product in products:
maker=product.xpath('.//div[contains(@class,"pName")]/p/text()').get()
name=product.xpath('.//div[contains(@class,"pName")]/p[2]/text()').get()
price=product.xpath('.//span[@class="productPrice"]/text()').get()
yield{
'maker':maker,
'name':name,
'price':price
}
next_page=response.xpath('//a[@class="next"]')
if next_page:
yield response.follow(url=next_page[0], callback=self.parse)商品情報のコメントアウトを外して実行してみる。
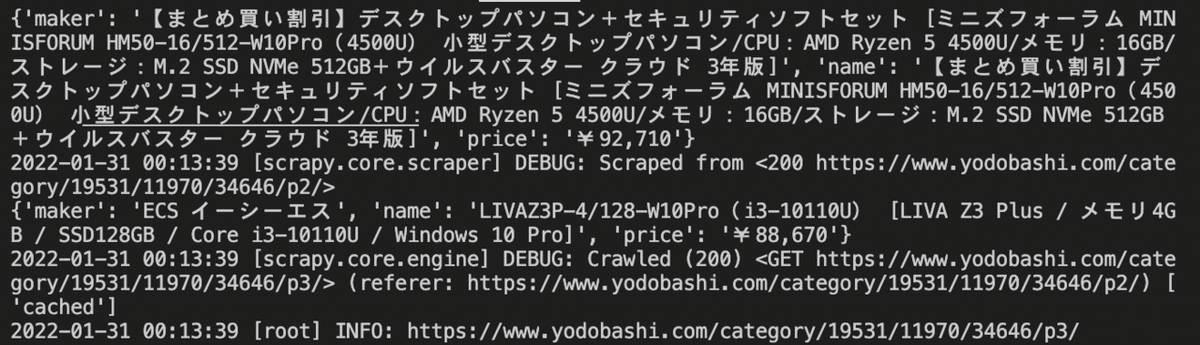
このように、2ページ目、3ページ目の商品情報も取得することができた。これでは画面に表示されただけで使えないので、次からはcsvやjsonで出力する方法を学習する。
CSV、JSON、XMLファイルの出力
ここでは、JSONファイルへの出力を学ぶ。
scrapy crawl desktop -o data.json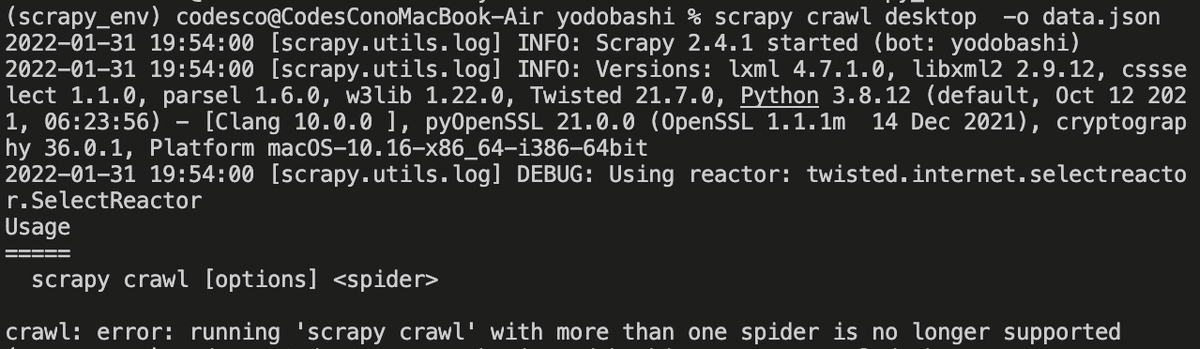
このエラーが出た時はスペースが全角だったりするので確認してね。

data.jasonが作成された。
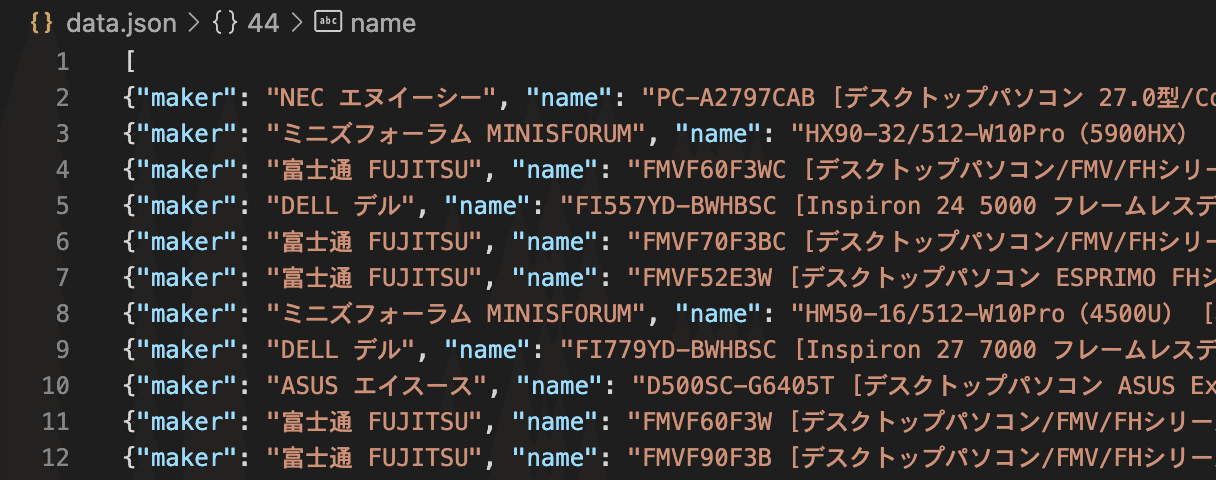

ダブルクリックで開くと見づらいので、shift+option+Fで表示形式を変えられる。
scrapy crawl desktop -o data.json拡張子を変えるだけでcsvファイルでの書き出しもできる。
scrapy crawl desktop -o %(name)s_%(time)s.json
このままだとエラーが出るので、
setopt nonomatch先にこれを実行する。なんか、ワイルドカードが原因みたい。
![]()
その後に、実行したところちゃんとファイル名を指定してJSONファイルを出力できた。
UserAgentの変更
開発者ツールのネットワーク→すべてをクリックしてcommand+Rでリフレッシュする。
URLに含まれる文字列が含まれる名前をクリックするとヘッダーに文字が表示される。

中ごろにリクエストヘッダーがある。

一番下にUser-Agentがある。webサイトでは、コンピュータからのアクセス化人間からのアクセスかをUser-Agentを確認して判別している。コンピュータと判別されるとアクセスをブロックされることもある。スクレイピーではUser-Agentを変更できる。

parseメソッドの中身をコメントアウトする。
logging.info(response.request.headers['User-Agent'])
![]()
User-Agentを確認すると、scrapyという文字が含まれていて、ブラウザの開発者ツールで確認したものとは違う。これだとアクセスがブロックされてしまう可能性がある。

settings.pyのUSER_AGENTのコメントアウトを解除する。
![]()
開発者ツールで確認したUser-Agentの値を貼り付ける。
![]()
改めて実行すると、書きかわってる。
「Codes&Co.」「コーズコー」