
noteの検索をCloudSearch からElasticsearchに移行しつつある話

記事の概要を3行でまとめ
検索システムの移行や導入は組織化しましょう
指標に気を取られすぎないようにしましょう
検索を見ると様々なドメインに触れるので知識が増えてお得
はじめに
note株式会社で検索エンジニアをしているchovです。
早速ですが、noteでは全文検索エンジンを以下の箇所で利用しています。
ハッシュタグの検索
ユーザの検索
マガジンの検索
記事の検索
メンバーシップの検索
これまではCloudSearchを利用していましたが、2022年の4月ごろからElasticsearchへの移行プロジェクトを始め、この記事が公開される2023年2月時点でほとんどの検索をElasticsearchに移行するところまで進みました。
本稿では移行プロジェクトの進め方や検証の手法について解説しますが、これから全文検索エンジンの導入・移行を行う方の参考になれば幸いです。
こんな人向け
データ量が多くなり、RDBでのフィルタリングではパフォーマンスに限界を感じてきたフェーズのサービスを開発している人
技術選定のポイントがわかる
SolrやOpenSearchとの比較
なぜElasticsearchを選んだのか
移行時に苦労しやすい場所がわかる
データ量が多い場合の注意点
リアルタイム更新で起きた問題点
検索機能を担当しているが、社内に検索エンジン有識者が少ないため技術選定に迷っているエンジニア
更新アーキテクチャの事例がわかる
過去のアーキテクチャの問題点
耐障害性を向上させる構成例
コンテナで負荷試験を行う方法がわかる
解説しないこと
具体的なmapping設定をはじめとしたElasticsearch設定の詳細
検索ロジックの詳細
移行前の課題
これまでnoteには検索エンジンの専任担当者がおらず、有志による改善が散発的に行われており、大まかに以下の課題がありました。
CloudSearchはデータのインデクシングにも課金されるため、抜本的なロジックを改善するためのデータ更新がしにくい
CloudSearchでは細かいアナライザーの設定ができず、半角/全角の同一視のような機能も提供できない状態だった
Elasticsearch移行の目的はこの問題を解決することです。また、全文検索の移行とは関係なく、特定の条件で記事を絞り込んだり、リストアップしたりする処理がRDBではまかなえない規模に拡大しているという問題もありました。
技術選定について
noteでCloudSearchを導入した頃、まだ私は入社していなかったため、CloudSearchの導入経緯について詳しくは知りません。しかし、仮にAmazon Elasticsearch Service(現OpenSearch)を導入していたとしても運用負荷はそれなりにあったと想定されます。AWSで手軽に全文検索を導入しつつ運用負荷を下げる選択肢として、CloudSearchの導入は必然と言えたでしょう。当時の私でも運用負荷を考えてそうしたと思います。
しかしデータ量が増えてきた現在、インデクシングにも課金されるCloudSearchを利用し続けることは却って高コストとなります。
そのため新しい全文検索エンジンを導入することとなりましたが、AWS上で動作させるとなると3つの選択肢があるかと思います。
Apache Solr
Amazon OpenSearch Service
Elasticsearch ← 採用
今回は要件を考慮した結果まずSolrを除外し、その後Elasticsearch と OpenSearch を天秤にかけた結果、Elasticsearchを自前のEKSクラスタ上で動作させる手法をとりました。
Solrを採用しなかった理由
筆者は2014年から2021年までSolr(1.4-8.7)を扱っており、Solrの良いところも悪いところも経験してきました。用途次第ではSolrが最良となる場合もありますが、今回は要件が合いませんでした。
noteの検索に要求される要件としては、
データ量が多いため、単一のノードで提供するのではなくクラスタを組めること
逐次更新のパフォーマンスが良いこと
形態素解析精度が重要となるため、Kuromoji-IPADIC以外の形態素解析器が利用可能なこと
が挙げられます。Solr Cloudは進歩してきているとはいえ、クラスタ化したときの運用難易度が高いことが知られています。そのため、今回は見送りました。仮にクラスタ化しなくても良く、データ更新がバッチ処理で問題ないのであればインデックスデータをクラウドストレージに配置したSolrのコンテナをデプロイするほうが手軽で良いでしょう。
OpenSearch vs. Elasticsearch
運用負荷を考えると、多少高額になってもマネージドサービスであるAmazon OpenSearch Serviceは魅力的です。しかし、2023年2月現在は日本語の形態素解析器の入れ替えができません。
検索に詳しい方でないと、形態素解析器の違いというのは想像しにくいかもしれません。そこで筆者が実際に遭遇した形態素解析が問題となる例を挙げましょう。たとえばユーザーがダムについて興味があるとします。

しかし、OpenSearch Serviceで利用できるKuromoji-IPADICによる形態素解析では「ダム」で検索するとガンダムやキングダムといったダムに関係のないものまでヒットしてしまいます。Kuromoji-IPADICでは「ガンダム」「キングダム」が「ガン/ダム」「キング/ダム」と形態素解析されることが原因です。

noteというサービスの特性上、商標をはじめとした固有名詞の形態素解析にはある程度強くあって欲しいのですが、この例からも分かるとおりKuromoji-IPADICしか使えないことはかなりのマイナスです。
この点を解決するには固有名詞を豊富に取り込んだKuromoji-IPADIC-NEologdなり、Sudachiを使うのが良い選択肢となりますが、どちらを利用する場合もユーザープラグインを利用できることが必須となります。
Elastic Cloudも上位プランならユーザープラグインを導入可能ですが、コスト的に厳しいことからnoteではEKS上でElasticsearchを自前運用することになりました。(2023-02-10 指摘を受け修正。マネージドのElastic CloudとElastic Cloud on Kubernetesは別物でした)
(2023-02-10追記)そのため、予めelasticsearch-sudachiをインストールしたカスタムコンテナをElastic Cloud on Kubernetes(Basic)でEKS上にデプロイしています。(追記ここまで)
繰り返しになりますが、形態素解析器にこだわらなくて良いのであればOpenSearch ServiceやElastic Cloud(の下位プラン)マネージドのElastic Cloudを利用したほうが楽です。
ECK上でのElasticsearch運用例はけっこう珍しいかもしれませんが、まだ語れるほどに運用ノウハウが溜まっておりません。しかし、大きな障害も起きておらず、バージョンアップも簡単にできたため、イメージよりは大変ではなかったというのが実感です。
技術選定を通すための組織化
ちょうどnote社としてk8s導入を進めつつあるタイミングだったことや、構成検討の場で筆者が「困ったらkubectlを叩いて最低限の切り分けはできます」と主張したことも導入に至った理由ではあるでしょう。しかし、前提としてElasticsearch移行プロジェクトを組織化していたことが効きました。
以前からデータエンジニアをやりつつ全文検索エンジンの検証をしていたのですが、個人のサイドプロジェクトとしてできる領域はやはり限られていました。
そこで上長に話を通し、CTOまで話を持って行くことで全文検索を移行しつつ、ゆくゆくはリストアップや絞り込みも改善するという目標のもとに組織化(※専任担当者は私1人、チームとして必要なときに力を借りる)することで他チームとの交渉が非常にしやすくなりました。大きな移行では腹をくくって組織化しましょう。
専任担当者が1人であっても、説明は大事です。むしろ、ドキュメントを作らないと誰にも自分の仕事を説明できなくなります。まず作るべきは構成図とスケジュールです。移行後のコストが見積もれそうなら大まかなコスト計算もしておくと良いでしょう。
もう一つやるべきこととして、更新システムの作り込みに時間を使う交渉があります。データ投入のしにくいシステムはサービスイン後の開発速度を大きく下げますし、安全にデータが投入できないと運用が大変です。少し時間を使ってでも安全な更新システムを作ることを推奨します。
更新アーキテクチャについて
noteではCloudSearchを以下の図のように更新していました。Railsのコールバックなどを利用してModelの更新をSidekiqにキューイングし、CloudSearchを直接更新しています。

このアーキテクチャもひとまず全文検索を用意する観点では良いのですが、耐障害性に課題があります。たとえばSidekiqに障害が発生した場合、更新メッセージが損失することにより、インデックスとDBの状態を合わせることが非常に難しくなります。
そのため、Elasticsearch化にあたっては耐障害性の向上を念頭に大きなリアーキテクチャを施しました。
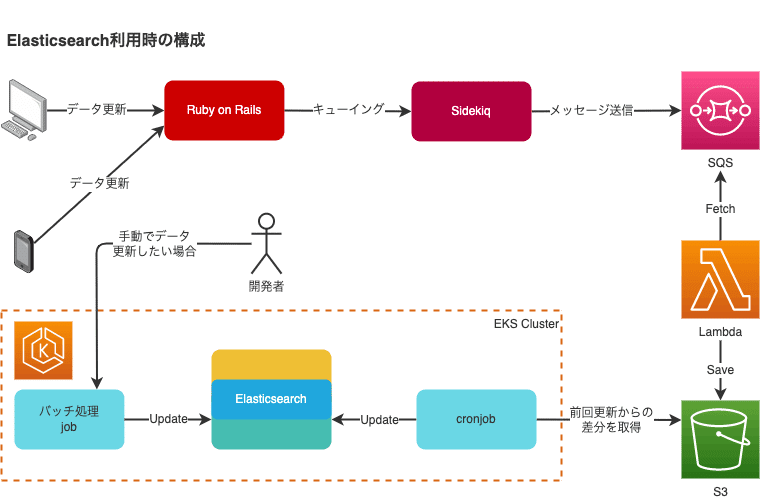
RailsからSidekiqを利用している部分は変わりませんが、SidekiqからSQSにメッセージを送信、LambdaがSQSから毎分まとまったメッセージを読み込んでS3に更新ログを蓄積、CronJobが定期的にBulk Updateを行う形式です。Lambdaより後ろのレイヤーは全てGoで実装しています。
また、Sidekiq障害などに伴って手動でインデックスを再構築する場合はクラスタ内にjobを作成し、そこからDB/Snowflakeを参照して更新を行います。
完全なニアリアルタイム更新は安全性の担保が難しいのである程度の遅延を許容してほしい、という交渉をした結果このアーキテクチャとなりました。
このアーキテクチャには以下のメリットがあります。
Elasticsearchの過負荷などで更新が意図せず停止してもログさえあれば最新のアプリケーションと同じ状態に復旧可能である
仮にSidekiqの障害などでログが欠損してもDBのスナップショット+復旧後の更新ログを利用することで安全にインデックスが再構築可能。仮に今後OpenSearchや他のプラットフォームに移行する場合でも移植しやすい
検索ロジックをRailsから引き剥がすことでRailsの責務が減る
また、更新ログはProtocol Buffersで定義しているため、Rails上で単体テストを書いておけば仕様通りの更新メッセージが送られていることを担保できます。go.modとGemfileを同じ階層に置いてmakeすればGoのライブラリとしてもGemとしても読み込めるので、1つのデータ定義を多数の言語で共用できるのも魅力です。
# ドキュメント, Go, Gem を一気にMakefileで生成する例
PHONY: build
build:
bundle lock
protoc --doc_out=./doc --doc_opt=markdown,README.md \
--go_out=. --go_opt=paths=source_relative \
--ruby_out lib/my_elastic_messages/ \
my_elastic_message.proto移行は小さく・すばやく試す
noteの掲げるバリューには「すばやく試そう」というものがあります。
システム移行は規模の小さいサブシステムから進めていくのが定跡です。根幹となる更新システムは一度運用を開始すると手を入れにくくなることが予想されるためじっくり作り込みましたが、アプリケーションレイヤーは小さいインデックスから素早く進めていきました。
冒頭で述べましたが、noteでCloudSearchを利用していたのは
ハッシュタグの検索
ユーザの検索
マガジンの検索
記事の検索
メンバーシップ検索の検索
の5つです。移行プロジェクトでは最初にハッシュタグの検索に手をつけました。

ハッシュタグ自体のデータ量は少ない一方、記事の投稿に応じて件数が頻繁に変化します。APIレイヤーは簡単でありつつ更新システムには負荷がかかるため、良いベンチマークになりました。実際、更新システムの粗がここで洗い出されたことで更新システムは大きな障害もなく動き続けています。
移行プロジェクトの進め方は基本的にはどこも似ているでしょうが、大まかには
旧システムが動いている箇所を洗い出し
ほぼ同じ動作をする新システムを作成
動作試験、負荷試験
カナリーリリース
検索指標の評価
完全にリリース
旧システムを削除
という流れになるかと思います。本稿では負荷試験と評価について特に述べようと思います。
負荷試験もコンテナで
負荷試験には様々なツールがありますが、私は k6 をよく利用しています。
k6の特徴としてはJavascriptでシナリオが書けることがよく挙げられますが、コンテナとの相性が良いことも見逃せません。ElasticsearchがEKS上で動作しているため、jobを作成して負荷試験を実施することでコンテナ上で負荷試験を完結できました。
私は利用していませんがk8sのextensionもあるようなので、こちらを使っても快適な負荷試験ができるかと思います。
指標に気を取られすぎない
カナリーリリースを行ったら検索指標の評価を行うことになるかと思いますが、ここを詰めすぎるといつまで経っても移行ができず検索チューニングの沼に入ります。
また、検索移行あるあるとして「以前ヒットしていたものが出ない」ことで修正に時間をとられることがあります。もちろんそういった指摘のなかにはクリティカルな問題もありますが、全体には大きな影響がないものも存在します。
そのため、移行の前段階でRedashのダッシュボードを作成し、基本的な指標が大きく悪化していなければ移行可能、という判断基準で進めました。検索以外にも言えるかと思いますが、「どうすれば移行できるか」という明確な基準を設けることでアドホックな対応を減らせます。

大変だったところ・つまずき
これまで移行プロジェクトの進め方に多くを割いて記載しましたが、ハッシュタグやユーザーの情報はすぐにインデクシングできた一方で記事のインデクシングは非常に大変でした。
記事のデータ量が多く、検証のイテレーションが長くなりがち
noteでは1000万件を超える記事が投稿されているため、純粋にインデックスのサイズが大きくなります。詳細は伏せますがインデックスサイズは100GBを超えます。このサイズになると全件更新に長い時間がかかるのはもちろん、メタデータを一つ追加するにも長い時間が必要となります。検証環境である程度仕様を固めることで手戻りはある程度抑止できますが、パフォーマンスについては本番のサイズでやってみると大きく悪化する……というようなこともあり、抜本的な解決策が見いだせていません。良いアイデアを募集中です。
記事投稿の仕様が複雑で、更新システムの実装に時間がかかった
noteはテキスト、画像、つぶやき、音声、動画の5種類のコンテンツを投稿できますが、それぞれ微妙にデータ構造が異なっています。
投稿されたコンテンツは複雑に状態遷移をすることから、検索に必要な粒度で更新ログを送信する部分の実装には非常に時間がかかりました。
以前の実装を持ってくれば良いのではないかと思う方もいらっしゃるかと思います。というより私がそう思っていました。しかし現状には困ったら手運用でカバーするような箇所が多々あり、その部分を自動化できるようにしていたら時間がかかってしまいました。手運用で何とかすることにして実装を早く終わらせる/実装にコストをかけてでも自動化する判断は永遠の課題です。

ハッシュタグ件数のリアルタイムな更新をやろうとしたらSidekiqにキューが積まれすぎ、アラートがたびたび発生した
これは単なる失敗談なのですが、ハッシュタグの件数をリアルタイムに更新しようとすると「更新された記事数×記事についているハッシュタグ数」の更新メッセージが飛びます。
そのため、予約投稿などを起因にして一時的に大量のメッセージが送信されたことでSidekiqが詰まりました。
最終的にハッシュタグ件数のリアルタイムな更新は諦め、件数についてはバッチ処理で更新することにしました。柔軟に対応できる更新システムを作っていたことでこの変更は1日で完了しましたが、頑強なシステムを構築するのはやはり難しいと改めて感じました。
学び・反省
データ量が多いのはどうしようもないが経験値は得られる
大量のデータを素早く処理する工夫は様々にありますが、最終的には課金でしか解決できない部分も多くあります。かけられるコストは交渉しつつ、コストに見合わない時は諦めて処理が終わるまで待つしかありません。
100万件のオーダーでは味わえない辛さが1000万件のオーダーのデータにはあります。リソースを一つ解放し忘れるだけでメモリが足りなくなるのは当たり前で、そこそこ考えて処理を考えないとすぐに何かが過剰になって処理が通らなくなります。1億件は体験したことがないので想像もつきません。とはいえ、いつかは1億件の記事と向き合う時期が来るので、その時が来たらまた記事を書ければ良いなと思っています。
仕様が複雑なドメインはしっかり学習して今後に生かせそう
記事投稿をはじめとして、noteの実装についてかなり学びました。検索を見ることはデータ更新を見ることとほぼ同義です。大量のデータを扱う力もつきますし、ドメイン知識もつきます。これまで担当してこなかった範囲の知識がつくことで今後の業務にも生かせそうです。お得ですね。
また、今回は既存の検索/更新ロジックで直すべき点がいくつかあり、早めに直すべきところを直したことでRailsそのものや既存の検索ロジックについても詳しくなりました。深いところをやらないと知識は深まらないものだな、と改めて実感しました。
おわりに
頑張って移行しても、検索システムは使ってもらわなければなりません。移行と並行して検索に関する社内のニーズをSlackから拾っているのですが、各人の業務に応じてやりたいことは大きく変わります。協力できそうなところには素早くアクションし、攻めの姿勢で改善に取り組むことが大事だと思っています。
もちろん要求をそのまま実装するのではなく、その人が本当に求めていることは何だろうか、要求を抽象化した結果、検索システムにこの機能を追加したら良いのではないか——そういったことを考えるようになります。
移行が終わったらあれもやりたい、これもやりたい、と思っていますが、まずは目の前の移行を頑張ろうと思います。
この記事が気に入ったらサポートをしてみませんか?