
【ChatGPT】ノーコードで機械学習にチャレンジしてみよう!(サポートベクターマシン編)

ChatGPT部でChatGPTヘビーユーザーのこーたろーです。
前回に引き続き、ノーコードでの機械学習チャレンジを行なっていきます。
前回は、機械学習の基礎学習で用いられるアヤメのデータセットを用いて、ロジスティック回帰を行いました。
今回は、同じデータセットを使って、サポートベクターマシン(SVM)での分類を実行していきます。
本編に移る前に、私のやっているAI関連情報発信用アカウントの宣伝をしておきます。是非、フォローをお願いします。
【Twitter情報収集アカウント:https://twitter.com/DsfKotaro 】
それでは、本編をご覧ください。
はじめに
ChatGPTのAdvanced Data Analysis(ADA)を今回も活用していきます。こちらの機能は、ChatGPTが自身の持つ環境内で、LLMで作成したコードを用いて出力を実施し、実行した出力を元に回答を返してくれます。
データ分析の基礎知識があれば、自身の手を動かす手間を最小限にしてくれるというとても有用な昨日になっています。
1. データセットの準備
1.1 アヤメのデータセット
今回も、前回同様にあやめのデータセットを使用していきます。
今回はこのデータセットを用いてADAを実行していきます。
1.2 データの内容を確認
アヤメのデータセットをアップロードし、データの中身を確認していきます。



基礎統計量までを一気に出力してくれました。
1.3 探索的データ分析
前回、探索的データ分析を行なっているため、今回は割愛いたします。
2. 機械学習
2.1 モデルの決定
今回は、SVMを用いる前提で行なっていますので、モデル選定は前回の記事を参考にしていただければ幸いです。
2.2 サポートベクターマシン
サポートベクターマシンの原理についてもChatGPTで確認しましょう!特に特徴や得意・不得意などを要チェックです。

基本的な仕組み
SVM(サポートベクターマシン)は、データを分類するための強力な機械学習モデルの一つです。このモデルの主な目的は、データセットを最適な境界線(または超平面)で分割することにより、異なるクラスを可能な限り正確に分類することです。
SVMの主要な特徴
マージンの最大化:
SVMは、クラス間のマージン(クラスの境界線から最も近いデータポイントまでの距離)を最大化する超平面を見つけます。これにより、未知のデータに対する予測の一般化が向上します。
カーネルトリック:
非線形分類問題に対応するために、カーネル関数を用いて元の特徴空間をより高次元の空間に変換します。これにより、元の空間では線形分離不可能だったデータを、新しい空間では線形分離可能にします。
サポートベクター:
サポートベクターは、クラスの境界を定義するのに直接関連する重要なデータポイントです。これらのポイントは、超平面の位置と向きを決定するのに使われます。
用途
二項分類や多クラス分類など、さまざまなタイプの分類問題に適用可能です。
テキスト分類、画像認識、生物情報学など、多岐にわたる分野で利用されています。
2.3 機械学習の実行結果
早速、SVMを実行していきます。

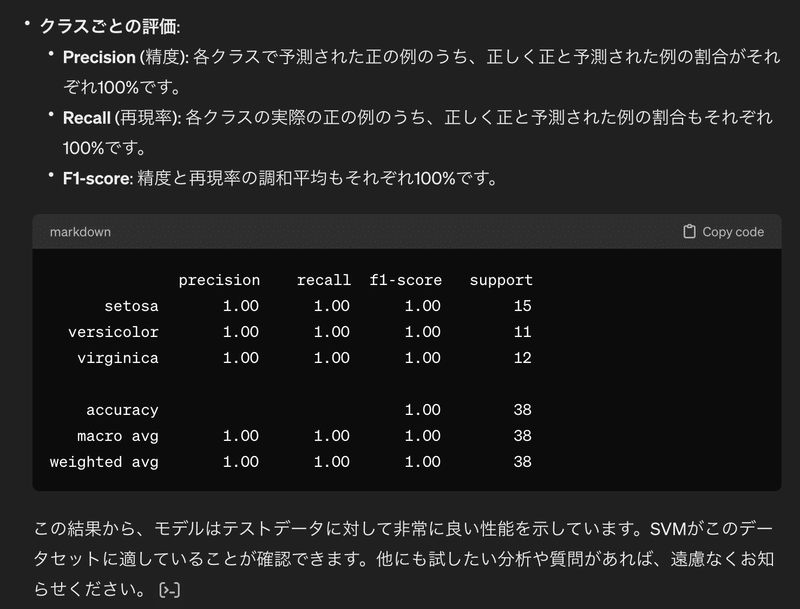
結果から、学習用データでSVMのモデルを学習させて、テストデータを分類した結果、100%分類できたことがわかります。
折角ですので、可視化をしてみましょう。


境界面もプロットしてもらいました。線形カーネルを今回は使って分類したようですので、線形の領域になっています。

まとめ
SVMについても、プロンプトのみでモデルを構成することができました。まだまだノーコードの機械学習は続きます。
この記事が気に入ったらサポートをしてみませんか?