
【ChatGPT】ノーコードで機械学習にチャレンジしてみよう!(ロジスティック回帰編)

ChatGPT部でChatGPTヘビーユーザーのこーたろーです。
久々にChatGPT部に投稿します。
現在、最近ではChatGPTの機能拡大なども進んでおり、目覚ましい速さでAIの利用シーンが増えてきているのを実感します。
その中でも、まだまだ開拓の余地があるのがデータ分析分野だと思います。
ベースとして動かすプログラムをPythonとしても、基本的にはAIに指示するだけで、ある程度の作業ができるようになってきました。
また、データのアップロードもできるため、データをそのままAIに処理してもらうという手段がとても魅力的です。
今回は、そんなデータ分析にChatGPTの機能である、Advanced data analysisを用いて機械学習にチャレンジしてみました。
本編に移る前に、私のやっているAI関連情報発信用アカウントの宣伝をしておきます。是非、フォローをお願いします。
【Twitter情報収集アカウント:https://twitter.com/DsfKotaro 】
それでは、本編をご覧ください。
はじめに
みなさん、ChatGPTのAdvanced Data Analysisを利用されていますでしょうか?
ChatGPTのコーディング技術が高いのは皆さんご承知かもしれませんが、単なるプログラミングのために使うという方法もありますが、データを読み込んで、そこから必要な情報を取り出して使うこともできるのです。
それがAdvanced Data Analysis(ADA)です。
今回は、ADAを使って、機械学習をやってみたいと思います。
1. データセットの準備
1.1 アヤメのデータセット
機械学習の練習問題としてしばしば出てくるこのアヤメのデータセットですが、機械学習のためのデータセットが公開されているICU(https://archive.ics.uci.edu/)などでも広く公開されています。
PythonのライブラリであるSeabornやScikit-Learnなどにも標準で入っていたりします。
今回はこのデータセットを用いてADAを実行していきます。
こちらに、使用したデータセットをアップロードしておきます。
1.2 データの内容を確認
アヤメのデータセットをアップロードします。

すると、アップロードしたデータから、どのようなデータが格納されているかが表示されます。
1.3 探索的データ分析
機械学習は、いきなり実施するものではありません。基礎集計を実施し、必要な特徴量を確認する作業が必要です。そのためにも、基礎集計含めたEDA(探索的データ分析)が必要となってきます。
まずは、基礎集計を行っていきます。

続きは、以下の通りです。
【各特徴量の基本統計量】
がくの長さ(sepal length (cm))
平均: 5.84 cm
標準偏差: 0.83 cm
最小値: 4.3 cm
第1四分位数: 5.1 cm
中央値: 5.8 cm
第3四分位数: 6.4 cm
最大値: 7.9 cm
がくの幅(sepal width (cm))
平均: 3.06 cm
標準偏差: 0.44 cm
最小値: 2.0 cm
第1四分位数: 2.8 cm
中央値: 3.0 cm
第3四分位数: 3.3 cm
最大値: 4.4 cm
花びらの長さ(petal length (cm))
平均: 3.76 cm
標準偏差: 1.77 cm
最小値: 1.0 cm
第1四分位数: 1.6 cm
中央値: 4.35 cm
第3四分位数: 5.1 cm
最大値: 6.9 cm
花びらの幅(petal width (cm))
平均: 1.20 cm
標準偏差: 0.76 cm
最小値: 0.1 cm
第1四分位数: 0.3 cm
中央値: 1.3 cm
第3四分位数: 1.8 cm
最大値: 2.5 cm
【種類ごとのデータ件数】
setosa: 50件
versicolor: 50件
virginica: 50件
基礎統計量が出てきました。
次は、相関関係を見ていきましょう。

たまにエラーも吐き出しますが、ADAで可能な形で再検証し、可視化を行ってくれます。

層別化したグラフも書いてもらいました。

setosaは、versicolorやvirginicaに比べて、特徴が明らかなのに対して、versicolorやvirginicaは少し似た特徴があるようです。
しかし、分離する箇所はある程度決まっているようです。
2. 機械学習
機械学習では、説明変数を使って、目的変数を予想するようなモデルを作成します。
以降に記載のフローで実施していきましょう。
2.1 モデルの決定
機械学習には様々なモデルが存在します。その中で、どのようなモデルが最適かをChatGPTとともに考えていきます。

以下、ChatGPTの回答です。
1. ロジスティック回帰 (Logistic Regression)
線形モデルの一つで、カテゴリ型の目的変数を予測するためによく使用されます。二値分類だけでなく、多クラス分類問題にも対応可能です。
2. サポートベクターマシン (SVM)
高次元空間での分類問題に強く、非線形の問題にもカーネルトリックを使用して対応できます。パラメータの調整が重要ですが、適切に調整されたSVMは非常に強力な分類器になります。
3. 決定木 (Decision Trees)
データから決定ルールを学習し、木構造を構築して分類を行います。解釈しやすいモデルですが、過学習に注意する必要があります。
4. ランダムフォレスト (Random Forest)
複数の決定木を組み合わせたアンサンブル学習の手法です。各木の予測を平均化することで、一般に決定木よりも過学習に強く、高い精度を達成できます。
5. 勾配ブースティングマシン (Gradient Boosting Machines, GBM)
弱学習器(例えば、浅い決定木)を順番に学習させ、前の学習器の予測残差を次の学習器が学習する方法です。ランダムフォレストと同じくアンサンブル学習の一種で、高い精度を達成可能ですが、パラメータ調整が重要です。
6. k近傍法 (k-Nearest Neighbors, k-NN)
予測したいデータ点に最も近いk個の訓練データ点を見て、その多数決により分類を行います。シンプルながら効果的な方法ですが、特徴空間の次元が大きい場合には性能が落ちることがあります(次元の呪い)。
これらのアルゴリズムの選択は、データの特性や目的によって異なります。実際には、複数のモデルを試し、交差検証などを行いながら、最も性能が良いモデルを選択するのが一般的です。もし特定のアルゴリズムでの実装を希望される場合は、お知らせください。
今回は、ロジスティック回帰を用いて分類問題を適用します。
2.2 ロジスティック回帰
ロジスティック回帰の原理についてもChatGPTで確認しましょう!特に特徴や得意・不得意などを要チェックです。

基本的な仕組み
ロジスティック回帰では、特徴量の線形組み合わせをシグモイド関数(またはロジスティック関数)に入力することで、出力値を0と1の間に制限します。シグモイド関数の式は以下の通りです。
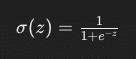
ここで、zは特徴量の線形組み合わせ(z=w0+w1x1+w2x2+⋯+wnxnz)、wiはモデルのパラメータ(重み)、xiは特徴量です。シグモイド関数の出力は、あるクラスに属する確率と解釈でき、この確率がある閾値(通常は0.5)以上ならば一方のクラス、以下ならばもう一方のクラスに分類します。
特徴
確率的な予測: ロジスティック回帰は、単にクラスを予測するだけでなく、その予測に対する確率を提供します。これにより、予測の不確実性を把握しやすくなります。
解釈性: モデルの各特徴量に対する重み(係数)を通じて、その特徴量が目的変数にどのように影響しているかを解釈できます。
正則化: 過学習を防ぐために、L1正則化やL2正則化を適用することができます。
用途
ロジスティック回帰は、メールがスパムかどうかを判定するスパムフィルタ、病気の有無を診断する医療診断、金融分野でのクレジットスコアリングなど、多岐にわたる分野で利用されています。
ロジスティック回帰はそのシンプルさから初学者にも理解しやすく、また強力な分類器として広く用いられています。
2.3 機械学習の実行結果
それでは、早速機械学習の実行を行っていきます。
機械学習では、目的変数(パラメータ)に加え、ハイパーパラメータ(学習時に必要となるパラメータ)が存在します。
そのため、ハイパーパラメータについては、都度、ChatGPTと相談しながら決めるのが良いと思われます。
それをプロンプトに含めて機械学習を含めていきます。

データの分割で、訓練データとテストデータに分割します。分割は70%と30%がよく用いられるということですが、今回は変更してみます。
また、アヤメの種類は3種類あり、訓練データとテストデータで、均等に3種類が存在するのが好ましいため、そのこともプロンプトで伝えてみましょう。


機械学習の結果、上記のようになりました。
全数正解したことになります。
せっかくなので、混合行列を表示してみましょう。

折角なので、散布図上にもプロットしてみます。


ちょっと見辛いですね。少し修正します。

すると、何度か微調整に失敗しますが、最後はしっかりと出力してくれます。

そして、最終的なグラフがこちらになります。

今回、訓練データとテストデータに分離したデータのうち、テストデータは、分離面の近くでなかったため、全数が正解となっていることがわかります。
まとめ
今回は、ChatGPTのADA機能を用いてノーコードで機械学習を実行してみました。
他のアルゴリズムについても、引き続き研究を行っていきたいと思います。
この記事が気に入ったらサポートをしてみませんか?