YOLOXによるVOTT用アノテーションの自動化

1. はじめに
近年、AI(Artificial Intelligence:人工知能)の急速な発展に伴い、それらを用いた技術が活用され始めています。例えば、AIによる画像認識技術として物体検出などがあります。物体検出は「画像の中から特定の物体の位置、種類、個数などの情報を認識する技術」であり、AIを用いて比較的高速に画像内の物体情報を取得することができます。この技術を用いて製造業では品質評価、外観検査、異常検知などに活用されています。
リアルタイムに物体検出を行うアルゴリズムにYOLO(You Only Look Onse)と呼ばれるものがあり、CNN(Convolutional Neural Network:畳み込みニューラルネットワーク)を用いたアルゴリズムとなっています。2021年8月に公開された最新の物体検出モデルにYOLOXがあり、これはYOLOv5を超える性能と、使いやすいライセンス(Apache License)を両立しています。
一般的にこのような物体検出の精度を向上させるためには、画像に対して学習させるための教師データ(正解データ、ラベル)を作成するアノテーションを行った後、学習済みモデルを用いて追加学習を行います。しかしながら、画像の枚数は数百枚必要になるケースが多く、画像一枚一枚に対してアノテーションを行うため、膨大な時間的・肉体的コストが必要となります。
そこで、時間的・肉体的コストを軽減するために、アノテーションを半自動化することを試みたので、本記事にその内容を記載します。
2. 実現後のイメージ
実現後のイメージを以下の動画で紹介します。以下の動画にもある通り、Pythonプログラムを実行することで自動的にバウンディングボックスが描画されるようになっていて自動的にアノテーションが実施できているのがわかります。ただし、すべてが良好なアノテーションとは限らないので微調整は手動で行う必要があります。
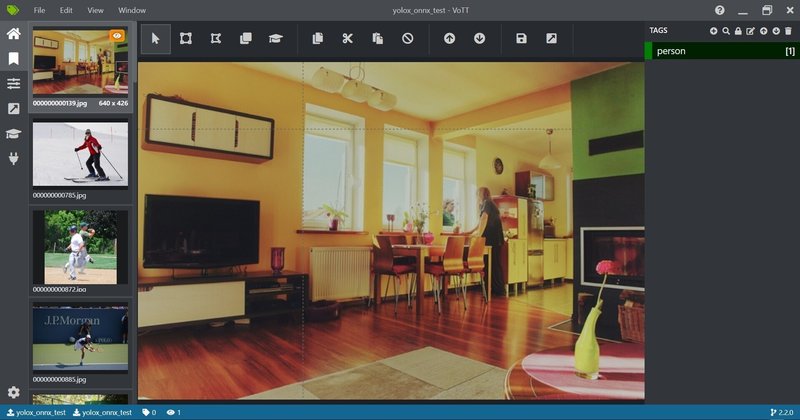
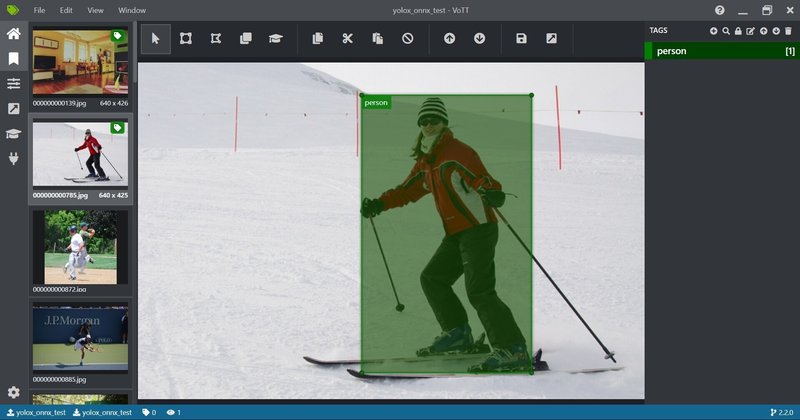
最初アノテーションツールVOTTを開いてプロジェクトを作成すると、以下の画面のようになります。まだバウンディングボックスは表示されていません。
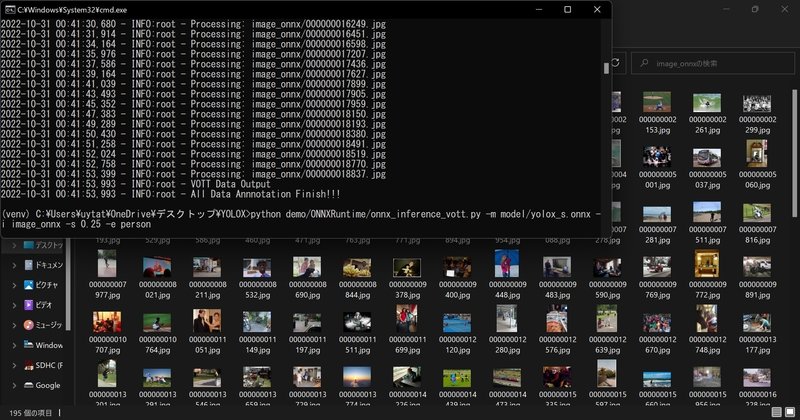
続いて、今回第7章で紹介するPythonプログラムを実行します。
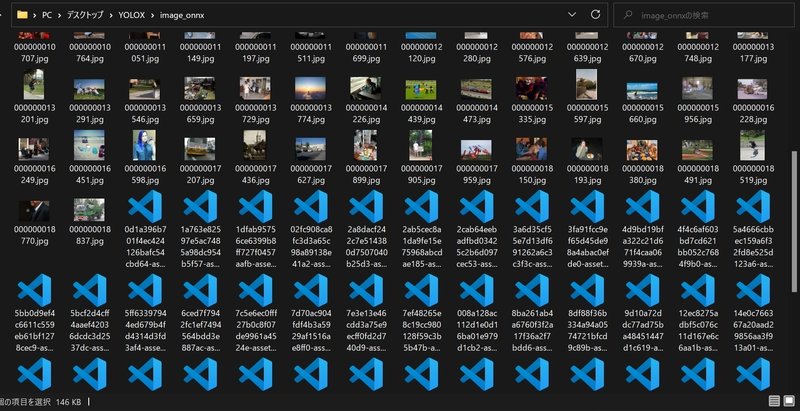
すると画像ファイル内にjsonファイルが作成されます。
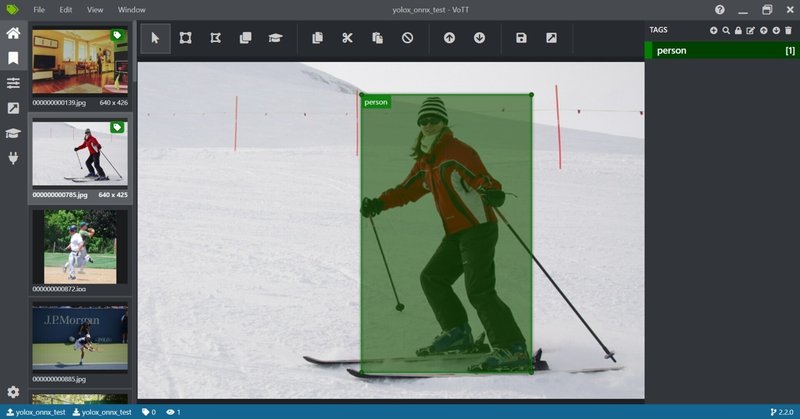
先ほど作成したプロジェクトを再度開くとバウンディングボックスが表示されています。きれいにバウンディングボックスが描画されているわけではないので、手動で微調整を行います。
3. 使用するツール
3.1 物体検出モデル:YOLOX
以下のリンクのYOLOXを使用します。環境構築の手順は5章で説明します。
3.2 アノテーションツール:VOTT
以下のリンクのVOTTを用います。Windowsであればexeファイルをダウンロード・実行してインストールします。
4. 動作環境
【PC】
Windows 11 pro
【Python】
3.8.5
【仮想環境】
venv
【ライブラリ】
certifi 2022.6.15
charset-normalizer 2.1.1
colorama 0.4.5
cycler 0.11.0
flatbuffers 2.0.7
fonttools 4.37.1
idna 3.3
install 1.3.5
kiwisolver 1.4.4
loguru 0.6.0
matplotlib 3.5.3
ninja 1.10.2.3
numpy 1.23.2
onnx 1.8.1
onnx-simplifier 0.3.5
onnxoptimizer 0.3.1
onnxruntime 1.8.0
opencv-python 4.6.0.66
packaging 21.3
Pillow 9.2.0
pip 22.2.2
protobuf 3.20.0
pycocotools 2.0.4
pyparsing 3.0.9
python-dateutil 2.8.2
requests 2.28.1
setuptools 47.1.0
six 1.16.0
tabulate 0.8.10
thop 0.1.1.post2207130030
torch 1.12.1
torchvision 0.13.1
tqdm 4.64.0
typing_extensions 4.3.0
urllib3 1.26.12
win32-setctime 1.1.0
yolox 0.3.0
5. YOLOXの動作環境の構築と動作確認
5.1 YOLOXのクローン
以下のコマンドでダウンロードします。
git clone https://github.com/Megvii-BaseDetection/YOLOX
cd YOLOX
以下のリンクからもzipファイルでダウンロードできます。
https://github.com/Megvii-BaseDetection/YOLOX
5.2 仮想環境venvの作成と起動
今回、YOLOXはvenv環境上で動作させます。以下の手順でvenv環境を作成・起動します。
#venv作成:python3.8
python -m venv venv
#or py -3.8 -m venv venv
#venv起動
.\venv\Scripts\activate5.3 ライブラリのインストール
pipで必要なライブラリをインストールします。
pip install -U pip
pip install -r requirements.txt
pip install -v -e .5.4 ONNXモデルのダウンロード
YOLOXディレクトリ内にmodelフォルダを作成して、そこにONNXモデルをダウンロードします。今回はyolox_s.onnxをダウンロードします。ご自身の求める精度に応じてモデルを変更してください。
mkdir model
cd model
wget https://github.com/Megvii-BaseDetection/YOLOX/releases/download/0.1.1rc0/yolox_s.onnx手動でも以下のリンクからダウンロードできます。モデル表のWeights列のgithubを押すとダウンロードできます。
https://github.com/Megvii-BaseDetection/YOLOX/tree/main/demo/ONNXRuntime
5.5 動作確認
YOLOXディレクトリ内で以下のコマンドを実行すると、デモが実行されて動作を確認することができます。
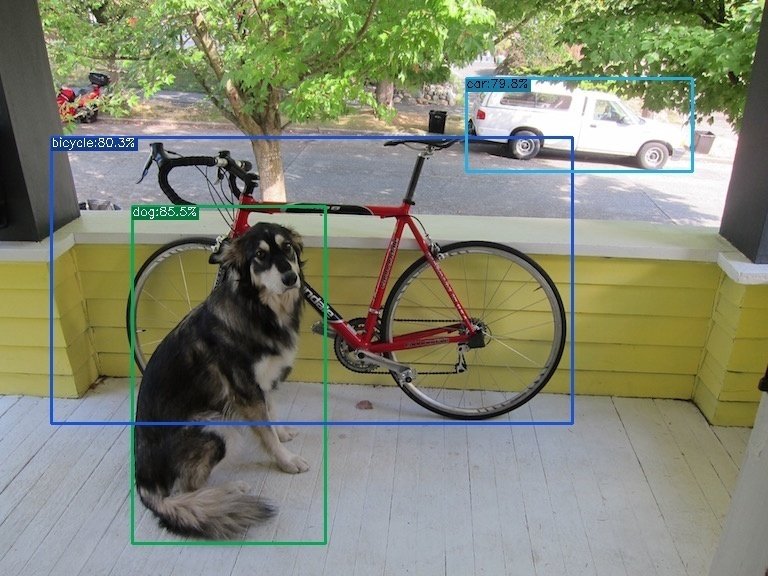
python demo/ONNXRuntime/onnx_inference.py -m model/yolox_s.onnx -i assets/dog.jpg -o outputs -s 0.3 --input_shape 640,640YOLOX内にoutputsフォルダが生成されて以下のようなバウンディングボックスが描画された画像が生成されていると思います。生成されていればこれで動作確認はOKです。
6. VOTTのインストール
以下のリンクから最新のものをダウンロードしてください。
以降で自動アノテーション手法を紹介していきます。
7. 自動アノテーション手法の紹介
7.1 VOTTでプロジェクト作成
以下の記事の2.2のプロジェクト新規作成まで行ってください。以下の方法で実施すると、アノテーション画像が格納されたフォルダ内に.vottファイルが出来ています。
なお、アノテーション画像が格納されたフォルダは、YOLOXディレクトリ内の階層に置いてください。
YOLOX
├─assets
├─datasets
├─demo
├─・・・
├─yolox
├─yolox.egg-info
└─<アノテーション画像が格納されたフォルダ>
├─<image1>.jpg
├─・・・
└─<.vottファイル名>.vottここから先は
¥ 1,000
この記事が気に入ったらサポートをしてみませんか?