
【ローカルLLM】Ollama Open WebUI 完全解説【初級向け】

【追記:2024年8月31日】Apache Tikaの導入方法を追記しました。日本語PDFのRAG利用に強くなります。
はじめに
本記事は、ローカルパソコン環境でLLM(Large Language Model)を利用できるGUIフロントエンド (Ollama) Open WebUI のインストール方法や使い方を、LLMローカル利用が初めての方を想定して丁寧に解説します。
※ 画像生成AIと同じで、ローカルでAIを動作させるには、ゲーミングPCクラスのパソコンが必要になります。具体的には、16GB以上のシステムメモリと、8GB以上のNVIDIA製のGPUメモリが必要になります。

■ LLM をローカルで利用するメリット
ChatGPT や Gemini、Copilot等が一般的になり、AI とチャットを通して情報を得たり、解析する行為が当たり前になりました。しかし、基本無料で利用可能なこれらのサービスを、なぜローカルで行う必要があるのか?何か利点があるのか?に関して考察してみます。
メリット
もちろん大きな理由の一つは(電気代は必要ですが)無料であることです。特にAPI利用時のような利用データに比例して課金される用途では、費用の概算があらかじめ必要になったり、大データを扱う時の精神的負荷が大きくなって本来の作業に集中できなくなったりします。トライ&エラーの作業を行うと損した気分にもなります。
次に、実用的な利点を上げると、継続性やカスタマイズ性、自由度の高さです。企業の突然の広告導入や仕様変更、運営サービス終了に振り回される事なく、自分のやり方でAIを扱う事が可能になります。かつてのYouTubeに広告がなかった(バナーのみ)ように、AI企業が独占・寡占するようになれば、いずれChat利用する際に広告アンケートに答えたり、広告文章を読んで返答するなどの作業を強制させられる可能性を否定できません。そして広告などの仕様変更の都度、ローカル側で構築した独自システムは産廃となります。
ローカルで利用する場合は、API経由であってもコマンド経由であっても制限なく利用できるため、用途に無限の可能性があります。たとえば簡単なシステムのコマンドを作ることも簡単にできます。
過疎も関係なく恐怖のサ終も存在しないので、自分で構築したシステムや独自のノウハウは、ハードに問題が発生しない限り半永久的に自分のものになります。
最近は周知されてきましたが、GeminiやChatGPT等でやりとりしたチャット内容は、(規約にあり)再学習用のデータとして勝手に利用されます。個人情報や機密情報はもちろんですが、他人の書いたメール・文章などの著作物もデータとして許諾なくアップロードしてはいけません。これらは政府や企業のガイドラインにも書いてありますが、厳密に守ると、おそらく何もできなくなる事がわかると思います。また、ビジネス契約では再学習禁止を行う事もできますが、それでも論文や書籍などの著作物を他人のサーバーが利用する行為はルールや議論があります。ガイドラインを建て前論とグレーに考える人は多そうですが、ローカル利用であれば、これらの問題と無縁になります。
あとは、「ローカルの方が高速」とは一概に言えませんが、サーバー・トラブルでアクセス不能になる事がないので、安定した速度で利用する事が可能です。
しかし最大のメリットは思想の自由です。(他記事で紹介したように)Google Gemini に「天安門事件」を聞くとブロックされます。そしてブロックが続くと垢BAN制裁まで存在します。確かに不適切な内容をブロックする事は正常な社会の運用に必要な機能ですが、天安門の件のように独善的な正義を社会正義とし利用する事ほど怖いものはありません。ブロックする内容を企業や株主が決めるのではなく、客観的かつ民主的に判断する仕組みが存在しない限り、SFディストピアの世界になってしまいかねません。
デメリット
まずは初回時の起動の遅さがあげられます。何かを調べようとしてチャットを開始すると、ロードや初期化で数十秒待たされます。一度起動すれば二度目からは瞬時に回答してくれますが、これは実利用での致命的な欠点のひとつです。
ChatGPT等とくらべると、かなりおバカさんです。スペック上でも、一般的なLLMネットサービスのパラメータは 70B〜数百B(billion:十億)モデルである一方で、ローカルパソコンで利用できる実用的なサイズは7Bです。AI脳細胞の数が 1/10 以下なので、大きく劣ってしまう事は仕方がありません。しかし後述する RAG の仕組みを利用するとかなり改善できます。画像生成にも言える事ですが、AIツールは用途や範囲を限定すればするほど性能が上がるからです。
ローカルで実用的に実行するには高性能なGPUが必要で、ゲーミングPC程度のパソコンスペックが必要になります。もしノートPCで必要スペックを確保するとなると、かなり高価になってしまうと思います。具体的にはシステムメモリは16GB以上、GPUメモリは8GB以上は最低限必須です。ただし、筆者環境のようにGPUカードを二枚刺しできるのであれば、6G + 4G = 10GB という利用も可能です。
※ 3DソフトのGPUレンダリングでは、二枚のGPUが等しいメモリ内容をそれぞれのメモリに保存するため利用可能容量が増える事はありませんが、LLMの場合は分散して保持するので、単純な足し算が可能になります。
■ Open WebUI でできること紹介
はじめに Ollama Open WebUI でどのような事ができるのかを簡単に紹介します。
Open WebUI をシンプルに言うとChatGPTのUIクローンです。UIデザインやショートカットもほぼ共通です。
プリセットを登録できるモデルファイル
LLMモデル本体とその用途などのプロパティを紐つける仕組みです。(最近のバージョンでは、RAGのデータも関連付けることが出来るようになっています)例えば、
あなたはおみくじを行うAIです。「大吉」「吉」「中吉」「小吉」「末吉」「凶」「大凶」の7種類からランダムに選びます。
とシステムプロンプトに登録しておけば、おみくじAIとして振る舞ってくれます。ChatGPT で言う GPTs に相当する機能ですね。


プリセットとして登録できるので、用途に応じて切り替える事ができます。
RAGが利用できる
RAGとは Retrieval-Augmented Generation の略称で、日本語では「検索拡張生成」または「取得拡張生成」と訳されます。これは、LLMの生成能力に、外部の情報検索機能を組み合わせることで、回答の精度や質を向上させる技術です。手法も様々なものがあります。また、LLMが一度に扱えるトークン数(英語では約単語数に一致、日本語では約1文字1トークン)は一般に4096や8192なので、それらを大きく超える単語数を扱う場合にも利用されます。書籍数冊の全ページや、ある分野の全論文などのスケールでも扱えます。
Open WebUI でのRAGの使い方は3種類あります。
① ネットURLを情報元として参照する
「#」記号に続けてhttpsからURLを打ち込みエンターを押すと、参照先のデータを参照して利用できます。
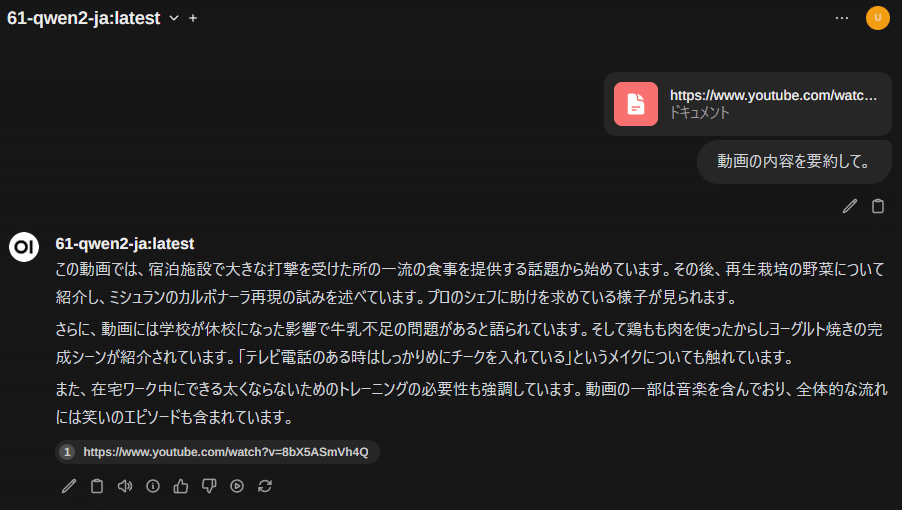
YouTubeのアドレスを指定すると、その動画の字幕を読み込みます。つまり「動画を要約して」とすると字幕の要約になります。
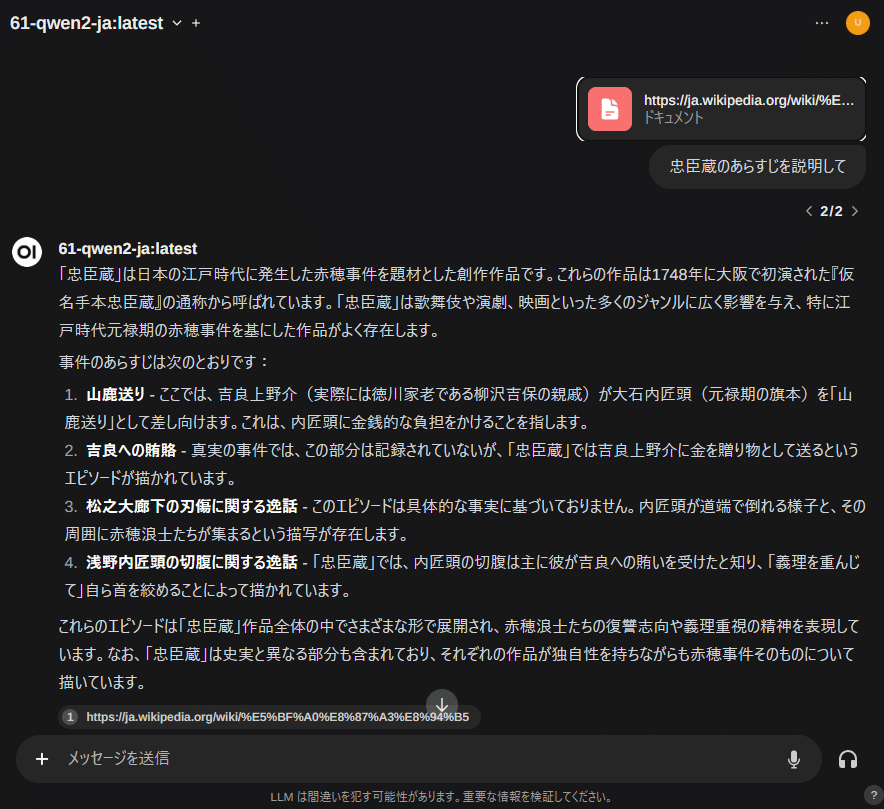
②あらかじめテキストやPDFドキュメントを登録しておく
「#」を最初に入力すると、登録しているドキュメントの候補が選択できます。※「mail-template-01.txt」には大量のメール例を記述しています
モデルファイルに紐つける事もできます。たとえばおみくじの内容をテキストデータとして登録しておけば、「おみくじモデル」を利用する際に自動的に参照します。
テキストやPDFをウインドウにドラッグ&ドロップしても利用可能です。


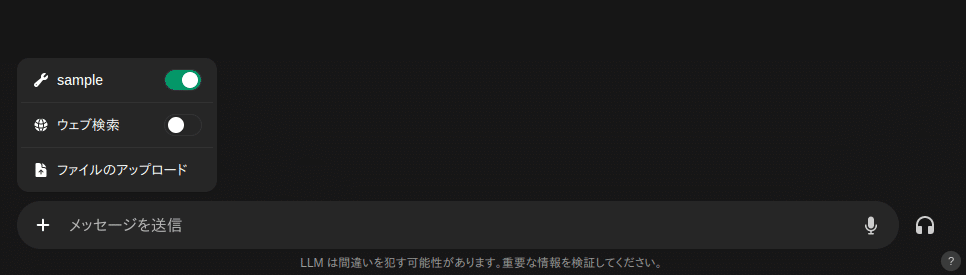
③ネット上の検索エンジンを利用する
ウェッブ検索をONにすると、DuckDuckGo 等を利用して検索結果を利用できます。


プロンプト・ショートカットの登録
定形文を登録する事が可能です。「/」記号を最初に入力すると一覧選択できるようになります。例えば「en」に「英語に翻訳して」と登録すると、簡単に入力する事が可能になります。
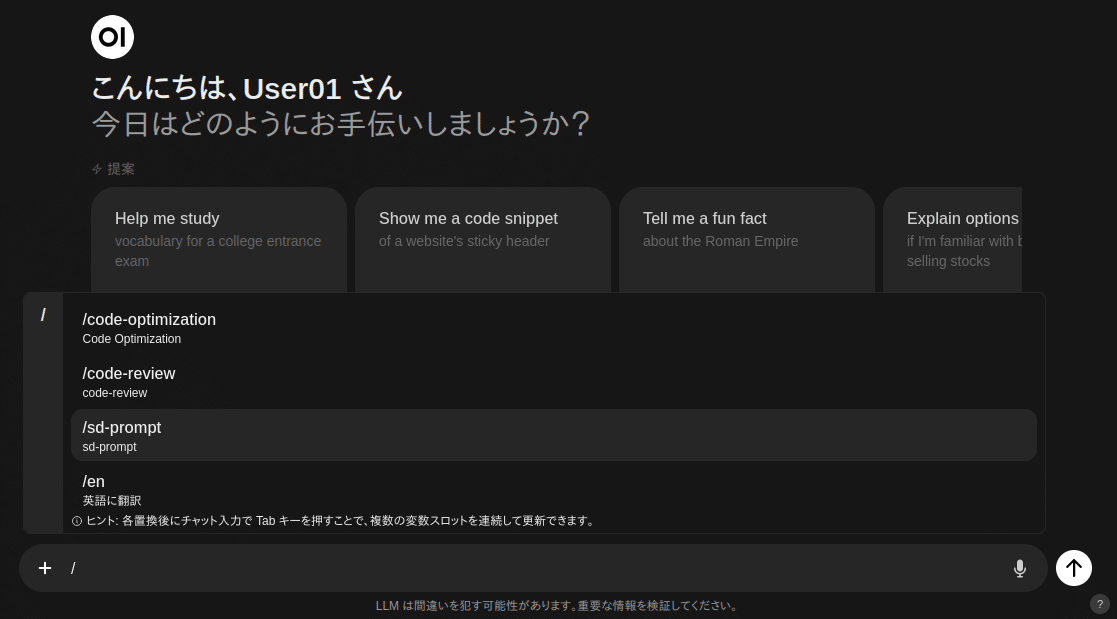
変数やクリップボードの内容を定形文章に自動展開させる事も可能です。たとえば、
## 指示
- 「資料文章」の内容の概要をできる限り詳しく丁寧に説明して。
- 「資料文章」の人物とその説明を列挙して。
- 「資料文章」の専門用語とその説明を列挙して。
## 資料文章
{{CLIPBOARD}}
とすると、{{CLIPBOARD}}にクリップボードの内容が展開されます。いちいち定形文を編集する事なくワンコマンドで入力できます。
変数を利用する場合は、次のようにすると、入力時に変数欄が選択フォーカスされた状態になります。変数が2つ以上ある場合は「タブ・キー」で次に移動できます。
Create a Stable Diffusion prompt for an image of "[words]"

システム上の任意のコードを実行
Python言語を利用して、任意のプログラムとLLM経由で連携する事ができます。セキュリティ的にはかなりデンジャラスですが、非常に強力なツールです。
たとえば、現在時刻はLLMだけでは取得できませんが、付属のサンプルのコードを利用すると、Pythonドキュメント生成ツール shpinx コメントをLLMが解釈して取得できるようになります。つまり、LLMが get_current_time を実行します。
"""
Get the current time in a more human-readable format.
:return: The current time.
"""

画像生成
LLMに画像を生成する機能はありませんが、Stable Diffusion と連携させる事で画像を生成する事ができます。ただし商用サービスのような高度な機能はないため、単にプロンプトから生成・表示するだけのものです。
読み上げ機能
ブラウザやOSのTTSを利用して文章を読み上げる事ができます。文章の生成後に自動で読み上げる事も可能です。もちろん、音声入力も可能です。

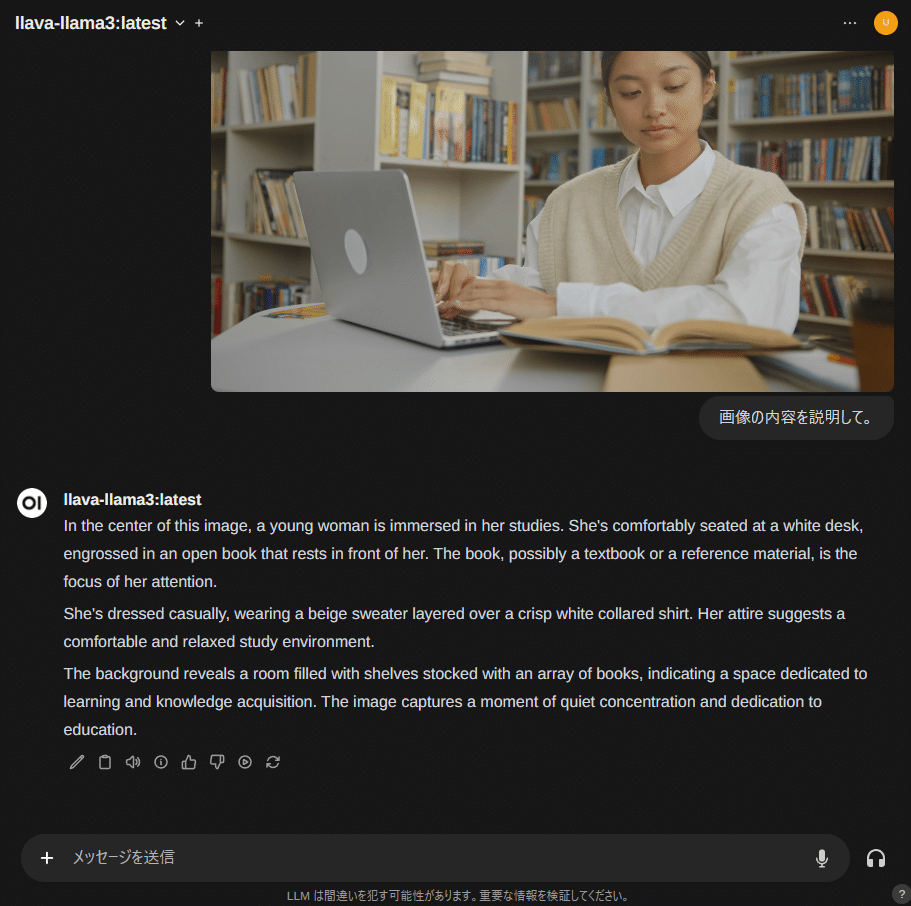
Visionモデルの利用
Visionモデルは、Vision Language Model(VLM)とも呼ばれる画像とテキストの両方の情報を理解し、処理できるAIモデルです。従来のLLMはテキストのみですが、Visionモデルは画像も扱えるため、より人間に近い知覚と理解が可能になります。
ウインドウに画像ファイルをドラッグ&ドロップ、もしくはコピー・ペーストで画像を貼り付ける事ができます。貼り付けた画像を元に、llava-llama3 等のVisionモデルで解析・対話できます。
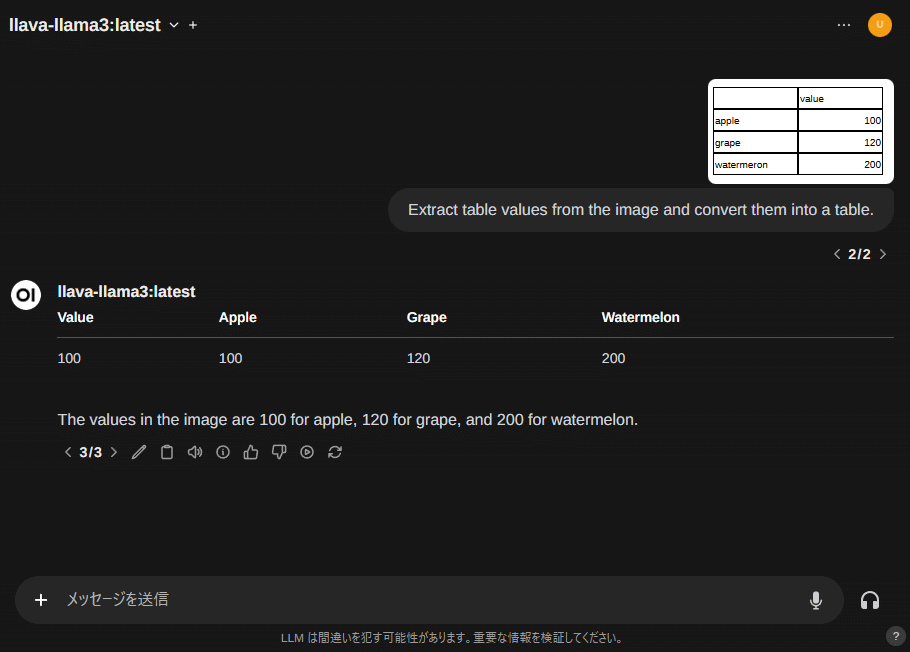
llava-llama3 は画像の表も読み込む事ができます。ただし性能は良くありません。日本語にも未対応です。
■ Open WebUIとは
公式レポジトリはこちら
ローカルのLLMモデルを管理し、サーバー動作する ollama コマンドのGUIフロントエンドが Open WebUI です。LLMのエンジン部ollamaとGUI部の Open WebUI で各LLMを利用する事になります。つまり動作させるためには、エンジンであるollamaのインストールも必要になります。
※ Windows 環境でLLMをGUI 操作できる2大人気ソフトウェアに LM Studio と Open WebUI があります。インストールと管理の簡易さの点では、統合環境である LM Studio の方が格段に優秀です。通常Windowsアプリとして利用できます。しかし作者独自のUIである事もあって人気はいまいちのようです。LLM 本体を管理するミドルウェアのデファクトスタンダードもollamaになってしまって更新が滞っています。これからは Open WebUI 一択になってしまうような気もします。Stable Diffusion と似たような状況ですね…
Open WebUI はLinuxで動作するwebアプリです。つまりWindowsで利用するにはWSL(Windows Subsystem for Linux)のインストールが必要です。多くの場合、Dockerまたは Docker Desktop 経由で利用する事になりますので、馴染のない人は少し苦労する事になるかもしれません。
■ ollama&Open WebUI のインストール
いくつか方法があり、それぞれにメリット・デメリットがありますが、筆者が最適と考える方法で説明します。WSLと Docker Desktop for Windows は一般的に利用されているものですので、他所でも多くの解説がされています。
インストールの流れ
【① ollama Windows版のインストール】
ollama とは、ローカルLLMを実行・管理するソフトウェアです。本体はコマンドです。
【② WSL(Windows Subsystem for Linux)の導入】
WSLとは、Windows上でLinuxを動作させるソフトウェアです。Windows 10/11 に付属するMicrosoft謹製の技術です。
ここでは Ubuntu 22.04.3 LTS を利用します。
Docker DesktopとOpen WebUIの動作に必要です。
【③ Docker Desktop for Windows の導入】
Dockerとは、広義には「コンテナ」を管理するソフトウェアですが、Windowsネイティブコンテナはあまり利用されていないので、実際にはWSL上の仮想Linuxをコンテナとして管理するソフトウェアです。
コンテナとは依存関係をOSから切り離したものです。依存関係に悩まされることなく、どんな環境上でも差異なく実行する事ができる技術の事です。
ここでは WSL2 をバックエンドとして利用する使い方を説明します。
【④ Open WebUI のインストール】
ollamaのGUIフロントエンドです。Webブラウザからアクセスして利用します。
【⑤ 動作確認】
ここから先は
この記事が気に入ったらサポートをしてみませんか?