
説明可能なAIモデル

What are Explainable models?
explainable modelとは
explainable modelとはAIによる予測の根拠を人が理解できるように説明するモデルを指します。近年の第三次AIブームに伴う機械学習技術の向上によって、より高精度な予測や複雑な処理が可能になりました。こうした技術はマーケティング、自動運転、診断支援など幅広い分野での応用が期待されます。一方で多くの予測モデルは予測理由の説明が困難であり、特にDeep Learningのような複雑なモデルを使うときは ‘ なぜその推論結果に至ったのか ‘ を人が理解するのは不可能に近いです。こうした問題をAIのブラックボックス問題と言い、AIサービスを利用する上での障壁となっています。このブラックボックス問題を解決するために考案された、モデルの予測プロセスを人が理解できるようにしたのがExperinable modelsです。
Explainable modelsの利用価値
Explainable modelsを利用することで得られるメリットには主に以下2つが考えられます。
信用の獲得
予測根拠を説明することで予測に対する納得感を与え、ユーザーからの信頼を得ることができます。これはAIサービスを提供する上で非常に重要な問題です。特に医療や金融、自動運転領域など、予測結果が利用者の安全や個人情報に影響を及ぼす可能性がある領域ではモデルの説明可能性が重要視されます。医療領域に関しては、AIはあくまで診断補助的な役割であり、診断の全責任は医師に存在しています。(医師法第17条 医師でなければ、医業をなしてはならない)加えて、医師は患者に対して診断結果だけでなく診断根拠まで説明する必要があります。そのためAIシステムが臨床利用されるためには、予測根拠を提示することによる医師からの信用の獲得が必要不可欠です。
モデルのデバッグ・最適化
Explainable modelを用いて予測モデルが注目している部分を可視化することで、モデルが望まない特徴量から予測していないかを調べることが可能です。これはモデルによる不当な差別の検出にも繋がります。モデルによる不当な差別は、後に述べるAI利活用原則の一つ「公平性の原則」に関わり、AIを利用する際に考慮するべき問題です。例えば、某企業の人材採用AIが男性を優遇していたことが判明し、廃止されたのは有名な話です。また、Explainable modelsはモデルの最適化にも利用できます。例えば、モデルが重要視していない特徴を除いたり、予測が間違っているサンプルのエラーを分析したりすることでモデルの予測性能が向上する可能性があります。
Experinable modelsの社会的注目
2018年に総務省が発足したAI利活用原則の一つに「透明性の原則」があります。AI利活用原則とは、AIの利用者が利活用段階において留意すべき事項をまとめたもので、透明性の原則では「AIサービスプロバイダ及びサービス利用者は、AIシステムまたはAIサービスの入出力の検証可能性及び判断結果の説明可能性に留意する」ことが要求されています。
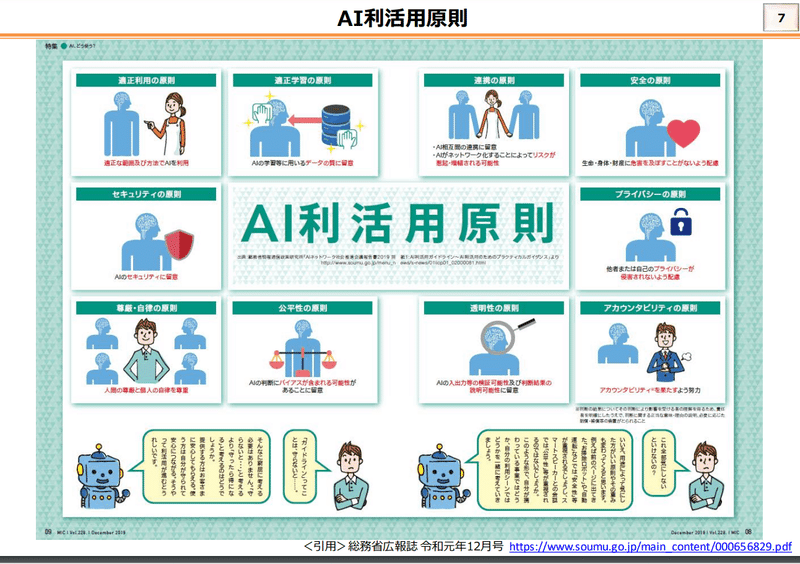
また「AIの説明可能性」はEUが発足した一般データ保護規則(GDPR:GDPR:General Data Protection Regulation)や、USが発表したXAI,DARPAプロジェクトでも言及されており、と世界的にも注目されていることがわかります。
How do Explainable models work?
Explainable modelsはどのようなアプローチで説明可能性を獲得するかによって、「Deep Explanation」「Interpretable Models」「Model Induction」の三種類に分類されます。
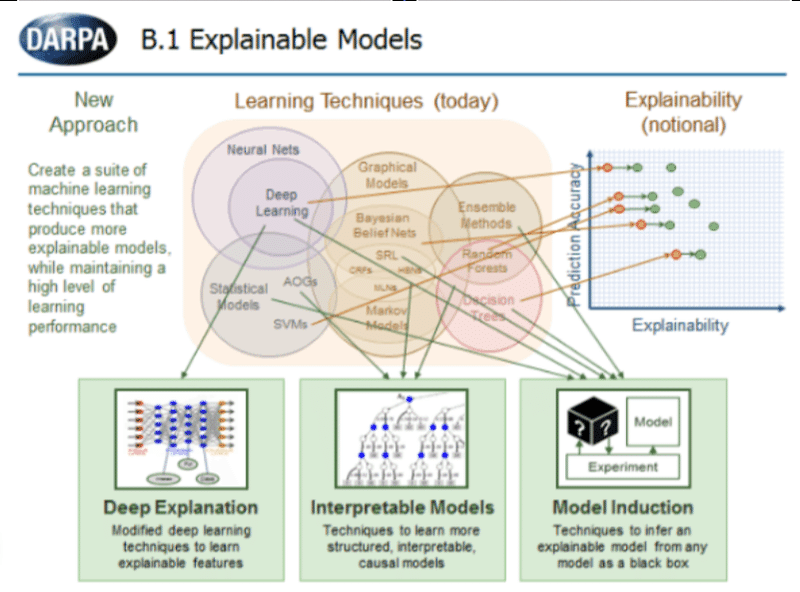
1.Deep Explanation(model specific)
Deep ExplanationはDeep Learningモデルそのものを利用して説明可能な特徴量を学習する方法です。そのため予測モデルに特有の説明モデルが構築されます。たとえば、Deep Learningモデルの特徴量を可視化させたり、予測根拠の説明文を学習したりするモデルなどがあります。
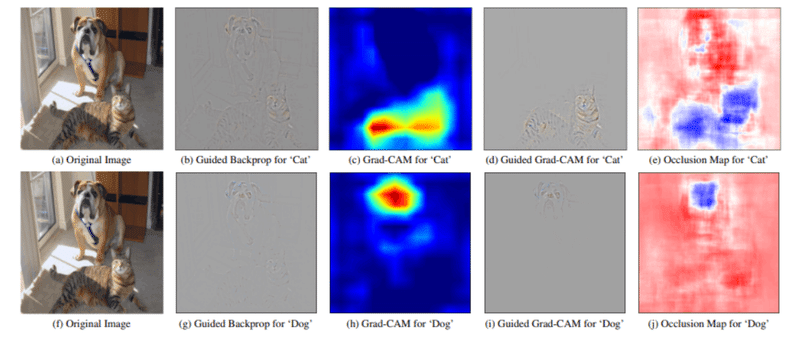
以下はGrad-CAMという手法を用いて特徴量を可視化している例です。Grad-CAMはCNNモデル全体に対する予測根拠を可視化するための手法で、入力画像に対して予測に寄与する度合いをヒートマップで表示します。画像をみると、上の段では猫の予測に関わるピクセルを、下の段では犬の予測に関わるピクセルをヒートマップの形で出力していることがわかります。ヒートマップとして出力することで個々の予測に対する視覚的な説明が可能になります。
またGVEというモデルは強化学習によって予測結果とともに予測根拠の説明文を出力します。GVEは、以下のように鳥の入力画像に対して「セジロコゲラ」という予測を返した上で、セジロコゲラの定義と画像の説明も一緒に出力しています。利用者は入力画像、予測対象の定義、画像の説明の三つを見比べることによって、モデル予測根拠を理解できます。

2.Interpretable Models
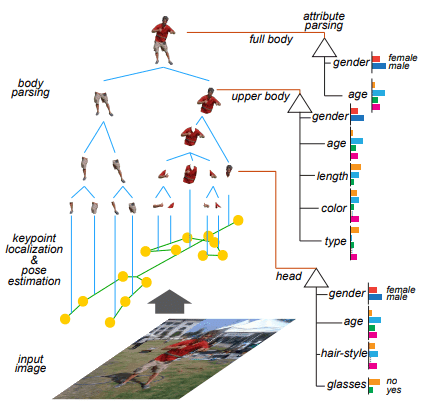
Interpretable Modelsはパラメータが少なく構造がシンプルなため人間が解釈可能なモデルを指します。たとえば、ベイズ推定モデル、線形回帰モデル、決定木、サポートベクターマシン(SVM)などがこれにあたります。一般的にDeep Learningモデルより表現力や精度は下がりますが、ネットワーク内のノードの意味を捉えやすいという利点があります。こうしたモデルの構造や入出力間の相関関係を理解しやすいモデルを使用することで、学習内容を理解するというアプローチです。以下の画像はParkらが提案したand-or grammar (A-AOG) modelという3 つの伝統的な文法形式のモデルを組み合わせる手法の概念図です。入力画像に対し、画像に映る人間のポーズの推定と属性の予測を直感的かつ解釈可能な形で出力します。
3.Model Induction(model agnostic)
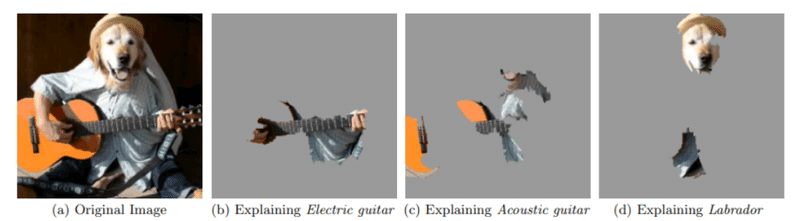
Model Inductionはブラックボックス化している任意の予測モデルに対して説明を行うための全く別のモデルを構築する事を指します。モデルの入出力をより簡単で解析可能なモデルで再現する、あるいは別のモデルで説明を生成するというアプローチです。この説明モデルは予測モデルに依存しないため、様々な予測モデルに対して応用が可能です。有名なものにはLIMEやSHAPなどがあります。以下はLIMEという局所的に有効な近似用の線形回帰モデルを構築する手法で画像分類タスクに説明を付与している例です。画像(a)の予測結果はスコアの高い順に「エレキギター」、「アコースティックギター」、「ラブラトールレトリーバー」となっており、画像(b)(c)(d)はそれぞれに対して入力画像のどの部分が予測に強く貢献しているかを表しています。画像を参照すると、(b)ではギターのネック部分、(c)ではギターのボディ部分、(d)ではラブラドールレトリーバーの顔部分が出力されており、納得感のある根拠をもとに予測していることがわかります。
Explainable models Applications and use case in life science field
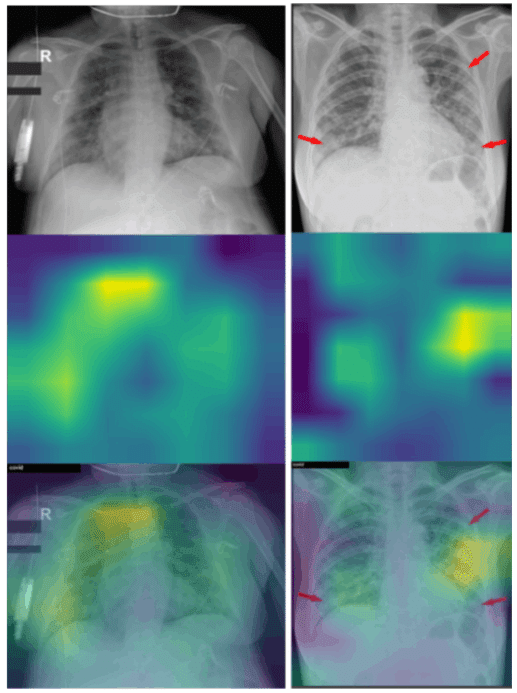
医療分野でも様々な疾患の予測モデルに対する説明手法が提案されています。ここでは、肺疾患患者のx線写真からCOVID-19由来かどうかを分類するモデルに対して、Grad-CAMを利用して視覚的説明を提供している事例をご紹介します。画像は上から順に、x線写真、Grad-CAMのヒートマップ、x線写真とヒートマップの合成画像となっており、左がCOVID-19未感染者、右がCOVID-19感染者のx線写真です。また左の写真には放射線科医がCOVID-19患者に特有の多巣性の斑状の影に赤い矢印を付けています。注目すべき点は左右両方の症例において肺領域で高い値を示している点です。このため、モデルは 肺領域の情報からCOVID-19 と一般的な肺疾患を区別していると言えます。しかし、COVID-19患者の写真を見ると左側の赤い矢印はヒートマップと対応しているのに対し、右の二つの矢印は医師とモデルの注目領域にずれが生じていることがわかります。
Introduction of our project using Explainable models
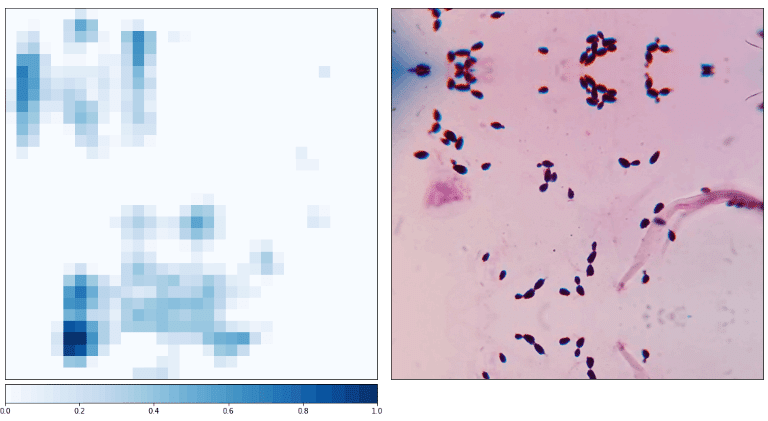
当社グループでは深層学習アルゴリズムを活用してグラム染色画像から細菌感染症の菌種推定を行うことに成功しました。この技術をもとに、世界中の医師が迅速かつ容易に細菌感染症の診断支援を行うモバイルアプリを開発し、世界中で拡大する薬剤耐性問題の解決に貢献することを目指しています。当社グループが開発したモデルを用いて、Candida albicansのグラム染色画像をGrad-CAMで特徴量可視化を行いました。その結果、画像の菌体部分がヒートマップと対応しており、判断根拠としていることがわかりました。このように、説明可能なAIを取り入れることで、結果の信頼性の向上が可能です。
Discusion ~Explainable AI に対する攻撃 [8]~
様々な手法が提案され、社会的注目度も高いexplanation modelsですが、explanation modelに対する攻撃手法も発表されています。例えば、オリジナル画像に対し、人間にはわからないように細工を施すことで誤った説明に誘導する攻撃手法があります。以下の画像をご覧ください。右上はオリジナルの犬の画像で、右下はオリジナル画像に対してexplanation modelsによる説明が付与された画像です。犬の目や耳、鼻が強調されており、それらの箇所が予測に大きく貢献することを示しています。一方で、左上は誤った説明になるように細工された画像です。一見オリジナル画像と同じに見えますが、explanation modelを適用した結果には、「this explanation was manipulated(この説明は操作された)」という攻撃者からのメッセージが表示されています。この攻撃手法では、オリジナル画像と細工画像が近い状態を維持しつつ、同時に説明画像を攻撃者が用意したものに近づけるような最適化問題を解くモデルが使われています。こうした攻撃手法を悪用すると、でたらめな説明をさせることで推論結果の根拠照合を混乱させ、その説明モデルの信用を失墜させることができます。そのため、Explainable modelを使用する際には、説明が攻撃者の手により恣意的な結果を表示していないかについても考える必要があります。

【参考文献】
[1] 総務省. 総務省広報誌 令和元年12月号. 参照: 2022年12月26日.
https://www.soumu.go.jp/main_content/000656829.pdf
[2]NASA. NASA Goddard Workshop on ARTIFICIAL INTELLIGENCE. 参照: 2022年12月26日.https://asd.gsfc.nasa.gov/conferences/ai/program/003-XAIforNASA.pdf
[3]R. R. Selvaraju, A. Das, R. Vedantam, M. Cogswell, D. Parikh, D. Batra, 「Grad-CAM: Why did you say that?」, arXiv preprint arXiv:1611.07450, 2016.
[4]L. A. Hendricks, Z. Akata, M. Rohrbach, J. Donahue, B. Schiele, T. Darrell, 「Generating visual explanations」, European conference on computer vision, 2016, pp. 3–19.
[5]S. Park, B. X. Nie, S.-C. Zhu, 「Attribute and-or grammar for joint parsing of human attributes, part and pose」, arXiv preprint arXiv:1605.02112, 2016.
[6]M. T. Ribeiro, S. Singh, C. Guestrin, 「『 Why should i trust you?』 Explaining the predictions of any classifier」, Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining, 2016, pp. 1135–1144.
[7]L. Brunese, F. Mercaldo, A. Reginelli, A. Santone, 「Explainable deep learning for pulmonary disease and coronavirus COVID-19 detection from X-rays」, Computer Methods and Programs in Biomedicine, vol. 196, p. 105608, 2020.
[8]A.-K. Dombrowski, M. Alber, C. Anders, M. Ackermann, K.-R. Müller, P. Kessel, 「Explanations can be manipulated and geometry is to blame」, Advances in Neural Information Processing Systems, vol. 32, 2019.
カーブジェン・エンジニアチームで一緒に働きませんか?
<募集ポジションはこちら>
<カジュアル面談希望はこちら>
https://carbgem.com/contact/
①お問い合わせ内容→「採用について」を選択
②必要事項をフォーム入力の上、「お問い合わせ内容詳細」に希望職種を明記