
CNNを使用した野菜の識別アプリ

※「このブログはAidemy Premiumのカリキュラムの一環で、受講修了条件を満たすために公開しています。」
昨今のリスキリングでAI人材を育成ということ流れに乗り、給付金を利用し、以前より関心のあったプログラミング、AI分野を学びたく、AidemiyのAIアプリ開発講座を受けました。
今回作成したのは、修了コースの成果物として6種類の野菜の識別アプリです。にんじん🥕、ブロッコリー🥦、カボチャ🎃、トマト🍅、キャベツ🥬、大根(絵文字なかった)
なぜ、この6種類を選んだかというと、ーーーーーーー
私の大好物だからです✨
さて、解説をはじめます。
アプリ作成の概要
画像データの収集
画像の学習
結果と試行錯誤
まとめ
開発環境
Visual Studio Code
Google colaboratory
野菜と果物6種類の判別アプリ
まずこちらが作成したコードになります。
from google.colab import drive
drive.mount('/content/drive')
import cv2
import os
import matplotlib.pyplot as plt
import numpy as np
from tensorflow.keras.utils import plot_model
from tensorflow.keras import optimizers
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.datasets import cifar10
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras.utils import to_categorical
import numpy as np
from sklearn.model_selection import train_test_split
# お使いの仮想環境のディレクトリ構造等によってファイルパスは異なります。
Carrot = os.listdir("/content/drive/MyDrive/Carrot")
Broccoli = os.listdir("/content/drive/MyDrive/Broccoli")
Pumpkin = os.listdir("/content/drive/MyDrive/Pumpkin")
Tomato = os.listdir("/content/drive/MyDrive/Tomato")
Cabbage = os.listdir("/content/drive/MyDrive/Cabbage")
Radish = os.listdir("/content/drive/MyDrive/Radish")
#野菜の画像を格納するリストを作成する
img_Carrot = []
img_Broccoli = []
img_Pumpkin = []
img_Tomato = []
img_Cabbage = []
img_Radish = []
for i in range(len(Carrot)):
img = cv2.imread("/content/drive/MyDrive/Carrot/" + Carrot[i]) #ディレクトリ名語尾に /
if (img is None):
continue
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img = cv2.resize(img, (128,128))
img_Carrot.append(img)
for i in range(len(Broccoli)):
img = cv2.imread("/content/drive/MyDrive/Broccoli/" + Broccoli[i] )#ディレクトリ名語尾に/
if (img is None):
continue
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img = cv2.resize(img, (128,128))
img_Broccoli.append(img)
for i in range(len(Pumpkin)):
img = cv2.imread("/content/drive/MyDrive/Pumpkin/" + Pumpkin[i]) #ディレクトリ名語尾に /
if (img is None):
continue
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img = cv2.resize(img, (128,128))
img_Pumpkin.append(img)
for i in range(len(Tomato)):
img = cv2.imread("/content/drive/MyDrive/Tomato/" + Tomato[i]) #ディレクトリ名語尾に /
if (img is None):
continue
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img = cv2.resize(img, (128,128))
img_Tomato.append(img)
for i in range(len(Cabbage)):
img = cv2.imread("/content/drive/MyDrive/Cabbage/" +Cabbage[i]) #ディレクトリ名語尾に /
if (img is None):
continue
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img = cv2.resize(img, (128,128))
img_Cabbage.append(img)
for i in range(len(Radish)):
img = cv2.imread("/content/drive/MyDrive/Radish/" + Radish[i]) #ディレクトリ名語尾に /
if (img is None):
continue
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img = cv2.resize(img, (128,128))
img_Radish.append(img)
X = np.array(img_Carrot + img_Broccoli + img_Pumpkin + img_Tomato + img_Cabbage + img_Radish)
y = np.array([0]*len(img_Carrot) + [1]*len(img_Broccoli) + [2]*len(img_Pumpkin) + [3]*len(img_Tomato) + [4]*len(img_Cabbage) + [5]*len(img_Radish))#ディレクトリ名語尾に/
X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2, random_state=42)
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
# vgg16のインスタンスの生成
input_tensor = Input(shape=(128, 128, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='sigmoid'))
# ドロップアウト
top_model.add(Dropout(rate=0.5))
top_model.add(Dense(6, activation='softmax'))
# モデルの連結
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
# vgg16の重みの固定
for layer in model.layers[:19]:
layer.trainable = False
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),
metrics=['accuracy'])
model.summary()
#学習過程の取得
history = model.fit(X_train, y_train, batch_size=32, epochs=10, validation_data=(X_test, y_test))
plt.plot(history.history["accuracy"], label="accuracy", ls="-", marker="o")
plt.plot(history.history["val_accuracy"], label="val_accuracy", ls="-", marker="x")
plt.ylabel("accuracy")
plt.xlabel("epoch") #凡例表記
plt.legend(loc="best")
plt.show()
model.save("my_model.h5")1、画像データの収集
まず、画像データを、kaggle よりお借りした6種類の画像データをダウンロードしました。
画像をGoogleドライブにアップロードします。
from google.colab import drive
drive.mount('/content/drive')マウント方法は下記サイトを参考にさせていただきました。
2、画像の学習
コード1
野菜の画像を格納するリストを作成する
img_Carrot = []
img_Broccoli = []
img_Pumpkin = []
img_Tomato = []
img_Cabbage = []
img_Radish = []
コード2
(例)Carrotのリストに格納している画像ファイルを読み込み、それぞれの画像を処理し、img_Carrotに格納する。
for i in range(len(Carrot)):
img = cv2.imread("/content/drive/MyDrive/Carrot/" + Carrot[i]) #ディレクトリ名語尾に /
if (img is None):
continue
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img = cv2.resize(img, (128,128))
img_Carrot.append(img)
コード3
画像データをNumpy配列に変換しXという変数に格納、各画像データにラベルを作成しyという配列に格納する。
testサイズは0.2に設定。
X = np.array(img_Carrot + img_Broccoli + img_Pumpkin + img_Tomato + img_Cabbage + img_Radish)
y = np.array([0]*len(img_Carrot) + [1]*len(img_Broccoli) + [2]*len(img_Pumpkin) + [3]*len(img_Tomato) + [4]*len(img_Cabbage) + [5]*len(img_Radish))#ディレクトリ名語尾に/
X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2, random_state=42)
コード4
KerasのSequentialモデルを使用してtop model を定義。vgg16のインスタンスを生成
# vgg16のインスタンスの生成
input_tensor = Input(shape=(128, 128, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='sigmoid'))
# ドロップアウト
top_model.add(Dropout(rate=0.5))
コード5
vgg16の重みの固定
19層にしました。
# vgg16の重みの固定
for layer in model.layers[:19]:
layer.trainable = False
コード6
学習させます。
#学習過程の取得
history = model.fit(X_train, y_train, batch_size=32, epochs=10, validation_data=(X_test, y_test))
model.save("my_model.h5")3、結果と試行錯誤
まず、早速エラーがでたので当該箇所を探して行きます。そもそも格納する画像の野菜名が間違えていたり、()や、を消してしまっていたりを修正していき、再度コードを実行します。
Epoch 1/10
2/2 [==============================] - 198s 96s/step - loss: 64.0666 - accuracy: 0.1892 - val_loss: 10357.5029 - val_accuracy: 0.1579
Epoch 2/10
2/2 [==============================] - 183s 95s/step - loss: 18199.8926 - accuracy: 0.1892 - val_loss: 550454.3750 - val_accuracy: 0.1053
Epoch 3/10
2/2 [==============================] - 179s 95s/step - loss: 777169.8750 - accuracy: 0.1351 - val_loss: 2388873.0000 - val_accuracy: 0.2632
エラーは出なくなったが、コレでは失敗です…
ここでチューターに、指導を受ける。
入力層が、6種類を判別するのに10になっていたので6へ変更。
top_model.add(Dense(6, activation='softmax'))また、必要のないコードを消すようになどの指導を受け、更に画像サイズを初期500
にしてたの128へ変更するなどして再度実行。
しかし変わらず…
そもそも画像が10枚ほどで学習しようとしたのが無理があったので、今度は、画像を各1000枚に増加し、学習させました。
しかしやはり正解率は30%ほど。
そこでactivation(活性化関数)を、Relu関数から sigmoid関数に変更しました。
top_model.add(Dense(256, activation='sigmoid'))結果lossは0.02ほど。accuracyは一気に99%!活性化関数はReluではなく、sigmoidが正解だったようです。
Epoch 1/10
150/150 [==============================] - 10s 61ms/step - loss: 0.2919 - accuracy: 0.9071 - val_loss: 0.0560 - val_accuracy: 0.9925
Epoch 2/10
150/150 [==============================] - 8s 50ms/step - loss: 0.0692 - accuracy: 0.9827 - val_loss: 0.0283 - val_accuracy: 0.9942
Epoch 3/10
150/150 [==============================] - 8s 50ms/step - loss: 0.0495 - accuracy: 0.9865 - val_loss: 0.0263 - val_accuracy: 0.9933
Epoch 4/10
150/150 [==============================] - 8s 50ms/step - loss: 0.0371 - accuracy: 0.9925 - val_loss: 0.0203 - val_accuracy: 0.9958
Epoch 5/10
150/150 [==============================] - 9s 58ms/step - loss: 0.0273 - accuracy: 0.9946 - val_loss: 0.0167 - val_accuracy: 0.9950
Epoch 6/10
150/150 [==============================] - 9s 58ms/step - loss: 0.0258 - accuracy: 0.9937 - val_loss: 0.0168 - val_accuracy: 0.9958
Epoch 7/10
150/150 [==============================] - 9s 58ms/step - loss: 0.0193 - accuracy: 0.9958 - val_loss: 0.0146 - val_accuracy: 0.9967
Epoch 8/10
150/150 [==============================] - 9s 58ms/step - loss: 0.0160 - accuracy: 0.9965 - val_loss: 0.0164 - val_accuracy: 0.9925
Epoch 9/10
150/150 [==============================] - 8s 51ms/step - loss: 0.0158 - accuracy: 0.9960 - val_loss: 0.0140 - val_accuracy: 0.9942
Epoch 10/10
150/150 [==============================] - 9s 58ms/step - loss: 0.0136 - accuracy: 0.9971 - val_loss: 0.0131 - val_accuracy: 0.9958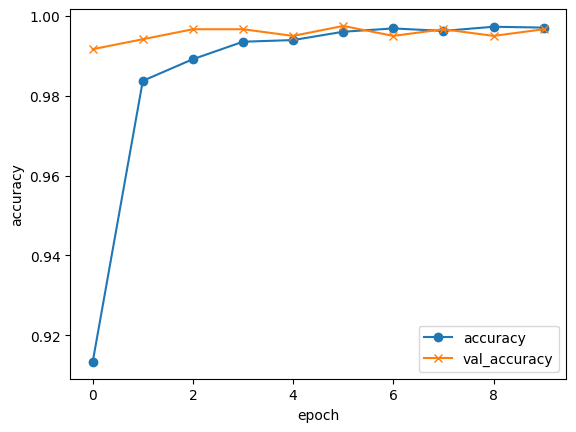
Webアプリ作成のコードはAidemyよりお借りしま
した。
import os
from flask import Flask, request, redirect, render_template, flash
from werkzeug.utils import secure_filename
from tensorflow.keras.models import Sequential, load_model
from tensorflow.keras.preprocessing import image
import numpy as np
classes = ["img_Carrot","img_Broccoli","img_Pumpkin","img_Tomato","img_Cabbage","img_Radish","]
image_size = 128
UPLOAD_FOLDER = "uploads"
ALLOWED_EXTENSIONS = set(['png', 'jpg', 'jpeg', 'gif'])
app = Flask(__name__)
def allowed_file(filename):
return '.' in filename and filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
model = load_model('./model.h5')#学習済みモデルをロード
@app.route('/', methods=['GET', 'POST'])
def upload_file():
if request.method == 'POST':
if 'file' not in request.files:
flash('ファイルがありません')
return redirect(request.url)
file = request.files['file']
if file.filename == '':
flash('ファイルがありません')
return redirect(request.url)
if file and allowed_file(file.filename):
filename = secure_filename(file.filename)
file.save(os.path.join(UPLOAD_FOLDER, filename))
filepath = os.path.join(UPLOAD_FOLDER, filename)
#受け取った画像を読み込み 、np形式に変換
img = image.load_img(filepath, grayscale=True, target_size=(image_size,image_size))
img = image.img_to_array(img)
data = np.array([img])
#変換したデータをモデルに渡して予測する
result = model.predict(data)[0]
predicted = result.argmax()
pred_answer = "これは " + classes[predicted] + " です"
return render_template("index.html",answer=pred_answer)
return render_template("index.html",answer="")
if __name__ == "__main__":
port = int(os.environ.get('PORT', 8080))
app.run(host ='0.0.0.0',port = port)<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>6種類の野菜を判別(にんじん、ブロッコリー、トマト、大根、キャベツ、カボチャ)</title>
<link rel="stylesheet" href="./static/stylesheet.css">
</head>
<body>
<header>
<img class="header_img" src="https://aidemyexstorage.blob.core.windows.net/aidemycontents/1621500180546399.png" alt="Aidemy">
<a class="header-logo" href="#">Number Classifier</a>
</header>
<div class="main">
<h2> AIが送信された野菜を識別します</h2>
<p>画像を送信してください</p>
<form method="POST" enctype="multipart/form-data">
<input class="file_choose" type="file" name="file">
<input class="btn" value="submit!" type="submit">
</form>
<div class="answer">{{answer}}</div>
</div>
<footer>
<img class="footer_img" src="https://aidemyexstorage.blob.core.windows.net/aidemycontents/1621500180546399.png" alt="Aidemy">
<small>© 2024 S.URAKAMI</small>
</footer>
</body>
</html>
style sheet.css
header {
background-color: #76B55B ;
height: 60px;
margin: -8px;
display: flex;
flex-direction: row-reverse;
justify-content: space-between;
}
.header-logo {
color: #fff ;
font-size: 25px;
margin: 15px 25px;
}
.header_img {
height: 25px;
margin: 15px 25px;
}
.main {
height: 370px;
}
h2 {
color: #444444 ;
margin: 90px 0px;
text-align: center;
}
p {
color: #444444 ;
margin: 70px 0px 30px 0px;
text-align: center;
}
.answer {
color: #444444 ;
margin: 70px 0px 30px 0px;
text-align: center;
}
form {
text-align: center;
}
footer {
background-color: #F7F7F7 ;
height: 110px;
margin: -8px;
position: relative;
}
.footer_img {
height: 25px;
margin: 15px 25px;
}
small {
margin: 15px 25px;
position: absolute;
left: 0;
bottom: 0;absl-py==0.9.0
astor==0.8.1
bleach==3.1.5
bottle==0.12.18
click==7.1.2
certifi==2020.6.20
chardet==3.0.4
flask==2.0.1
future==0.18.2
gast==0.3.3
grpcio==1.31.0
gunicorn==20.0.4
h5py==2.10.0
html5lib==1.1
itsdangerous==2.0
idna==2.10
Jinja2==3.0.1
line-bot-sdk==1.16.0
Markdown==3.2.2
MarkupSafe==2.0
numpy==1.18.0
oauthlib==3.1.0
pillow==7.2.0
protobuf==3.12.4
PyYAML==5.4.1
python-dotenv==0.14.0
requests==2.25.1
scipy==1.4.1
six==1.15.0
tensorboard==2.3.0
tensorflow-cpu==2.3.0
termcolor==1.1.0
urllib3==1.26.5
Werkzeug==2.0.0Flaskでは容量の上限があるようで、学習したh5ファイルが大きすぎたため、ホームページに実装できませんでした。おそらく何かしらの方法はあるはずですが、今の自分では見つけられませんでした。
今回はこのコードを持って成果物とさせていただこうと思います。
5、まとめ
なんとか作成はできましたが、個々のコードの理解はまだまだ不完全のため、理解を深めるために更に復習と、自分のスキルを上げるためにデータ分析を学んだり、他言語を学んでいこうと思います。
この記事が気に入ったらサポートをしてみませんか?