
Blue Prismベストプラクティス 構築編 2 エラーハンドリング – BlockとRecover

BlockとRecoverで想定外のエラーをキャッチする
想定できるエラーについては、皆さん既に、入力データの値の範囲をチェックする、などでハンドリングしていると思います。
では、想定外のエラーにはいったいどう対処したらいいのでしょうか。
この場合は、「ブロック(Block)」と「復元(Recover)」、「再開(Resume)」、「例外(Exception)」の4つのステージの組み合わせで実装します。
今回は、理想的な例外処理の実装を考えていきます。
結論から言うと、以下のようになっていることが望ましいです。
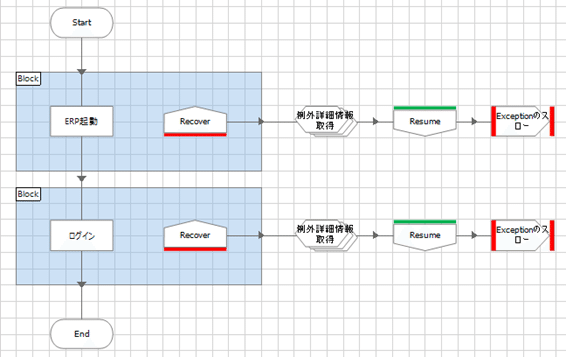
以下の点を守るよう注意して下さい。
1. Recover、Resumeステージを使った後、Endステージや通常の流れに合流させない。(これは発生したエラーをもみ消すことになります。)
2. RecoverとResumeの間にはロジックを入れない。最低限のエラー詳細情報取得処理のみとし、必要であれば、Resume処理の後ろに実装する。(この間で想定外のエラーが発生した場合、プロセスがバチンとその場で落ちます。)
3. どこでエラーが発生したか分かり易くし、さらに個別のハンドリングを実施しやすくするために、Blockをより小さい単位で囲むようにする。(これは効率性とバランスを取って下さい)
4. Blockで囲まないRecoverは極力使用しない。(ページのどこでエラーが発生したのか、分かり難くなります。)
5. 基本、オブジェクトでは、Block、Recoverでキャッチせず、そのまま例外が上位プロセスにスローされるようにする。つまり、上位プロセス側、理想はMain Page上でハンドリングを行う。「バブルアップさせて、最上位でハンドリングする」という考え方です。
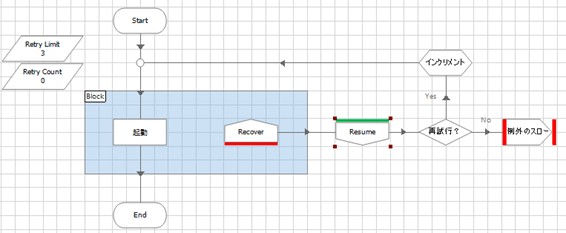
リトライ(再試行)する
ターゲットアプリケーションのシステムによっては、その信頼性に難がある場合、ネットワークやリソースに限界があるなどの理由により、アクセスエラーが発生するものもあると思います。
このようなケースでは、再試行ループを入れることにより、正常に処理が続行される可能性を高めることができます。例えばアプリケーションの起動時などがそれにあたります。
但し、再試行ループを実装する場合は、無限ループが発生しないように、最大試行回数をチェックするなどの仕組みを必ず入れるようにして下さい。
エラーの種類(Exception Type)について
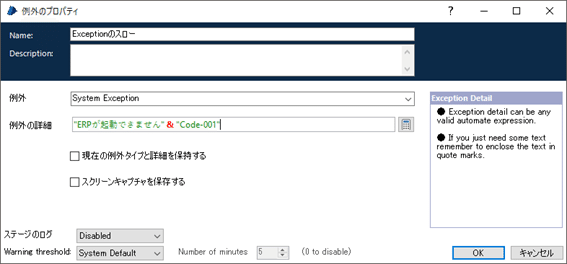
Exceptionステージでは、Exception Typeを明示的に指定しますが、この使い方も予めしっかり決めておくと良いでしょう。
入力データに誤りがあるような、業務エラー(Business Exception)なのか、それとも、システムにアクセスできない、システムが想定外の動きをしている、などのような、システムエラー(System Exception)なのか、を区別できるようなタイプを利用するようにします。
これにより、キャッチした上位プロセスやMain Pageでは、それが業務エラーであれば、残りの他のデータの処理を続行し、当該エラーデータを業務部門に対応を知らせる、逆にシステムエラーであれば、速攻処理を止めて、システム管理者に連絡する、といったハンドリングを実装できるようになります。
大規模な開発になると、開発標準ドキュメントなどで、エラー発生状況ごとに利用するException Typeを規約で定めます。(もしそうなっていない方は是非規約を見直し下さい。)そうでない場合でも、上位プロセスやプロセスのMain Pageでどのようにハンドリングすべきかを分かり易くするために、利用するException Typeのルール決めをしておくべきです。
一番回避したいのは、開発者が好き勝手に自前のException Typeを入力してしまうことです。
エラー箇所を特定するユニークな情報を設定したいのであれば、Exception Detail(例外の詳細)欄に情報を入力するようにして下さい。
まとめ
Exceptionハンドリング=例外処理は、Blue Prismのロボット構築において、耐障害性と回復性を向上させる、胆(キモ)となる考え方です。正しいエラーハンドリングは、堅牢性を確実に向上させ、エラーでプロセスが落ちてしまう事象の発生頻度は低減できます。
どうも最近、エラーが発生してプロセスが落ちるのが頻発するんだけど、、、といったことに心当たりがある方は、是非エラーハンドリングを見直してみて下さい。
※本投稿は、別ブログで掲載・公開していた内容に加筆・修正を加え再掲載しています。