
前頭前野におけるメタ強化学習の実装~人工知能と脳科学の融合~
数学者・大道芸人として有名なピーター・フランクルは、多言語話者で、12か国語話せるといわれている。世界には数十の言語を話せる人もいるようである。一つ一つの言語の習得も困難であるのに、なぜ多言語の習得が可能なのであろうか?
一般に、第2外国語は母語よりも、第3外国語は第2外国語よりも学習が容易である。これは、私たちが新しい技能を学習する際に、1から個別に学習するのではなく、どのように学習するかという枠組みを人生経験を通じて獲得しており、その一般化した知識を応用しているためであると考えられる。この概念は’learning to learn’(学習則の学習、メタ学習)として知られている。
メタ強化学習とは、異なる時間スケールで並列に機能する強化学習アルゴリズムを備えたメタ学習の枠組みである。AIの分野では、再帰結合ネットワークがシナプス可塑性を用いた遅いタイムスケールの強化学習を行い、再帰的な活動ダイナミクスが速いタイムスケールの強化学習を担うモデルが提唱されている。脳神経系のシミュレーションベースの先行研究では、ドーパミンの報酬予測誤差のシグナルがシナプス可塑性を変化させることで前頭前野がその活動ダイナミクスにより効率的な強化学習を行うようになるという形で、前頭前野がメタ強化学習を実装していることを示唆していた。しかし、このような可塑性と活動に基づく機構が実際に脳内でメタ強化学習を実装しているのかは実験的に示されていなかった。
本研究では、マウスと深層強化学習モデルに同じタスクを解かせることで、実験的に眼窩前頭皮質(OFC)と呼ばれる脳部位がメタ強化学習の実装に関与していることを示した。AI(人工知能)もBI(生物知能)もメタ強化学習を通して行動価値の安定な表象を獲得した。遅いタイムスケールの強化学習はOFCのシナプス可塑性によって、早いタイムスケールの強化学習はOFCの活動ダイナミクスによって担われる。
Hattori, R., Hedrick, N.G., Jain, A. et al. Meta-reinforcement learning via orbitofrontal cortex. Nat Neurosci (2023).
https://doi.org/10.1038/s41593-023-01485-3
Results
図1は、マウスの確率的リバーサルタスクをAIにも解かせることで、AIとBIが行うメタ強化学習を比較している。マウスに音刺激が提示されたのちに右(R)か左(L)を選ばせ、選択に依存した確率で報酬を与えるというタスクを学習させた(図1A)。この選択に依存した報酬の確率が手掛かりなしに60-80トライアルごとにスイッチすることで、マウスが試行錯誤から意思決定方策を学習することを促すタスク設計となっている。同様のタスクを神経活動のダイナミクスが早い強化学習を、神経可塑性が遅い強化学習を担うメタ強化学習のモデルでも解かせた(図1C)。強化学習のモデルとしてはAdvantage actor-critic (A2C)を用い、結合の重みの更新をセッション間のみに限定することで、再帰的ニューラルネットワーク(RNN)内で階層的なメタ強化学習が起こるように誘導している。AIもBIもこのタスクを学習することができ、高い報酬確率の行動を選択しやすくなった(図1E、F)。強化学習では、それぞれの状態で特定の行動を選択した際の価値が行動価値として定義され、意思決定方策の学習に重要であることが知られている。確率的リバーサルタスクを強化学習の枠組みでモデル化することで、AIやBIの行動時系列から行動価値が推定された(図1B,D)。本研究で用いているAIのメタ強化学習では、それぞれのトライアルでの行動価値が再帰的活動によって更新され、セッションを通じて行動価値に基づく行動方策がシナプス可塑性によって更新されていく(図1G)。AIもBIも学習により過去の報酬の履歴を意思決定に用いるようになるが、過去の行動の履歴はAIでのみ学習過程で意思決定に用いられるようになった(図1H,I)。また、異なる学習段階での方策の近さを測るために、方策のパラメーター空間でのコサイン類似度を定義した(図1J)。AIもBIも学習により報酬の履歴に関する方策は安定化するが、行動の履歴に関する方策はAIでのみ安定化することが分かった(図1K,I)。AIとBIの行動の違いは、部分的には脳にレンズを挿すという侵略的な手法を用いたことによるマウスのタスクパフォーマンスの低下に依存するようである。図1の結果は、AI・BI双方ともセッションを通じて(遅いタイムスケールで)、経験をどの程度意思決定に反映させるかを学習しており、報酬に基づく方策が安定化していることを示している。

図2は、眼窩前頭皮質(OFC)の可塑性がメタ強化学習に必要であることを示している。OFCは前頭皮質の腹側部に位置し、感覚や報酬、情動の情報を受けとり、意思決定等に関与することが知られている。今回前頭前野の中で特にOFCに注目した理由としては、メタ強化学習に重要なドーパミン神経の投射量が多いためのようだ。シナプス可塑性が遅い強化学習に必要であるか調べるために、シナプス強度を人工的に操作するツールが便利である。paAIP2は光依存的にCaMK2の働きを抑制することができる遺伝学的ツールで、特定の脳領域のシナプス可塑性を特定の期間抑制するために用いることができる(図2A-E)。実際にpaAIP2を用いてOFCのシナプス可塑性を低下させると、タスクパフォーマンスが落ち、報酬履歴に依存した意思決定が阻害された(図2F-H)。また、paAIP2の条件で学習による報酬履歴に依存した方策の安定化も阻害される(図2I,J)。これは、OFCの可塑性が遅いRLに必要であることを示している。
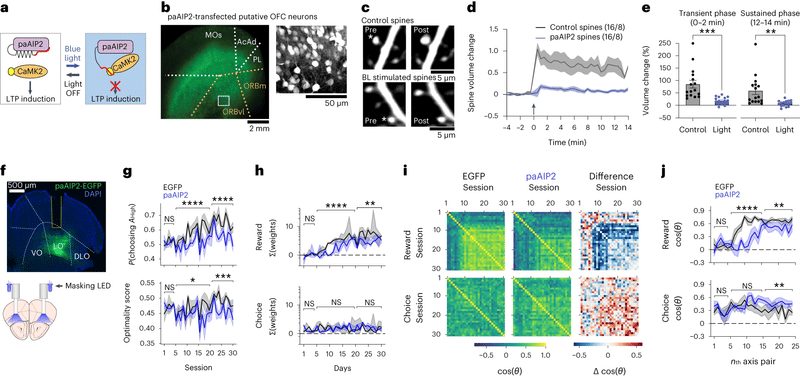
図4は、OFCの活動が行動価値を表象することを示している。DeepRLのRNNユニットの活動から、ΔQ(左と右の価値の違い)、Qch(前の選択の価値)、ΣQ(価値の合計)をデコーディングするモデルを作成すると、高い精度で予測することができた(図4A)。同様のことがマウスでも可能か調べるために、OFCの神経活動を2光子顕微鏡と内視鏡レンズを用いて計測した(図4B、C)。OFCの集団神経活動からの行動価値のデコーディング精度は偶然には起こらない程度に高く(図4D)、OFCの活動が行動価値と相関することが示された。

図5は、OFCの活動が早い強化学習に必要であることを示している。DeepRLのRNNのユニットの活動の一部を抑制すると、報酬や選択の履歴依存性が低下することが分かった(図5A)。大脳皮質の抑制性介在神経の一種であるPV神経の活動を、赤色励起の光遺伝学ツールであるChrimsonRを用いて活性化することで、OFCの両側の興奮性神経の抑制を行った(図5B)。マウスにおいてもOFCの活動抑制によって報酬履歴に依存した行動が抑制され(図5C)、OFCの活動が早い強化学習に必要であることが示された。

図7は、OFCがメタ強化学習を行っている過程での行動価値表現の変化を調べている。早い強化学習(OFCの神経ダイナミクス)が遅い強化学習(OFCの神経可塑性)によってどのように変化するかを調べるために、日をまたいで同じ神経集団のイメージングを行った(図7A)。AIとBI双方でほとんどの行動価値関連の変数のデコーディング精度はトレーニングに伴い上昇し(図7B)、デコーディング精度と方策の報酬依存性の間には正の相関があった(図7C)。ただし、ΔQは直接的に意思決定に関与する変数であるはずなのにもかかわらず、OFCのΔQのデコーディング精度がトレーニングで上昇しない点は気になる。異なる学習段階での神経表象の近さを測るために、行動価値のデコーディング時の各細胞の重みのパラメーター空間内でのコサイン類似度を定義した。AIとBIの双方で行動価値の神経表象はトレーニングに伴い安定化した(図7D)。最後に神経活動の安定化と行動の安定化の関係を比べると、行動価値の表象の近さと方策の報酬依存性の近さの間に正の相関があることが分かった(図7E)。これらの結果は、神経活動の行動価値表象と方策の双方がトレーニングに伴い安定化し、過去の履歴を上手に使うことでより良い意思決定を行えるようになることを示唆している。

他に、図3ではトライアルごとの(早い)強化学習にはOFCのCaMK2依存性シナプス可塑性が必要ないこと、図6では履歴に依存しない行動のバイアスにはOFCが関与しないことが示されている。
Discussion
再帰的な神経活動ダイナミクスと長期的なシナプス可塑性は神経回路における2つの記憶機構である。AI分野ではこれらを用いたメタ強化学習が変化する環境に順応したエージェントの作成に重要なことが分かっているが、本研究は、OFCがCaMK2依存性可塑性によって遅い強化学習を、活動ダイナミクスによって早い強化学習を実装していることを実験的に示した点で意義がある。この研究は、動物が生活の中でシナプスの重みとして経験を蓄積し、新しい環境に順応するためにこれらの普遍的な知見を活用して脳内での再帰的ネットワークによる意思決定を行っていることを示唆している。
AIとBIを組み合わせて生物学的に重要な問いを解明するというアプローチのお手本のような見事な研究であると感じた。ただし、行動を説明する他のモデルや脳部位間の比較は行っておらず、他の計算論的モデルによっても現象を説明できる可能性、また他の脳部位で同じ実験をやっても同様の結果が得られる可能性は否定できないことに注意する必要がある。ディスカッションでも述べられているが、長年研究されてきた他の脳領域での強化学習の実装とOFCのメタ強化学習の実装との関係がどのようになっているかは今後の課題である。また、ここでは神経活動のダイナミクス(数100ミリ秒から数10秒)とシナプス可塑性(数10分から一生?)の2つのタイムスケールの生物学的実装を調べているが、実際生物が環境に順応して行動していくためにはより多階層の強化学習が必要であると考えられる。それらの階層はどのように生物学的に実装されているのか、それらのタイムスケールの違う階層間をどのように情報は受け渡されるのかといった点について、今後研究が進み俯瞰できるようになると面白い。
参考文献
本論文を著者自身が紹介したポッドキャスト
#68 Foraging under the Sun - NeuroRadio
強化学習
https://t.co/s2TqfNRVI6
A2C
[1602.01783] Asynchronous Methods for Deep Reinforcement Learning (arxiv.org)
メタ強化学習
Prefrontal cortex as a meta-reinforcement learning system | Nature Neuroscience
Reinforcement Learning, Fast and Slow: Trends in Cognitive Sciences (cell.com)
同じ第一著者による関連研究
Area-specificity and plasticity of history-dependent value coding during learning
Context-dependent persistency as a coding mechanism for robust and widely distributed value coding
Exponential history integration with diverse temporal scales in retrosplenial cortex supports hyperbolic behavior | Science Advances
OFC
前頭眼窩野 - 脳科学辞典 (neuroinf.jp)
ピーター・フランクルは12か国語を話す数学者・大道芸人。多言語習得は、既存の学習経験を活用する「学習則の学習」により、第2、第3外国語は学びやすい。最新研究では、マウスとAIの強化学習を比較し、眼窩前頭皮質がメタ強化学習に関与することを示した。再帰的神経活動と長期的シナプス可塑性が、環境適応のための意思決定に重要。
サムネイル画像の出典:https://www.nature.com/articles/s41593-023-01485-3