
Azure Databricksを使ってみる

データ分析ソリューションAzure Databricksを軽く使ってみました。
Azure Databricksとは
Azureに最適化されたData Analytics プラットフォームです。 Azure Databricks により、データ集中型アプリケーションを開発するためAzure Databricks SQL Analytics と Azure Databricks ワークスペースの2つの環境が提供されています。
今回紹介するのはAzure Databricks ワークスペースです。
Azure Databricks サービスを作成する
Azure portal からAzure Databricksサービスを作成します。
必要な情報を入力して作成。
作成後、ワークスペースを起動します

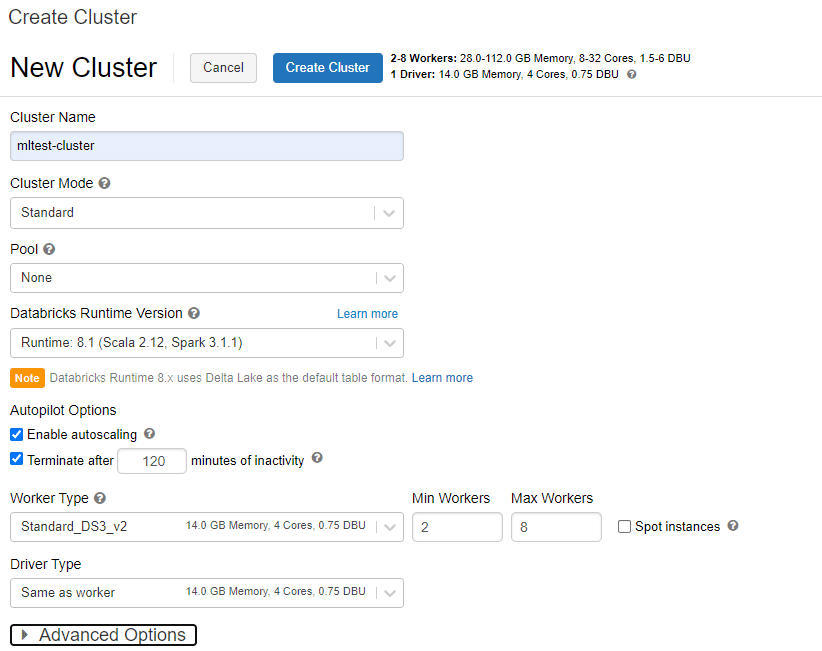
Spark クラスターを作成する
分析時に利用するクラスターを作成します。
ワークスペースから「New Cluster」を選択します。

必要な情報を入力して作成。
今回はデフォルトで作成しました。
Notebookの作成
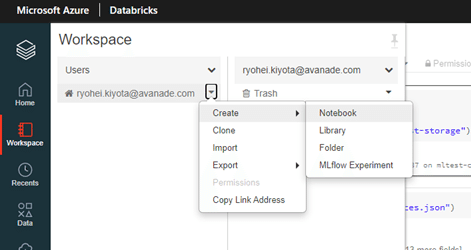
次に実際に作業するNotebookを作成します。
「Workspace」→「Users」→「Create」→「Notebook」
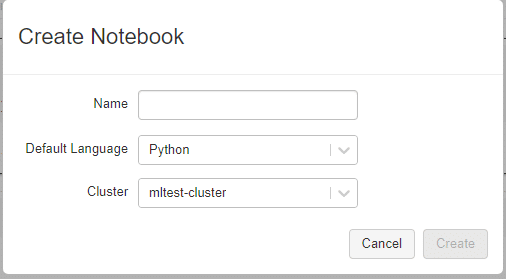
言語はPythonで作成します。
データを取り込む
Azure Data Lake Storage Gen2 からデータを取り込みます。
※Azure Data Lake Storage Gen2アカウントは別途作成
データを取り込むにはまず、接続情報などの設定が必要です。
今回はシークレットを使って接続することにしました。
まずは、Databricksでシークレットの作成を行います。
以下のURLにアクセスします。
「https://<databricks-instance>#secrets/createScope」
<databricks-instance>は自身のDatabricksのインスタンスを入力します。
アクセスするとこんな画面に
この画面はワークスペースからアクセスできないみたいなので、直接URLを入力する必要があります。
Manageは「All Users」を選択します。「Creator」はAzure Databricks Premium プランが必要なようです。

作成したシークレットの名前をメモしておきます。
シークレットの一覧を見るにはCLIを利用する必要があり、手間がかかるので、必ずメモしておきます。
また、KeyVaultの情報が必要なため、事前にAzure Data Lake Storage Gen2のアクセスキーを格納したKeyVaultを作成しておきます。
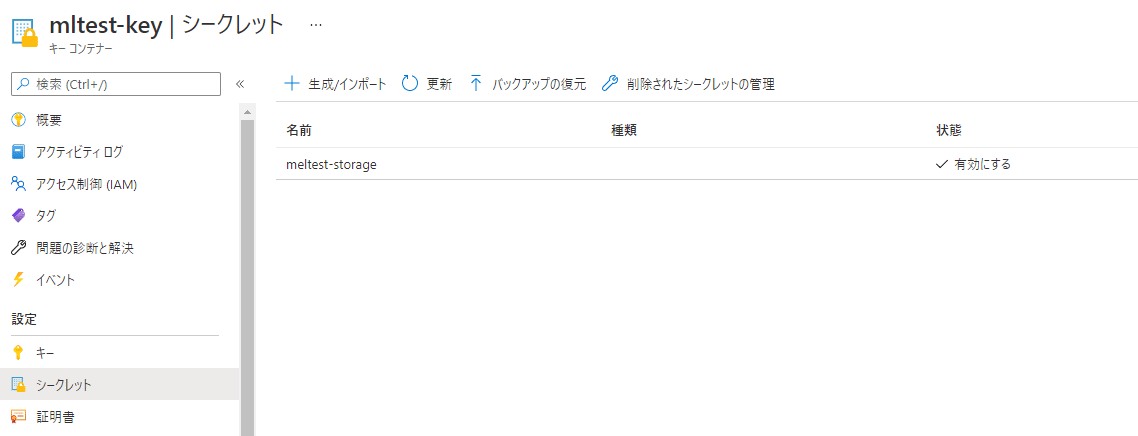
以上でシークレットの作成は完了です。
実際にデータの取り込みを行っていきます。
①資格情報の設定
Notebookを表示して以下を実行
spark.conf.set(
"fs.azure.account.key.gen2mltest.dfs.core.windows.net",
dbutils.secrets.get(scope="mltest-secretscope",key="meltest-storage"))mltest-secretscopeはDatabricksのシークレット名
meltest-storageはKeyVaultのAzure Data Lake Storage Gen2のアクセスキー
②サンプルデータのダウンロード
自分で格納したデータの分析も可能ですが、まずはサンプルデータをダウンロードして、それを表示してみます。
クラスターのtmpフォルダにサンプルデータをダウンロード
%sh wget -P /tmp https://raw.githubusercontent.com/Azure/usql/master/Examples/Samples/Data/json/radiowebsite/small_radio_json.jsonダウンロードしたサンプルデータをAzure Data Lake Storage Gen2にコピー
mltest@gen2mltest部分はAzure Data Lake Storage Gen2の「コンテナ名@ストレージアカウント名」です
dbutils.fs.cp("file:///tmp/small_radio_json.json", "abfss://mltest@gen2mltest.dfs.core.windows.net/")③データ取り込みと表示
ダウンロードしたサンプルデータを表示してみます。
次のコマンドでデータを取り込み&表示
df = spark.read.json("abfss://mltest@gen2mltest.dfs.core.windows.net/small_radio_json.json")
df.show()す実行すると以下のような結果になります。

無事データが表示できました。
コマンドのsmall_radio_json.json部分を変更することで、他のファイルの読み込みも可能です。
④データの編集
表示したデータをいろいろいじってみます。
表示カラムを絞る
specificColumnsDf = df.select("firstname", "lastname", "gender", "location", "level")
specificColumnsDf.show()
カラム名の変更
level → subscription_type
renamedColumnsDF = specificColumnsDf.withColumnRenamed("level", "subscription_type")
renamedColumnsDF.show()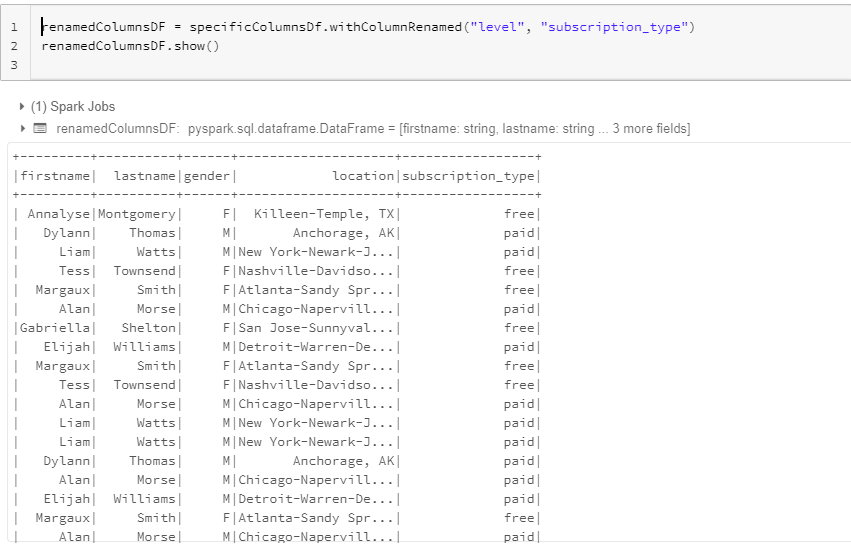
新規ファイルとして保存
renamedColumnsDF.write.json("abfss://mltest@gen2mltest.dfs.core.windows.net/small_radio_json123.json")という感じで、非常に簡単にデータ操作が可能です。
最後に
コマンド操作で簡単にデータ表示や編集が可能なDatabricksですが、今回使ってみた限りではデータの内容や格納場所をある程度把握していないと、活用するのは難しいのかなと感じました。
そのあたりは前回紹介したPurviewを併用するのがいいのかな?
https://note.com/avakansai/n/n31b90338d303
以上、Azure Databricksの紹介でした。
アバナード 清田 涼平
記事内容に関するご指摘や、その他何かございましたら下記に連絡ください
ryohei.kiyota(@)avanade.com
この記事が気に入ったらサポートをしてみませんか?