
AWS Inf2によるモデル推論―コンパイルから速度比較まで

こんにちは。メディア研究開発センター(通称M研)の田口です。今回はAWSのInf2インスタンスを使ったモデル推論の方法を紹介します。
AWS Inf2とは
AWS Inf2とは、AWSが提供している推論特化型のInf1インスタンスの後継です。
Inf2インスタンスは、第2世代のAWS InferentiaアクセラレーターであるAWS Inferentia2を搭載しています。Inf1 インスタンスと比較し、Inf2インスタンスは、最大3倍のコンピューティングパフォーマンス、最大4倍のアクセラレーターメモリ、最大4倍のスループット、10分の1 以下の低レイテンシーのパフォーマンス向上を実現します。
Inf1については下記のテックブログで、BERTベースの系列ラベリングモデルを例にモデル推論の流れを説明しています。
M研内ではさまざまなタスクで事前学習済みモデルを利用した推論を行っています。リアルタイムで処理したい場合はGPUインスタンスを使いたい、でもコストが…という際の選択肢としてInf1も含めてインスタンスの選定をしてきました。昨年12月に東京リージョンでも利用可能になったため、直近検証した内容を共有していきます。
Inf2の検証を行っている関連記事
本題に入る前に日本語でInf2の検証をしている記事を2つほど紹介します。まずはマネーフォワードさんのテックブログで、LLM(Llama2)のInf2上での推論の検証結果をまとめています。
もう一つが、RevCommさんのテックブログです。こちらはLLMではなく、自社の音声感情認識モデルをInf2インスタンスを使うことでGPUインスタンス上よりも高速かつ安価に推論できたと報告しています。
日本語記事以外では、Hugging FaceのブログでBERT系のモデルとVision TransformerをInf1およびGPUインスタンスで比較した際のベンチマーク結果がまとめられています。
この記事には何が書いてあるか?
上述の記事3本でも十分Inf2について知れますが、この記事の特徴はこちらの3点です。
Inf2インスタンス立ち上げ後からBERTモデル(具体的にはBERTベースの系列ラベリングモデル)のコンパイルまでの流れを説明
Hugging Faceのoptimum-neuronを用いたモデルコンパイルおよび推論のサンプルコードを提供
モデルコンパイル時のオプションごとの推論速度の比較
前置きが長くなってしまいましたが、さっそく本題に入っていきましょう。
そもそもInf1とInf2は何が違うのか?
ここではInf1インスタンスを触った事がある人向けに簡単にInf1とInf2の違いについて説明します。パフォーマンスの違いなどは公式ドキュメントや上述のテックブログを参考にしてもらうとして、一番の大きな違いはInf1とInf2はコンパイラが異なります。Inf1ではNeuronコンパイラを利用したのに対して、Inf2からはNeuronXコンパイラを使います。NeuronXコンパイラはInf2インスタンスに限らず、訓練特化型のインスタンスであるTrn1インスタンス上でも利用されます。
NeuronコンパイラおよびNeuronXコンパイラの違いは公式ドキュメントにわかりやすくまとまっています。torch-neuronはNeuronコンパイラ(Inf1)で、torch-neuronxはNeuronXコンパイラ(Inf2/Trn1)でPytorchのモデルを変換する際の比較表になっています。面白い違いとしては、NeuronコンパイラはTVMをフロントエンドとして利用し、NeuronXコンパイラはXLAをフロントエンドとして利用しています。

特筆すべき点としては、Inf1インスタンス用にコンパイルしたモデルはInf2との互換性がないという点です。そのため、既にInf1上で動いているモデルがある場合は、もとのモデルをNeuronXコンパイラを利用して再度コンパイルし直す必要があります(詳細はこちらを参照)。
Inf2インスタンス上でモデルをコンパイルする
ではさっそくInf2インスタンス上でモデルをコンパイルして動かしてみましょう。
インスタンスの作成
今回はPyTorchのモデルをコンパイルするため、AMIはDeep Learning AMI Neuron PyTorch 1.13 (Ubuntu 20.04)を選択してInf2(inf2.xlarge)インスタンスを起動します。
モデルのコンパイル
Inf2インスタンスにアクセスしたら所定のPyTorch環境を使えばすぐにモデルのコンパイルができます。今回は書籍「大規模言語モデル入門」がHugging Face Hub上で公開しているBERTの系列ラベリングモデルを利用します。そのため、モデルコンパイルを行う前に、依存ライブラリであるfugashiとunidic-liteのインストールも行います。transformersのバージョンは本記事執筆時点では4.37.2が最新版ですが、後ほど説明するoptimum-neuronライブラリの依存関係上4.36.2をインストールしています。
# Inf2用のPyTorch環境を使用
$ source /opt/aws_neuron_venv_pytorch/bin/activate
# Pythonのバージョンを確認
$ python -V
Python 3.8.10
# torch関連のバージョンを確認
$ pip freeze | grep torch
torch==1.13.1
torch-neuronx==1.13.1.1.13.0
torch-xla==1.13.1+torchneurond
torchvision==0.14.1
# 依存ライブラリをインストール
$ pip install -U transformers==4.36.2 fugashi unidic-lite
ライブラリのインストールが終わったら早速モデルのコンパイルを行いましょう。Inf2上でのモデルコンパイルは、以前のInf1上でのモデルコンパイルとほぼ変わりません。
from transformers import AutoTokenizer, AutoModelForTokenClassification
import torch_neuronx
model_dir = "llm-book/bert-base-japanese-v3-ner-wikipedia-dataset"
tokenizer = AutoTokenizer.from_pretrained(model_dir)
model = AutoModelForTokenClassification.from_pretrained(model_dir)
sample_input = "これはtrace時に使うためのダミーテキストです。"
# 入力の最大系列長を事前に指定する
max_length = 128
tokens = tokenizer(
sample_input,
padding="max_length",
max_length=max_length,
return_tensors="pt",
truncation=True,
)
example_input = (
tokens["input_ids"],
tokens["attention_mask"],
tokens["token_type_ids"],
)
# コンパイル
model_neuron = torch_neuronx.trace(model, example_input, strict=False)
model_neuron.save("bert_neuron.pt")
次はコンパイルしたモデルを読み込んで実際に推論をしてみましょう。
from transformers import AutoTokenizer, AutoConfig
import torch_neuronx
import torch
import numpy as np
model_dir = "llm-book/bert-base-japanese-v3-ner-wikipedia-dataset"
tokenizer = AutoTokenizer.from_pretrained(model_dir)
# configはラベルIDに紐づくラベル名を取得するために使用
config = AutoConfig.from_pretrained(model_dir)
# コンパイルしたモデルを読み込む
model = torch.jit.load("bert_neuron.pt")
# 解析対象のテキスト
input_text = "朝日新聞社東京本社は東京都中央区築地にあります。"
# 入力の最大系列長を事前に指定する (コンパイル時と同じ長さに設定する)
max_length = 128
tokens = tokenizer(
input_text,
padding="max_length",
max_length=max_length,
return_tensors="pt",
truncation=True,
)
example_input = (
tokens["input_ids"],
tokens["attention_mask"],
tokens["token_type_ids"],
)
# 各トークンごとの予測ラベルを出力
with torch.inference_mode():
logits = model(*example_input)["logits"]
pred = np.argmax(logits.detach().numpy(), axis=2)
# [CLS], [SEP]を除いた範囲でトークン・IDに該当するラベルを出力
for label, token in zip(pred[0][1:-1], tokenizer.tokenize(input_text)):
print(f"{token}\t{config.id2label[label]}")
"""
朝日 B-法人名
新聞 I-法人名
社 I-法人名
東京 B-施設名
本社 I-施設名
は O
東京 B-地名
都 I-地名
中央 I-地名
区 I-地名
築地 I-地名
に O
あり O
ます O
。 O
"""このようにモデルコンパイルおよび推論自体は簡単にできます。
optimum-neuronについて
先ほどのサンプルコードでは、モデルおよびトークナイザーを読み込み、入力の文字列をトークナイザーでテンソル化してモデルに入力してlogitsを取得して…といった処理をしました。しかし、transformersのモデルを使うのであれば、Pipeline APIを使えばもっと簡単に書けそうです。そこで、Inf2インスタンス上でもtransformersのAPIが利用できるoptimum-neuronライブラリを紹介します。
optimum-neuronは、昨年3月に最初のv0.0.1がリリースされ、当時はTrn1インスタンス上でtransfermersのTrainer APIによるモデル訓練の提供のみでした。その後、Inf1およびInf2へのモデルコンパイルにも対応し、記事執筆時点では以下の6タスクのパイプラインが利用できます。
・feature-extraction
・fill-mask
・text-classification
・token-classification
・question-answering
・zero-shot-classification
optimum-neuronのインストール方法
READMEにあるとおりpipでインストールできます。
# Inf2上で利用する場合はこちら
$ pip install optimum[neuronx]
# Inf1上で利用する場合はこちら
# $ pip install optimum[neuron]CLIによるモデルコンパイル
インストールしたらoptimum-cliコマンドでモデルのコンパイルができます。ここでは、先ほどと同じBERTの系列ラベリングモデルのモデルパスを指定し、バッチサイズ1、最大系列長128でモデルをコンパイルします。--atolは元のモデルの出力と、コンパイルしたモデルの絶対許容誤差です。系列ラベリングモデルの場合は、各トークンごとのlogitsの差分を見てバリデーションをしています(他タスクに関してはこちらを参照)。以下の設定では元モデルとコンパイル済みモデルとのlogitsの誤差が最大でも0.001以内に収まるかどうかを確認しています。
$ optimum-cli export neuron \
--model llm-book/bert-base-japanese-v3-ner-wikipedia-dataset \
--batch_size 1 \
--sequence_length 128 \
--atol 0.001 \
neuron_model/絶対許容誤差をもう少し厳しく0.0001に設定した場合は、モデルコンパイル終了時に誤差が設定値より大きいため、logitsの差分によるバリデーションが失敗していることがわかります。
$ optimum-cli export neuron \
--model llm-book/bert-base-japanese-v3-ner-wikipedia-dataset \
--batch_size 1 \
--sequence_length 128 \
--atol 0.0001 \
neuron_model/
# 中略
Validating bert-base-japanese-v3-ner-wikipedia-dataset model...
- Validating Neuron Model output "logits":
-[✓] (1, 128, 17) matches (1, 128, 17)
-[x] values not close enough, max diff: 0.0005397796630859375 (atol: 0.0001)
The maximum absolute difference between the output of the reference model and the Neuron exported model is not within the set tolerance 0.0001:
- logits: max diff = 0.0005397796630859375
The Neuronx export succeeded and the exported model was saved at: neuron_modelコンパイルコマンドを実行したら、保存先のディレクトリの中身を確認してみましょう。コンパイルしたモデルファイル(model.neuron)に加えて、モデルやトークナイザーのConfigファイルなどが保存されています。
$ ls neuron_model
config.json model.neuron special_tokens_map.json tokenizer_config.json vocab.txtパイプラインモードによる推論
optimum-cliによるモデルコンパイルも終わったので、次はtransformersのPipeline(ここでは系列ラベリング用のTokenClassificationPipelineを使用)を使った推論を行います。コンパイル済みのモデルを読み込む際にNeuronModelForTokenClassificationを使っている以外は通常と同じように書けます。詳細を知りたい方は公式ドキュメントを確認してください。
from transformers import AutoTokenizer, TokenClassificationPipeline
from optimum.neuron import NeuronModelForTokenClassification
from pprint import pprint
model_dir = "llm-book/bert-base-japanese-v3-ner-wikipedia-dataset"
tokenizer = AutoTokenizer.from_pretrained(model_dir)
# コンパイルした際の保存先のディレクトリを指定してモデルを読み込む
model = NeuronModelForTokenClassification.from_pretrained("./neuron_model/")
nlp = TokenClassificationPipeline(model=model, tokenizer=tokenizer, aggregation_strategy="simple")
pprint(nlp("朝日新聞社東京本社は東京都中央区築地にあります。"))
"""
[{'end': None,
'entity_group': '法人名',
'score': 0.9989485,
'start': None,
'word': '朝日 新聞 社'},
{'end': None,
'entity_group': '施設名',
'score': 0.9822972,
'start': None,
'word': '東京 本社'},
{'end': None,
'entity_group': '地名',
'score': 0.9987105,
'start': None,
'word': '東京 都 中央 区 築地'}]
"""これでoptimum-neuronの説明は以上になります。
各種インスタンス上での比較実験
ここからはInf2/Inf1/GPU/CPUインスタンス上での比較実験を行います。
実験設定
今回の実験では以下の4つのインスタンスを利用します。
inf2インスタンス:inf2.xlarge
inf1インスタンス:inf1.xlarge
GPUインスタンス:g5.xlarge
CPUインスタンス:c6in.xlarge

解析するテキストには「livedoorニュースコーパス」を使用し、訓練データの記事をpySBDで文分割してランダムに抽出した1万文でレイテンシーを計測します。先ほどのモデルコンパイルのサンプルコードにもあるように、今回は解析時の最大トークン数を128で統一しています。そのため、計測に用いる1万文は最大でも126トークン(BERTの[CLS]および[SEP]トークンを除いた上限)となっています。ベンチマークに用いる1万文の平均トークン数は35.2トークンです。
また、GPUインスタンスではTokenClassificationPipelineをそのまま
利用し、CPUインスタンスではoptimumライブラリを使用してONNX形式に
変換しています。
# ライブラリのインストール
$ pip install optimum[exporters,onnxruntime]
# ONNX形式に変換
$ optimum-cli export onnx \
--model llm-book/bert-base-japanese-v3-ner-wikipedia-dataset \
--batch_size 1 \
--sequence_length 128 \
--atol 0.001 \
onnx_model/変換したらoptimum-neuronの時と同じくモデルとトークナイザーを
読み込み、TokenClassificaitonPipelineで推論を行っています。
Inf1インスタンスについては、上述のInf2と同じ方法でモデルをコンパイルし、同じくTokenClassificaitonPipelineで推論を行っています。
実験では1万文を1文ずつ解析した際のレイテンシー(ミリ秒)を計測し、以下の4つの指標にまとめています。
90パーセンタイル値(p90)
95パーセンタイル値(p95)
99パーセンタイル値(p99)
平均(mean)
実験結果
さっそく計測結果を見ていきましょう。

99パーセンタイル値を見てみると、inf2上で推論した場合のレイテンシーはinf1の3倍で、g5と比較しても2.3倍、c6inより11.5倍速い推論が実現できていました。
inf1とg5を比較すると、g5はInf1と比べて1.3倍ほど速いです。しかし、コストに着目すると、1時間あたりのコストはg5の方がinf1よりも4.7倍ほど高いです。コストを抑えつつg5よりも多少高いレイテンシーを実現したいケースではinf1を使ってもいいかもしれません(モデルコンパイルなどの手間を許容できるかは要検討)。
また、g5のコストを2割程度抑えるだけで2.3倍の推論高速化が実現できるので、なるべくレイテンシーを短くしたいケースであればinf2を採用するといいと思います。
モデルコンパイルのオプションを複数試してみる
各インスタンスごとの比較が終わったのでこれでおしまい…としたいところですが、ここからはInf2で利用していたニューロン・コンパイラーをもう少し深堀りしていきます。
コンパイルオプションについて
詳細は公式ドキュメントを見ていただくとして、ここでは3つのオプションを紹介します。
--optlevel:最適化レベル。1〜3まで指定できます。デフォルトは2。1だとコンパイル時間が短くなる反面、コア部分の最適化のみに留まる。3だとコンパイル時間が長くなる反面、推論速度は向上します。
--auto-cast:"matmul"、"all"、”none"の3つから選択できます。デフォルトはmatmul。matmulではInf2上の行列演算エンジンを使用するFP32演算のみをキャストします(詳細はこちら)。allは名前のとおりすべてのFP32演算をキャストし、noneはキャストしません。デフォルトではBF16にキャストされますが、--auto-cast_typeオプションでデータ型を指定できます。
--model-type:inf1のコンパイルオプションにはなかったですが、inf2からはモデルタイプを指定して最適化がかけられます。オプションは"generic"、"transformer"、"unet-inference"の3つがサポートされています。
このうち、1の最適化レベルと3のモデルタイプを変えた際に推論速度がどの程度変わるかを見ていきます。
オプションごとのパフォーマンスの違い
最適化レベルとモデルタイプのコンパイルオプションを変えた際の推論速度がこちらです。先ほどの他インスタンスとの比較の際に用いたコンパイルオプションは最適化レベルが2、モデルタイプがgenericになります。
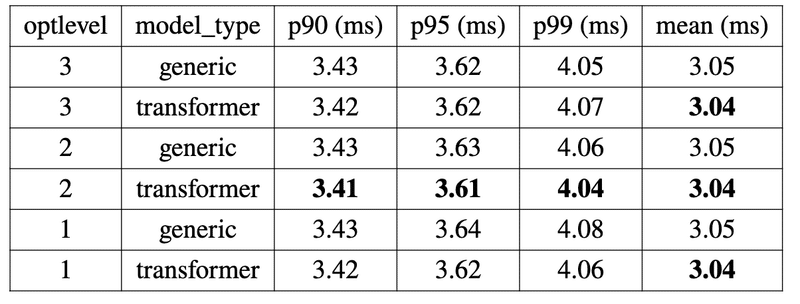
結果としては最適化レベル2、モデルタイプをtransformerとした場合の推論速度が最も速かったです。とはいえ他オプションと比較しても0.01〜0.04ミリ秒ほどの違いしかありませんでした。今回使用したBERTの系列ラベリングモデルは1.1億パラメータ程度なので、大きいパラメータサイズのモデルや、最大系列長が長くなるともう少し差が出るかもしれません。
おわりに
本記事では、AWSのInf2インスタンス上でのモデルコンパイルの流れや、optimum-neuronの使い方、推論速度の比較、コンパイルオプションの紹介をしました。前回のInf1の紹介記事を書いた頃と比べると、ライブラリも充実しているため非常に使いやすくなってきていると思います。この記事が少しでもInf2を使う際に参考になれば幸いです。ではまた。
(メディア研究開発センター・田口雄哉)