新型コロナ - 世界のデータ解析(4)- BCG

以下のBCGについての論文が出ていたのでチェックしてみた。
1. Motivation
Abstractの後半に
Linear mixed models revealed a significant effect of mandated BCG policies on the growth rate of both cases and deaths after controlling for median age, gross domestic product per capita, population density, population size, net migration rate, and various cultural dimensions (e.g., individualism).
(中央値年齢、1人あたりの国内総生産、人口密度、人口サイズ、純移動率、およびさまざまな文化的側面(個人主義など)を制御した後、線形混合モデルは、BCG義務付けポリシーの感染者数・死亡者数の成長率に対する有意な影響を明らかした 。)
とあるように、文化的な側面も考慮に入れている(著者らは心理学専攻)。成長率というのは、初めの件から30日間の日毎の増加をみているから。
Our analysis suggests that mandated BCG vaccination can be effective in the fight against COVID-19.
(我々の分析は、義務付けられたBCGワクチン接種はCOVID-19との闘いに効果的である可能性があることを示唆している)
で締め括り。この論文は、以前に書いたcovid-19に関するモデルを読む時の注意点という視点でいうと、純粋な statistical model (統計的モデル)で mechanistic model (機構的モデル) では無いので、私も検証できそう。
Supplementary Materialsとして国ごとの BCG policy status が 現在義務付けられている・過去に義務付けられていた・義務付けは無い、の3っつのカテゴリーに分けられているデータがあったので、covidの感染者数などのデータからBCGのカテゴリー分けを 機械(sklearn)ができるのか、試しにcheckしてみた。
2. Data & Manipulation
[1] 世界のcovid-19 data: owidの全て入ったデータ (ここのcomplete COVID-19 dataset)。8/2にdownloadした分。
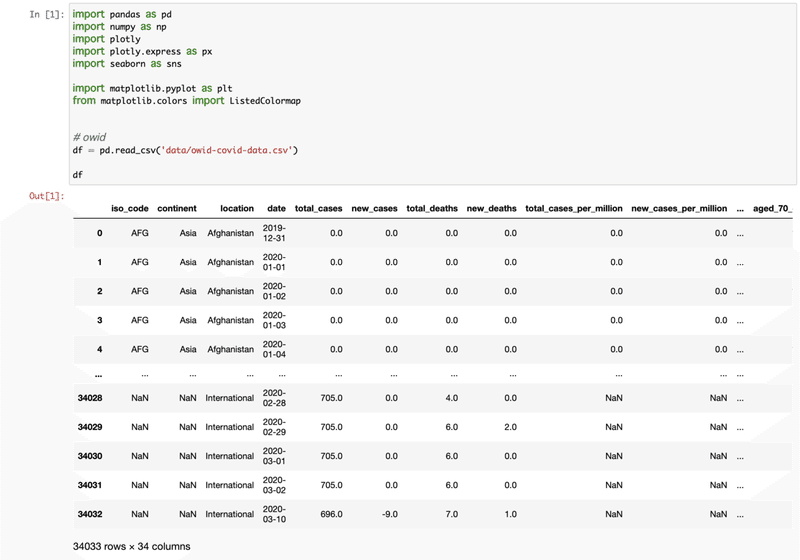
[2] いつものように必要の無いデータを消して、国別の最近の累計件数を使う。論文では初めのケースから同じ日数めのデータを使っているが、ここでは無視。男女分けされていた喫煙のデータを一つにする。ここで使用したデータは以下:
total_cases_per_million (100万人あたりの合計件数)
total_death_per_million (100万人あたりの合計死亡者数)
population_density (人口密度)
median_age (中央年齢値)
gdp_per_capita (一人あたりのGDP)
cardiovascdeath_rate (心血管死亡率)
diabetes_prevalence (糖尿病の有病率)
life_expectancy (平均寿命)
smokers (喫煙者の割合)
論文著者らが使用した文化的側面のデータはなし。
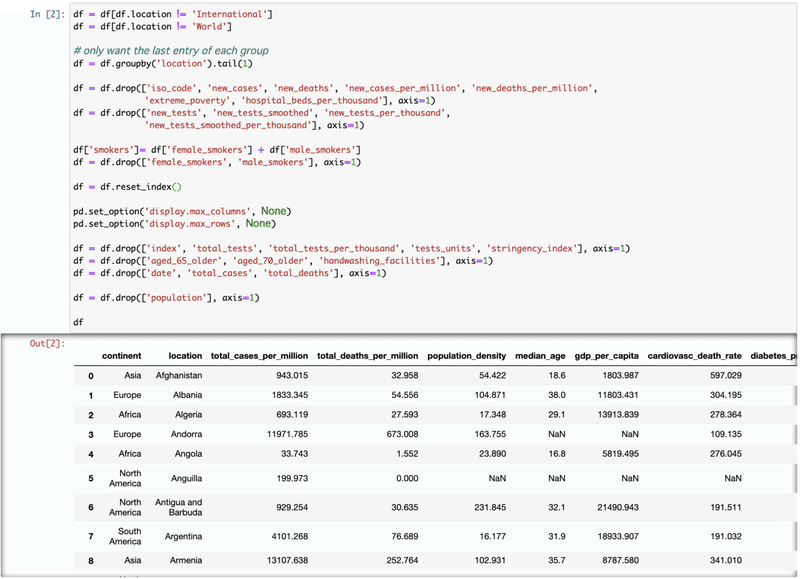
[3] BCG data: 上記BCG論文の supplementary material の Table S1からCountryとBCG policy statusを抽出した"bcg.csv"というfileを作る。statusを数字にしてsaveする。
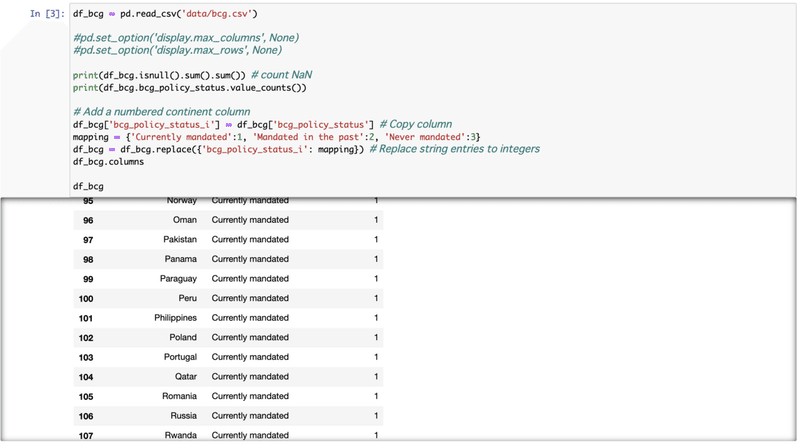
[4] owidのデータ(df)をbcgのデータ(bf_bcg)に merge させる 。bcgのデータの方が国名が少ないので、df_bcgをdfにするよりも make sense。indicator=Trueで国名がどちらにあるのか確認できる。全て"both"なので両方(df_bcgとdf)のデータにあることを確認。
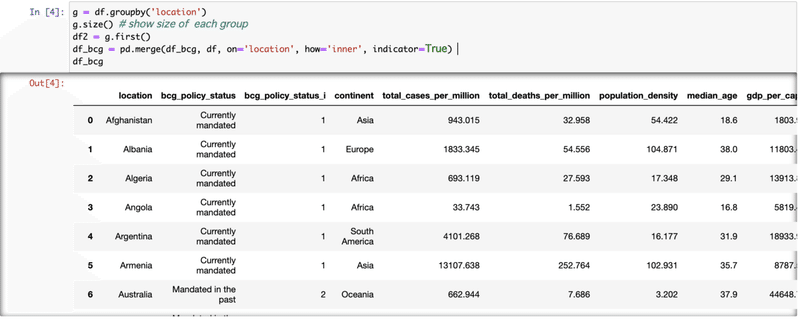
[5] plotして相関をチェック。
[6] NaNはdropし、国名の’location'をindexにする。
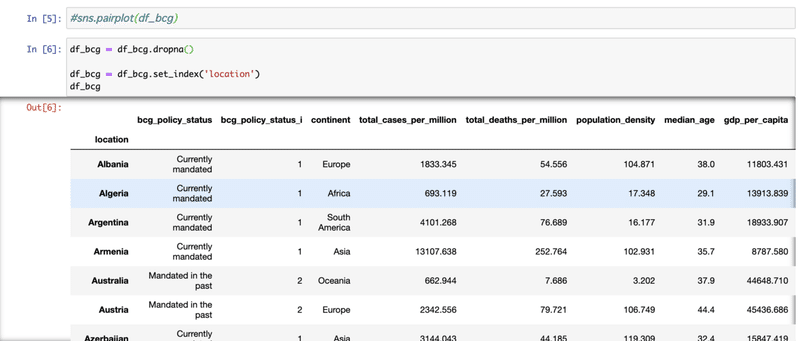
[6] target を数値化した BCG policy にし、訓練用(train)とテスト用(test) データに分ける。
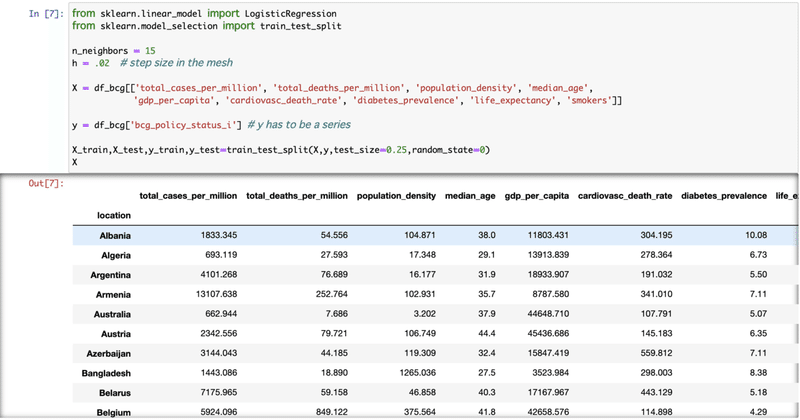
3. Models & Predictions
[8] preprocessingで standardization (標準化)する。
[9] ここからは kaggleの "Titanic Data Science Solutions" を参考に以下のmodelを試し比較してみる。
・Logistic Regression
・KNN or k-Nearest Neighbors
・Support Vector Machines
・Naive Bayes classifier
・Decision Tree
・Random Forrest
・Perceptron
・Artificial neural network
・RVM or Relevance Vector Machine

[10] 上の titanic の例では、Logistic Regression を使ってどのデータ(feature)が確率を増加(+)または減少(-)させるのかチェックしている。
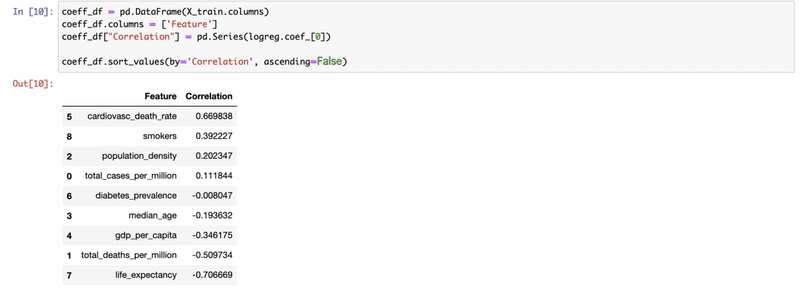
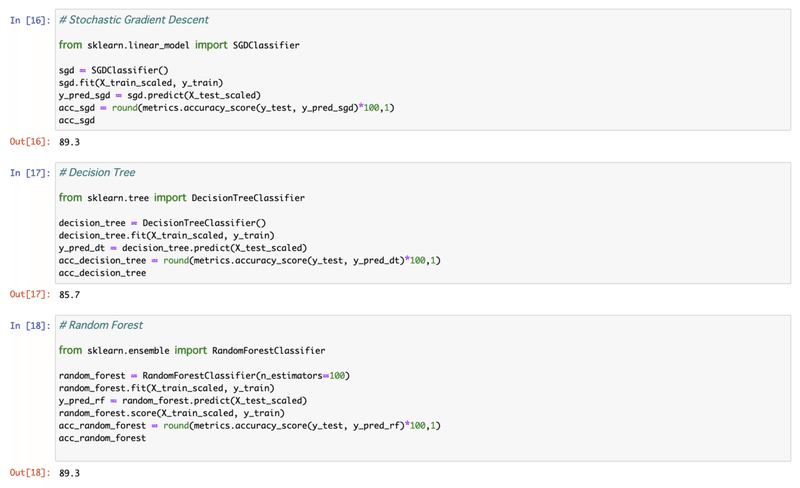
[11]-[18] 各モデルで推測し、accuracyをcheck。


4. Results
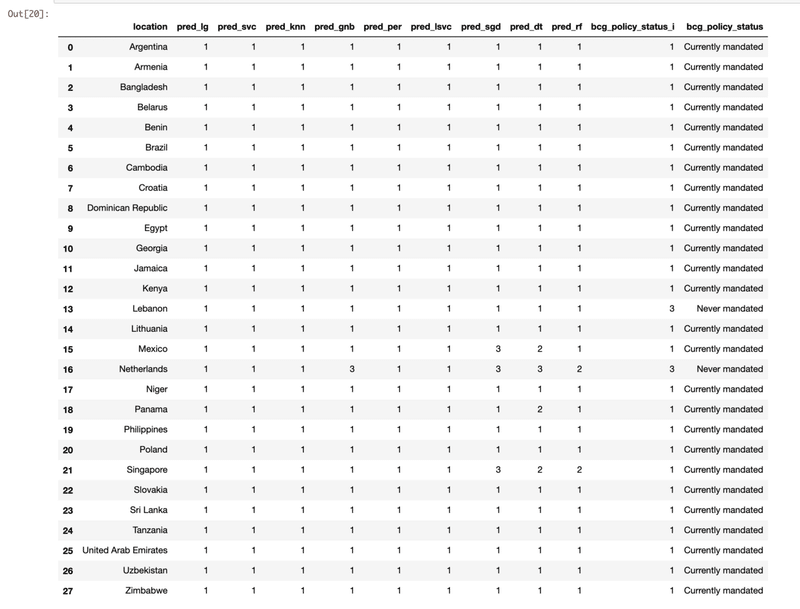
[19] accuracy scoreを書き出してみる。NaiveBaysが一番よかった。

[20] モデルの比較のために推測の結果を書き出してみる。オランダとレバノンが難しかったようだ。

5. Summary
著者らの解析のように、BCGのカテゴリーごとに件数・死亡者数を分ける解析をやってもよかったが、それだけだと面白く無いので、逆にBCGのカテゴリー分けを機械にやらせてみた。
どのモデルでも高いaccuracy でBCG statusを推定できたので改善は特に無い。BCGのデータはほとんどが「現在義務付られている」だったが、これがほぼ同じ割合だったら? また、以前のようにケースを同じ時間で割ったデータではどうなるか、など検討の余地はある。
BCGワクチンの株による差は?
この記事が気に入ったらサポートをしてみませんか?