新型コロナ - 世界のデータ解析(2)

前回の新型コロナの世界のデータ解析(1)の結論には「各国で最初の感染者から何日目と決めて累積数を求めた方が良い」と書いた。また疫学専門の知人からも分母に時間を入れましょう、という助言があったので今回それをしてみる。今回の結論:要データの確認。
まず必要データを探す前に、何を調べるのか・どんな図を作るのか(どのような形で結果を提示するのか)、考えイメージするところから始める。
今回は、
・武漢からの距離
・感染者数を人口だけではなく時間でも割る
・その変移をみる
と設定して、まずは30日ごとの感染者数の計を集めてみる。1週間ごとに比べ、分割が多くなく人間でも扱える(→目で確認できる)レベルなので。
データ解析するときは
・単純→複雑 (simple → complex)
・概要→詳細
を意識して進めること。
The devil is in the detail.
初めから変数が多いと
・どこに注目すべきか・どこに進むべきかわからなくなる
・bugも見つけにくくなる
気をつけましょう。
1. Data
データはOur World in Data (owid)のGitHubから全てのデータが入ったファイル"Download our complete COVID-19 dataset"のCSVをdownloadした。国ごとの緯度・経度のデータは前回作成したものを読む。
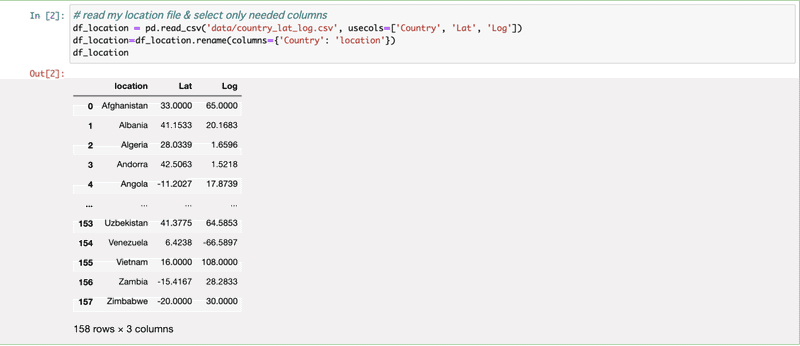
[1] owidのファイルは全てのデータが入っているので、中身をチェックしたあと必要なデータだけ集める。今回は国名とtotal_cases_per_million。
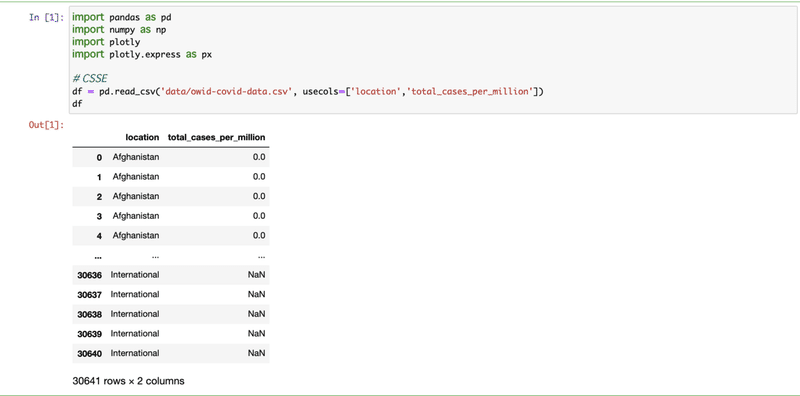
[2] 前回作った(csseデータから各国に複数あった場合の地域データを除き都市部においた)国ごとの緯度・経度データ。
2. Data Manipulation
データ解析の半分以上はデータの整形のようです。特にpythonは可視化ツールが充実しているので図にするのは簡単です。
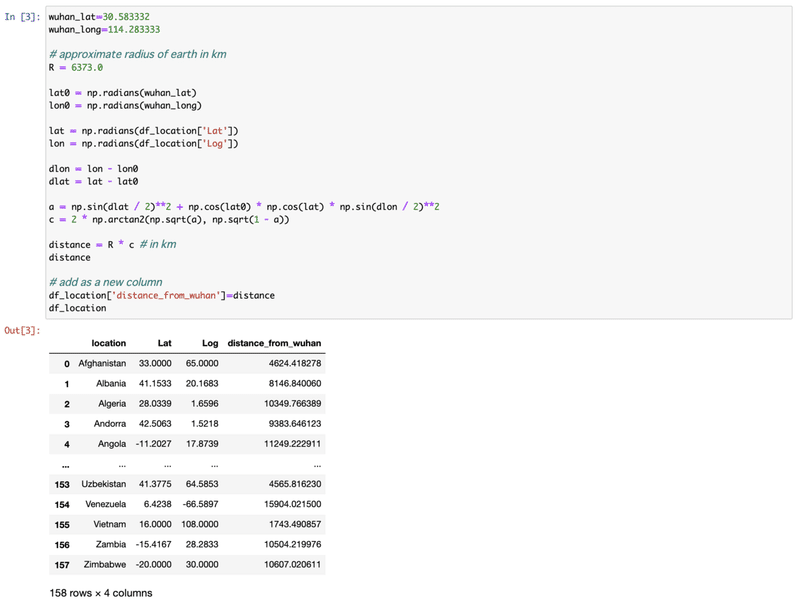
[3] 前回と同じ、武漢からの距離の計算。
[4] owidのデータのrowには必要のないInternationalとかWorldとかいう項目があったので使わないものは取り除く。NaNも除く。
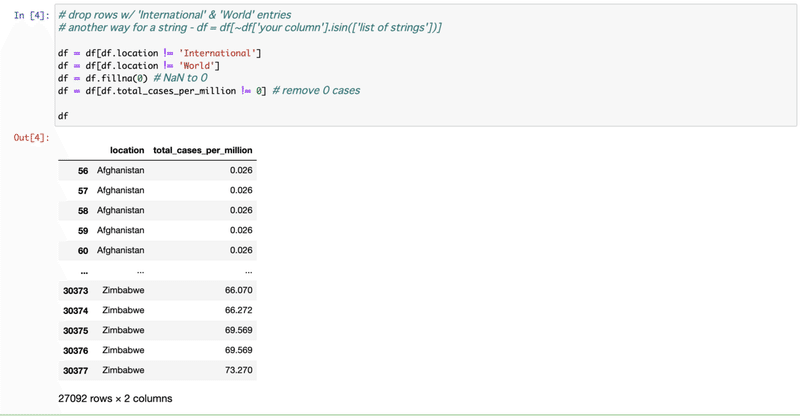
[5] [6] groupbyで国ごとにグループを作ってチェック。
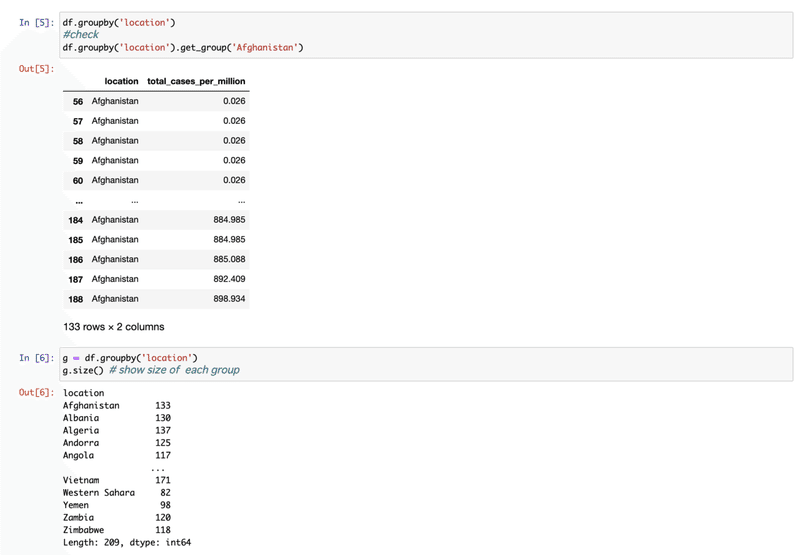
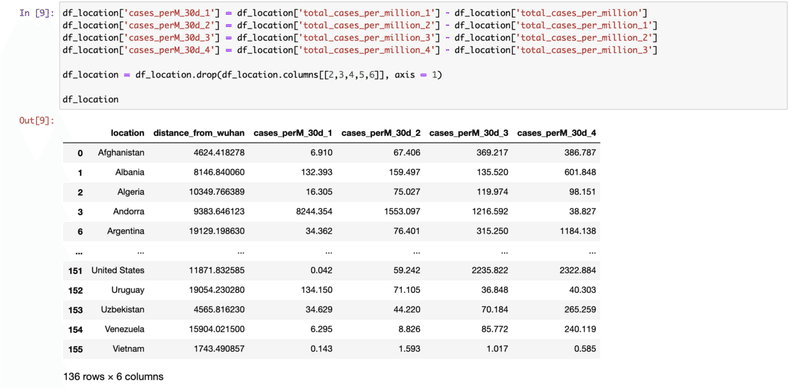
[7] グループした国ごとの30日目のデータはg.cumcount==30で読める(Ref.)。そのデータをdictionary、dに入れる。30, 60, 90,... 日目と読みたいのでfor loopで回す。n日目に抽出したデータを元のdf(ここではlocationデータを持っているdf_locationとした)の国名と比較しその国名のrowに描きたい(on='location')のでmergeを使う。mergeで、dictionaryのn日ごとのデータをcolumnとして足していき、またsuffixを指定することでcolumnの名前にi番を足している。
range(5)としたのは各国の初日の違いにより、6にするとデータのない国が多くなったので。今回(simple analysis)はとりあえず5(150日まで)として進めます。
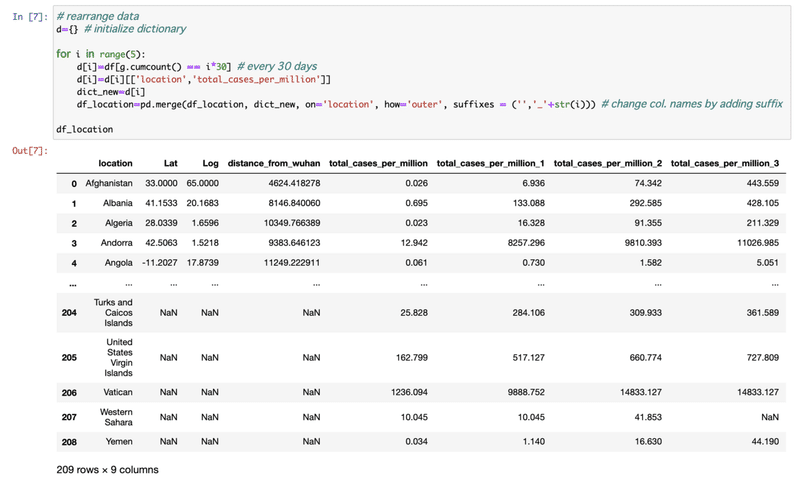
[8] データの簡素化。NaNのデータや緯度・経度のデータは消す。
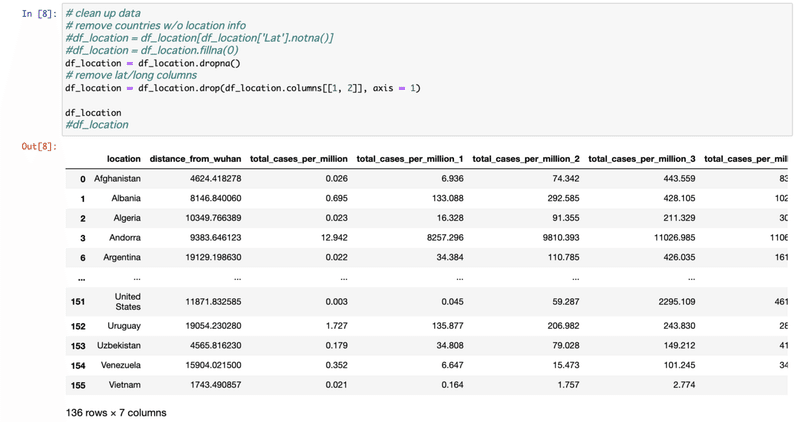
[9] 上のtotal_cases_per_million_nというデータはn日目の累計データなのでその間のデータを隣から引いて求め、名前も変える。累計データを消す。
3. Plot
ここからは前回やここと同様にしてplotly.express.scatterやseaborn.regplotで図にしてpillowでanimationにする。
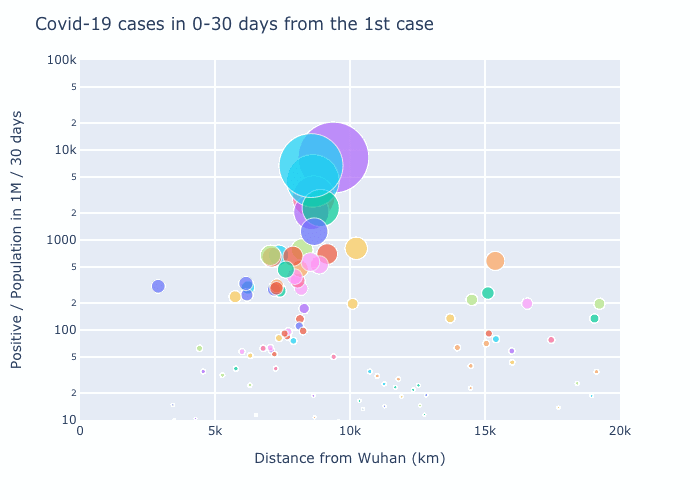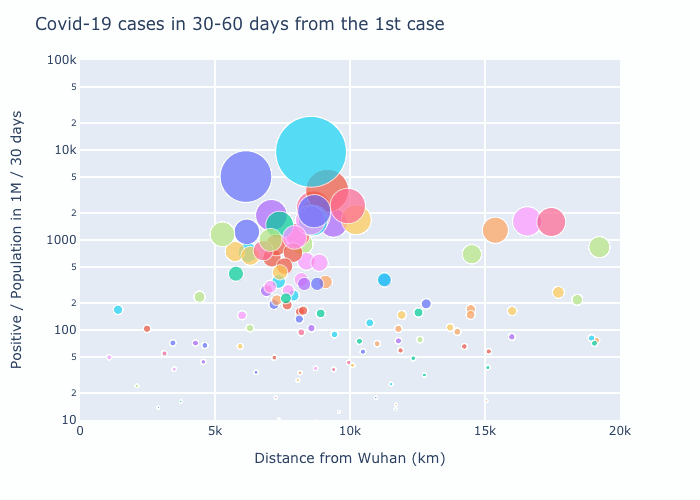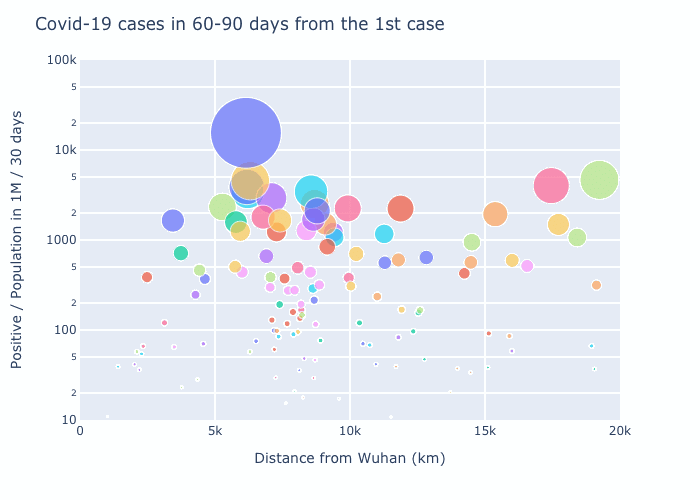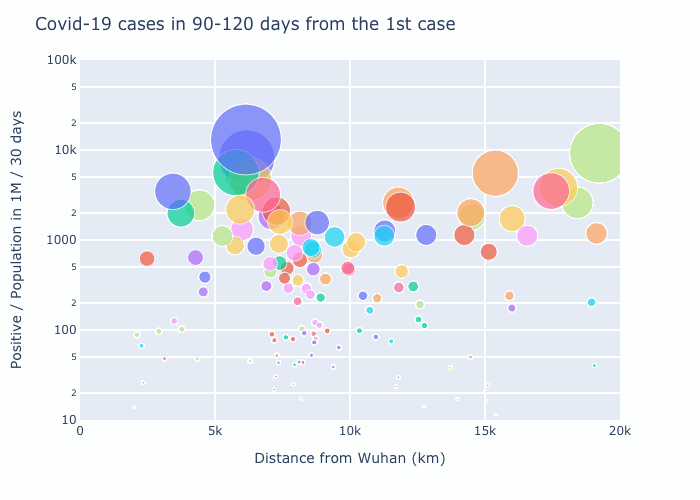
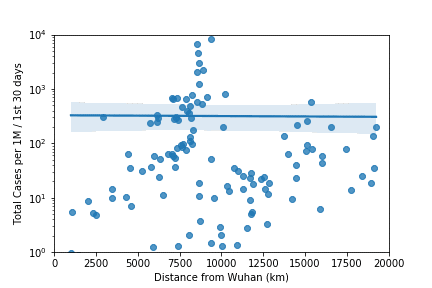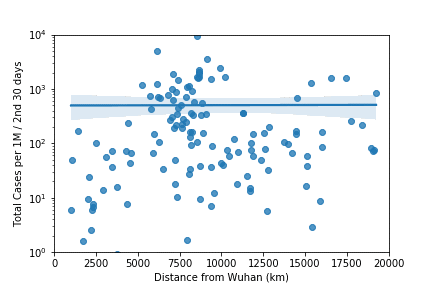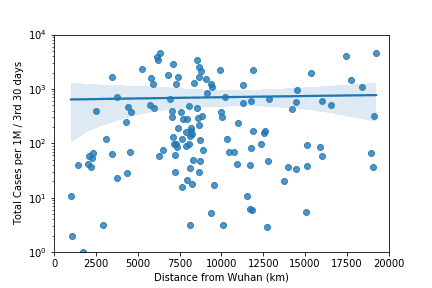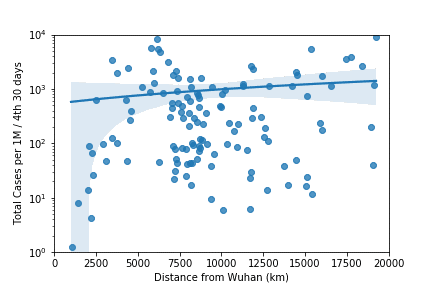
4. Observation
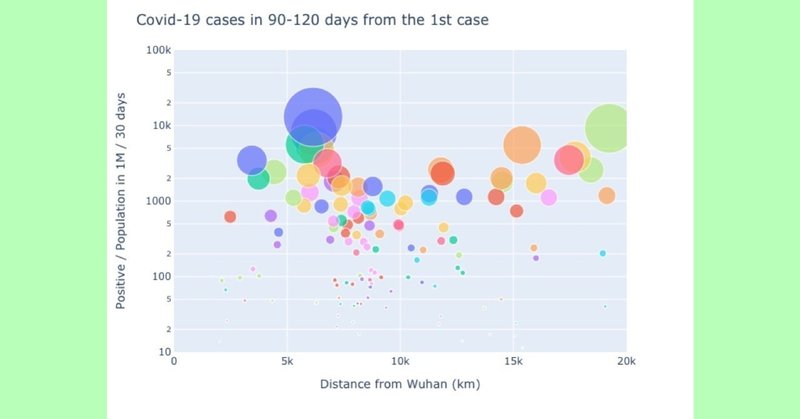
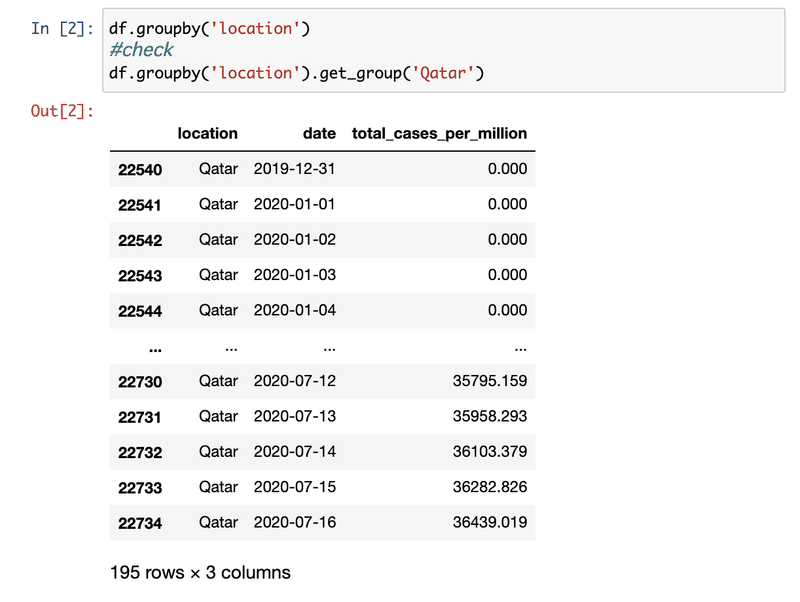
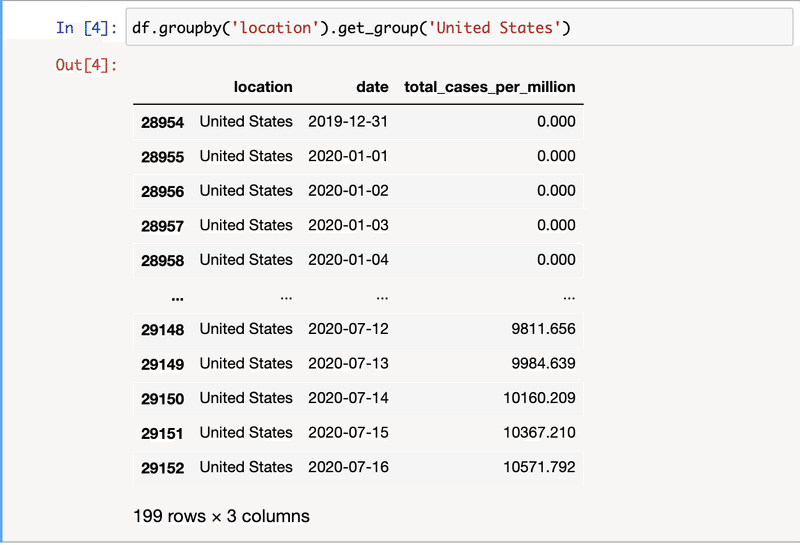
初めの30日で感染者数の多い7.5Mm辺りはヨーロッパを表す。4期目の2.5Mm以下は日本・韓国等のアジア諸国。武漢より一番遠いのは南米で4期目の図で増えているのがわかる。ただ4期目の6Mm辺りで一番多いのはQatar、Bahrainなどのアラブ諸国となっている。owidのこのplotでは人口1M辺り一番多いのはアメリカなので何かおかしい。
元データをチェックしてみると以下のようになり、7/16のデータでもUSの方が少ない。両方ともowidのデータだが、データが合わないようだ。
次回はそれを検証する。もしかしたら他にもbugがあるかもしれない。整合性が取れないところを見つけるのは良いことだ。
5. Summary
交差免疫というアイデアを元に、各国の武漢からの距離とその国の最初の感染者確認の日から30日ごとの感染者数を求めた。
相関性の詳しい解析をする前に、データの確認が必要とわかった。
この記事が気に入ったらサポートをしてみませんか?