
[Python]疾病分類別の医療費データを1904次元から2次元に圧縮してみた:PCA, UMAPによる次元削減

はじめに
こんにちは、機械学習勉強中のあおじるです。
以前の記事で、性別・年齢階級別の診療種別ごとの160次元の医療費データを次元削減(次元圧縮)の手法を使って2次元に圧縮してみました。
今回は、疾病分類も加えてさらに次元を上げた医療費データを2次元に圧縮してみます。
言語はPython、環境はGoogle Colaboratoryを使用しました。
使用するデータ
データは、前回の記事でも利用した全国健康保険協会(協会けんぽ)の加入者基本情報、医療費基本情報を使用します。
加入者基本情報:
年月・都道府県・適用区分・被保険者被扶養者区分・性別・年齢階級別の加入者数医療費基本情報:
年月・都道府県・被保険者被扶養者区分・性別・年齢階級・診療種別・疾病分類別のレセプト統計の数値:件数、日数、点数、点数(調剤を含む)
今回は、このうち、年月・都道府県・性別・年齢階級・疾病分類別の診療種別ごとの件数、日数、点数、点数(調剤を含む)を用います。
(それぞれの項目内容の説明はこちらにあります。)
疾病分類は、「社会保険表章用疾病分類」という4桁の分類コードですが、細かすぎると扱いにくいので、今回は4桁のうちの上2桁を使うことにします。
「社会保険表章用疾病分類」の上2桁
・01:感染症及び寄生虫症
・02:新生物
・03:血液及び造血器の疾患並びに免疫機構の障害
・04:内分泌,栄養及び代謝疾患
・05:精神及び行動の障害
・06:神経系の疾患
・07:眼及び付属器の疾患
・08:耳及び乳様突起の疾患
・09:循環器系の疾患
・10:呼吸器系の疾患
・11:消化器系の疾患
・12:皮膚及び皮下組織の疾患
・13:筋骨格系及び結合組織の疾患
・14:腎尿路生殖器系の疾患
・15:妊娠,分娩及び産じょく
・16:周産期に発生した病態
・17:先天奇形,変形及び染色体異常
・18:症状,徴候及び異常臨床所見・異常検査所見で他に分類されないもの
・19:損傷,中毒及びその他の外因の影響
・22:特殊目的用コード
データの加工
加入者基本情報は、年度別、都道府県ごとに集計します。
# 加入者基本情報の読み込み
import pandas as pd
df_P = pd.read_csv('./加入者基本情報.csv', encoding='shift_jis')
print(df_P.shape)
# (501319, 7)
# 年月、都道府県、性、年齢階級別集計
df_ymtsn_P = df_P.iloc[:,[0,1,4,5,6]]
col_names = ['ym', 't', 's', 'n', 'P']
df_ymtsn_P.set_axis(col_names, axis='columns', inplace=True)
df_ymtsn_P = df_ymtsn_P.groupby(['ym', 't', 's', 'n'], as_index=False).sum()
print(df_ymtsn_P.shape)
# (90240, 6)
# 年度追加
df_ymtsn_P['y'] = df_ymtsn_P['ym'] // 100
df_ymtsn_P['y'] = df_ymtsn_P['y'].where(df_ymtsn_P['ym'] % 100 >= 4, df_ymtsn_P['y']-1)
print(df_ymtsn_P.shape)
# (90240, 6)
# 年度集計
df_ytsn_P = df_ymtsn_P.loc[:,['y','t','s','n','P']]
df_ytsn_P = df_ytsn_P.groupby(['y','t','s','n'], as_index=False).sum()
print(df_ytsn_P.shape)
# (7520, 5)$$
\def\arraystretch{1.5}
\begin{array}{c:c:c:c|c}
\textsf{y} & \textsf{t} & \textsf{s} & \textsf{n} & \textsf{P} \\ \hline
2010 & 1 & 1 & 1 & {} \\
2010 & 1 & 1 & 2 & {} \\
\vdots & \vdots & \vdots & \vdots & \vdots \\
2019 & 47 & 2 & 8 & {}
\end{array}
$$
医療費基本情報は、「疾病分類コード」を文字列型で読み込みます。
また、医療費基本情報の「疾病分類コード」は年度によって形式が多少異なっているようですので、そろえておきます。疾病分類の「不明」がNull(空白)となっている年度とスペースとなっている年度がありますので、どちらも「9999」で統一します。また、0始まりのコード(「0101」等)が3桁(「101」等)で入っている場合がありますので、0埋めの4桁(「0101」等)に統一します。
# 医療費基本情報の読み込み
df_X = pd.read_csv('./医療費基本情報.csv', encoding='shift_jis',
dtype={'疾病分類コード': str})
# 疾病分類コードを4桁に統一
df_X['疾病分類コード'] = df_X['疾病分類コード'].fillna('9999') \
.str.replace(' ', '9999') \
.str.zfill(4)
# 年月、都道府県、性、年齢階級、診療種別、疾病分類コード別集計
df_ymtsnkd_X = df_X.iloc[:,[0,1,3,4,5,6,7,8,9,10]]
col_names = ['ym', 't', 's', 'n', 'k', 'd', 'Ken', 'Nit', 'Ten', 'Ten2']
df_ymtsnkd_X.set_axis(col_names, axis='columns', inplace=True)
print(df_ymtsnkd_X.shape)
# (22966480, 10)
# 年度追加
df_ymtsnkd_X['y'] = df_ymtsnkd_X['ym'] // 100
df_ymtsnkd_X['y'] = df_ymtsnkd_X['y'].where(df_ymtsnkd_X['ym'] % 100 >= 4, df_ymtsnkd_X['y']-1)
print(df_ymtsnkd_X.shape)
# (22966480, 11)
# 年度集計
df_ytsnkd_X = df_ymtsnkd_X.loc[:,['y','t','s','n','k','d','Ken','Nit','Ten','Ten2']]
df_ytsnkd_X = df_ytsnkd_X.groupby(['y','t','s','n','k','d'], as_index=False).sum()
print(df_ytsnkd_X.shape)
# (1493069, 10)$$
\def\arraystretch{1.5}
\begin{array}{c:c:c:c:c:c|c:c:c:c}
\textsf{y} & \textsf{t} & \textsf{s} & \textsf{n} & \textsf{k} & \textsf{d} & \textsf{Ken} & \textsf{Nit} & \textsf{Ten} & \textsf{Ten2} \\ \hline
2010 & 1 & 1 & 1 & 1 & 0101 & {} & {} & {} & {}\\
2010 & 1 & 1 & 1 & 1 & 0102 & {} & {} & {} & {} \\
\vdots & \vdots & \vdots & \vdots & \vdots & \vdots & \vdots & \vdots & \vdots & \vdots \\
2019 & 47 & 2 & 8 & 3 & 9999 & {} & {} & {} & {}
\end{array}
$$
疾病分類コードの4桁から上2桁(D)を取り出します。(上2桁が"21"のコードはおそらくエラーなので"99"(不明)に修正しておきます。)
# 疾病分類上2桁コードD追加
df_ytsnkd_X['D'] = df_ytsnkd_X['d'].str[0:2]
df_ytsnkd_X['D'] = df_ytsnkd_X['D'].str.replace('21', '99')性、年齢階級別に集計したとき、疾病分類コード上2桁で
・15:妊娠,分娩及び産じょく
・16:周産期に発生した病態
・22:特殊目的用コード
は出現数が少なかったので、これらと99(不明)は除いておきます。
df_ytsnkd_X.loc[:,['s','n','D','Ken']] \
.groupby(['s','n','D'], as_index=False) \
.sum() \
.pivot(index=['D'], columns=['s','n'], values=['Ken'])
# Ken \
# s 1
# n 1 2 3 4 5 6 7
# D
# 01 15555934 5673881 4421574 5709241 5360765 4731769 5082288
# 02 574173 647176 702336 1624901 3081046 5444762 10196363
# 03 493260 347042 187910 273781 340722 377128 463142
# 04 881625 1049514 1507153 5484092 15399787 24517097 30573370
# 05 4742145 4501718 5407391 8587402 9177678 6453376 3686804
# 06 1138642 1824380 2128352 3566361 5212552 5334884 5073839
# 07 9820189 10606451 8002676 8211202 7927783 8129120 12580572
# 08 8470766 1748611 975705 1458766 1698515 1792796 2317525
# 09 366554 823095 1089113 4748005 19467346 43841265 64904103
# 10 99653170 33555187 17731705 25970509 22119538 14608783 13306907
# 11 2963709 2033032 3632525 7153465 10551286 12038579 13536630
# 12 27582941 11725801 10024650 11334139 10180603 7910802 8115113
# 13 1674818 4976901 3365951 8062821 13271444 16289395 18961663
# 14 1360950 693026 1164964 2287414 2959987 4036081 7281315
# 15 45995 2541 768 922 545 404 416
# 16 2052794 47344 4397 1939 808 397 568
# 17 2466298 766323 246502 201059 185820 159752 169486
# 18 3732764 1928205 1401534 2088873 2450030 2321488 2613094
# 19 8562421 11178399 3859052 4553751 4843611 4017784 3772547
# 22 21 10 46 40 45 30 72
# 99 38843688 24838031 23232209 38368419 46527248 46159536 50705878
# \
# s 2
# n 8 1 2 3 4 5 6
# D
# 01 1050036 14161900 5422963 7443414 7998286 6489350 6197321
# 02 2970448 633925 906535 3236646 7709507 13973499 13141297
# 03 109199 318611 677214 1600677 2642886 3166796 1536252
# 04 6258665 888012 1611246 5370164 8677612 12609117 24249278
# 05 597710 1712698 3041898 7669943 11099509 12447295 9853059
# 06 1181105 892746 1726859 2648631 4247475 5920086 6448904
# 07 3539342 9843149 14930596 16946432 16283946 16426530 17384497
# 08 555026 7575562 1780682 1766530 2475791 2772202 3162550
# 09 14507896 331665 805420 1197799 3256464 12477818 35443393
# 10 2682612 87727667 29036497 27558118 38913420 33317052 24461790
# 11 2886743 3090999 2351313 6786146 10758131 13066823 14975536
# 12 1716658 24705086 13619440 18151726 18426392 17638683 13750055
# 13 4490923 1417888 3812626 4644882 9132394 16856796 26889950
# 14 2250264 738864 1668423 10369512 13942010 13755743 11010426
# 15 137 45499 191035 4786367 6909018 753956 11143
# 16 118 1755717 44541 141088 172014 12117 810
# 17 35506 2176762 737043 389736 358195 334232 307894
# 18 609322 3240415 2039897 2982790 4197029 4567330 4460607
# 19 821010 6246680 6839727 3109767 3721464 4606186 5442918
# 22 13 10 11 41 37 48 30
# 99 10377566 36487913 26517968 36354970 53953742 61067999 63874821
# s
# n 7 8
# D
# 01 5126045 1155661
# 02 9756112 2177381
# 03 615902 143032
# 04 30535868 7547967
# 05 6145745 1349611
# 06 5242996 1462949
# 07 18515682 5626670
# 08 3033702 783483
# 09 48525303 14912119
# 10 15513523 2663302
# 11 12964404 3216744
# 12 8812779 1766827
# 13 28281636 8717460
# 14 5448739 1150749
# 15 3574 634
# 16 875 140
# 17 222425 50370
# 18 3451962 804991
# 19 5021395 1384273
# 22 39 3
# 99 53993823 11759778
df_ytsnkd_X = df_ytsnkd_X.query('not D in ["15","16","21","22","99"]')
print(df_ytsnkd_X.shape)
# (1436575, 11)年度、都道府県、性、年齢階級、診療種別、疾病分類(上2桁)別に集計します。
df_ytsnkD_X = df_ytsnkd_X.groupby(['y', 't', 's', 'n', 'k', 'D'], as_index=False).sum()
print(df_ytsnkD_X.shape)
# (255260, 10)
Ds = sorted(list(set(df_ytsnkd_X['D'])))
print(Ds)
# ['01', '02', '03', '04', '05', '06', '07', '08', '09', '10',
# '11', '12', '13', '14', '17', '18', '19']
df_ytsnD_X_k = df_ytsnkD_X.pivot(index=['y','t','s','n','D'],
columns=['k'],
values=['Ken','Nit','Ten','Ten2'])
print(df_ytsnD_X_k.shape)
# (127840, 8)
col_names = []
for x in ['Ken','Nit','Ten','Ten2']:
for k in [1,2]:
col_names.append(x+'_'+str(k))
print(col_names)
# ['Ken_1', 'Ken_2', 'Nit_1', 'Nit_2', 'Ten_1', 'Ten_2', 'Ten2_1', 'Ten2_2']
df_ytsnD_X_k = df_ytsnD_X_k.set_axis(col_names, axis='columns')
df_ytsnD_X_k = df_ytsnD_X_k.reset_index()
print(df_ytsnD_X_k.columns)
# Index(['y', 't', 's', 'n', 'D', 'Ken_1', 'Ken_2', 'Nit_1', 'Nit_2', 'Ten_1',
# 'Ten_2', 'Ten2_1', 'Ten2_2'],
# dtype='object')
print(df_ytsnD_X_k.shape)
# (127840, 13)
# 調剤点数の計算
df_ytsnD_X_k['Ten_4'] = df_ytsnD_X_k['Ten2_2'] - df_ytsnD_X_k['Ten_2']
col_names = ['y','t','s','n','D']
for x in ['Ken','Nit','Ten']:
for k in [1,2]:
col_names.append(x+'_'+str(k))
col_names = col_names + ['Ten_4']
print(col_names)
# ['y', 't', 's', 'n', 'D', 'Ken_1', 'Ken_2', 'Nit_1', 'Nit_2', 'Ten_1', 'Ten_2', 'Ten_4']
df_ytsnD_X_k = df_ytsnD_X_k[col_names]
print(df_ytsnD_X_k.columns)
# ['y', 't', 's', 'n', 'D', 'Ken_1', 'Ken_2', 'Nit_1', 'Nit_2', 'Ten_1', 'Ten_2', 'Ten_4']
# Index(['y', 't', 's', 'n', 'D', 'Ken_1', 'Ken_2', 'Nit_1', 'Nit_2', 'Ten_1',
# 'Ten_2', 'Ten_4'],
# dtype='object')
print(df_ytsnD_X_k.shape)
# (127840, 12)
df_ytsnD_X_k$$
\def\arraystretch{1.5}
\begin{array}{c:c:c:c:c|c:c:c:c}
\textsf{y} & \textsf{t} & \textsf{s} & \textsf{n} & \textsf{D} & \textsf{Ken\_1} & \textsf{Ken\_2} & \cdots & \textsf{Ten\_4} \\ \hline
2010 & 1 & 1 & 1 & 01 & {} & {} & {} & {} \\
2010 & 1 & 1 & 1 & 02 & {} & {} & {} & {} \\
\vdots & \vdots & \vdots & \vdots & \vdots & \vdots & \vdots & \ddots & \vdots \\
2019 & 47 & 2 & 8 & 19 & {} & {} & {} & {}
\end{array}
$$
あとは、以前の記事と同様に医療費の3要素を計算します。
# 医療費の3要素の計算
df_ytsnD_XC_k = pd.merge(df_ytsnD_X_k, df_ytsn_P,
on=['y','t','s','n'], how='left')
df_ytsnD_XC_k['KperP_1'] = df_ytsnD_XC_k['Ken_1'] /(df_ytsnD_XC_k['P']/12)
df_ytsnD_XC_k['KperP_2'] = df_ytsnD_XC_k['Ken_2'] /(df_ytsnD_XC_k['P']/12)
df_ytsnD_XC_k['NperK_1'] = df_ytsnD_XC_k['Nit_1'] / df_ytsnD_XC_k['Ken_1']
df_ytsnD_XC_k['NperK_2'] = df_ytsnD_XC_k['Nit_2'] / df_ytsnD_XC_k['Ken_2']
df_ytsnD_XC_k['TperN_1'] = df_ytsnD_XC_k['Ten_1'] / df_ytsnD_XC_k['Nit_1']
df_ytsnD_XC_k['TperN_2'] = df_ytsnD_XC_k['Ten_2'] / df_ytsnD_XC_k['Nit_2']
df_ytsnD_XC_k['TperN_4'] = df_ytsnD_XC_k['Ten_4'] / df_ytsnD_XC_k['Nit_2']
print(df_ytsnD_XC_k.columns)
# Index(['y', 't', 's', 'n', 'D', 'Ken_1', 'Ken_2', 'Nit_1', 'Nit_2', 'Ten_1',
# 'Ten_2', 'Ten_4', 'P', 'KperP_1', 'KperP_2', 'NperK_1', 'NperK_2',
# 'TperN_1', 'TperN_2', 'TperN_4'],
# dtype='object')
print(df_ytsnD_XC_k.shape)
# (127840, 20)
col_names = ['y','t','s','n','D']
var_names = []
for x in ['KperP','NperK','TperN']:
if x != 'TperN':
for k in [1,2]:
var_names.append(x+'_'+str(k))
else:
for k in [1,2,4]:
var_names.append(x+'_'+str(k))
var_names
# ['KperP_1', 'KperP_2', 'NperK_1', 'NperK_2', 'TperN_1', 'TperN_2', 'TperN_4']
col_names = col_names + var_names
df_ytsnD_C7 = df_ytsnD_XC_k.copy()
df_ytsnD_C7 = df_ytsnD_C7[col_names]
print(df_ytsnD_C7.columns)
# Index(['y', 't', 's', 'n', 'D', 'KperP_1', 'KperP_2', 'NperK_1', 'NperK_2',
# 'TperN_1', 'TperN_2', 'TperN_4'],
# dtype='object')
print(df_ytsnD_C7.shape)
# (127840, 12)
# データのpivot
df_ytsn_C7_D = df_ytsnD_C7.pivot(index=['y','t','s','n'],
columns=['D'],
values=var_names)
print(df_ytsn_C7_D.shape)
# (7520, 119)
col_names = []
for ck in var_names:
for D in Ds:
col_names.append(ck+'_'+D)
col_names
df_ytsn_C7_D = df_ytsn_C7_D.set_axis(col_names, axis='columns')
df_ytsn_C7_D = df_ytsn_C7_D.reset_index()
print(df_ytsn_C7_D.columns)
# Index(['y', 't', 's', 'n', 'KperP_1_01', 'KperP_1_02', 'KperP_1_03',
# 'KperP_1_04', 'KperP_1_05', 'KperP_1_06',
# ...
# 'TperN_4_08', 'TperN_4_09', 'TperN_4_10', 'TperN_4_11', 'TperN_4_12',
# 'TperN_4_13', 'TperN_4_14', 'TperN_4_17', 'TperN_4_18', 'TperN_4_19'],
# dtype='object', length=123)
print(df_ytsn_C7_D.shape)
# (7520, 123)
# データのpivot
var_names = col_names
df_yt_C7_D_sn = df_ytsn_C7_D.pivot(index=['y','t'],
columns=['s','n'],
values=var_names)
col_names = []
for ck in var_names:
for s in [1,2]:
for n in [1,2,3,4,5,6,7,8]:
col_names.append(ck+'_'+str(s)+'_'+str(n))
df_yt_C7_D_sn = df_yt_C7_D_sn.set_axis(col_names, axis='columns')
df_yt_C7_D_sn = df_yt_C7_D_sn.reset_index()
print(df_yt_C7_D_sn.columns)
# Index(['y', 't', 'KperP_1_01_1_1', 'KperP_1_01_1_2', 'KperP_1_01_1_3',
# 'KperP_1_01_1_4', 'KperP_1_01_1_5', 'KperP_1_01_1_6', 'KperP_1_01_1_7',
# 'KperP_1_01_1_8',
# ...
# 'TperN_4_19_1_7', 'TperN_4_19_1_8', 'TperN_4_19_2_1', 'TperN_4_19_2_2',
# 'TperN_4_19_2_3', 'TperN_4_19_2_4', 'TperN_4_19_2_5', 'TperN_4_19_2_6',
# 'TperN_4_19_2_7', 'TperN_4_19_2_8'],
# dtype='object', length=1906)
print(df_yt_C7_D_sn.shape)
# (470, 1906)これで、10年間×47都道府県ごとの医療費の1904次元のデータ(性別、年齢階級別の診療種別、疾病分類上2桁ごとの「医療費の3要素」)
(10年 × 47都道府県)
×(7指標 × 疾病分類17区分 × 性別2区分 × 年齢階級8区分)
= 470行 × 1904次元
の形のデータができました。
$$
\def\arraystretch{1.5}
\begin{array}{c:c|c:c:c:c}
\textsf{y} & \textsf{t} & \textsf{KperP\_1\_01\_1\_1} & \textsf{KperP\_1\_01\_1\_2} & \cdots & \textsf{TperN\_4\_19\_2\_8} \\ \hline
2010 & 1 & {} & {} & {} & {} \\
2010 & 2 & {} & {} & {} & {} \\
\vdots & \vdots & \vdots & \vdots & \ddots & \vdots \\
2019 & 47 & {} & {} & {} & {}
\end{array}
$$
y:年度
2010~2019 の10年度分t:都道府県
1:北海道、・・・、47:沖縄 の47都道府県C7_D_s_n:疾病分類上2桁D、性別s、年齢階級n別の7指標
KperP_1_01_1_1、KperP_1_01_1_2、・・・、TperN_4_19_2_8 の1904項目C7:診療種別ごとの「医療費の3要素」で、XperY_k(診療種別kのYperX、YperX = Y/X)の形の10指標:
KperP_1:1人当たり件数_入院
KperP_2:1人当たり件数_外来
NperK_1:1件当たり日数_入院
NperK_2:1件当たり日数_外来
TperN_1:1日当たり点数_入院
TperN_2:1日当たり点数_外来
TperN_4:1日当たり点数_調剤
D:疾病分類上2桁
01:感染症及び寄生虫症、02:新生物、03:血液及び造血器の疾患並びに免疫機構の障害、04:内分泌,栄養及び代謝疾患、05:精神及び行動の障害、06:神経系の疾患、07:眼及び付属器の疾患、08:耳及び乳様突起の疾患、09:循環器系の疾患、10:呼吸器系の疾患、11:消化器系の疾患、12:皮膚及び皮下組織の疾患、13:筋骨格系及び結合組織の疾患、14:腎尿路生殖器系の疾患、17:先天奇形,変形及び染色体異常、18:症状,徴候及び異常臨床所見・異常検査所見で他に分類されないもの、19:損傷,中毒及びその他の外因の影響s:性別
1:男性、2:女性n:年齢階級
1:0~9歳、2:10~19歳、・・・、7:60~69歳、8:70歳以上
次元削減
PCAとUMAPで次元削減します。
データは、NAを0埋めしておきます。
また、以前の記事と同じく、スケールの異なる3要素のデータですので、スケーリングして用います。
# NAを0埋め
df = df_yt_C10_D_sn.copy().fillna(0)
# 数値部分のみ取り出し
X = df.iloc[:,2:]
print(X.shape)
# (470, 1904)
# 前処理
from sklearn import preprocessing
scaler = preprocessing.StandardScaler()
X = scaler.fit_transform(X)
scaler = preprocessing.MinMaxScaler()
X = scaler.fit_transform(X)
print(X.shape)
# (470, 1904)結果の表示は、以前の記事と同様に、年度yごと、都道府県tごとに色分けして図示します。
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import preprocessing
le = preprocessing.LabelEncoder()
# 年度y
label_y = le.fit_transform(df['y'])
cp = sns.color_palette("hls", n_colors=10+1)
color_y = [cp[x] for x in label_y]
# 都道府県t
label_t = le.fit_transform(df['t'])
cp = sns.color_palette("hls", n_colors=47+1)
color_t = [cp[x] for x in label_t]PCA
まず、PCAを実行します。
# PCA
from sklearn.decomposition import PCA
pca = PCA()
PC = pca.fit_transform(X)
print(PC.shape)
# (470, 160)PCAの結果を第1主成分(PC1)から第10主成分(PC10)まで図示します。

















PC1×PCn(n>1)を見ると、都道府県番号はお互いの相対的な位置関係を保ったまま全体としてほぼPC1軸に沿って平行移動しており、PCn×PCm(n>1,m>1)を見ると、同じ都道府県番号はほとんど位置を変えずに固まっているのは、疾病分類のない医療費データでPCAを実行した以前の記事と同じでした。PC1が時間の経過、PC2以降の主成分が地域の特徴を表す成分のようです。


なお、寄与率はあまり高くありませんでした。
import numpy as np
np.set_printoptions(precision=5, suppress=True) # numpyの表示桁数設定
# 寄与率
print(pca.explained_variance_ratio_) # 寄与率
# [0.20847 0.07569 0.06214 0.03919 0.03604 0.01964 0.01754 0.01659 0.01484
# 0.01349 0.01266 0.01127 0.01088 0.01045 0.01017 0.00998 0.00928 0.00888
# 0.00835 0.00763 0.00736 0.00703 0.00674 0.00643 0.0062 0.00601 0.00589
# 0.00577 0.00559 0.00529 0.00512 0.00493 0.0048 0.00477 0.00452 0.00423
# 0.00408 0.00402 0.00378 0.00368 0.00348 0.00341 0.00339 0.00331 0.00318
# 0.00305 0.00295 0.00291 0.00287 0.00281 0.00277 0.00272 0.00262 0.00256
# 0.00251 0.0025 0.00247 0.0024 0.00232 0.0023 0.00227 0.00223 0.00218
# 0.00214 0.00213 0.00211 0.00208 0.00206 0.00202 0.00198 0.00193 0.00188
# 0.00187 0.00182 0.0018 0.00179 0.00178 0.00176 0.00174 0.0017 0.00167
# 0.00166 0.00164 0.00163 0.00161 0.00159 0.00157 0.00156 0.00153 0.00152
# 0.0015 0.00148 0.00148 0.00145 0.00145 0.00142 0.00141 0.0014 0.00139
# 0.00138 0.00137 0.00136 0.00135 0.00134 0.00132 0.00131 0.0013 0.00128
# 0.00127 0.00124 0.00123 0.00123 0.00121 0.0012 0.00119 0.00119 0.00117
# 0.00117 0.00115 0.00115 0.00114 0.00113 0.00113 0.00111 0.0011 0.00109
# 0.00109 0.00107 0.00106 0.00106 0.00105 0.00104 0.00103 0.00102 0.00101
# 0.001 0.00099 0.00099 0.00098 0.00097 0.00097 0.00096 0.00095 0.00095
# 0.00093 0.00093 0.00092 0.00092 0.0009 0.0009 0.0009 0.00089 0.00089
# 0.00088 0.00087 0.00087 0.00086 0.00085 0.00084 0.00083 0.00083 0.00083
# 0.00082 0.00082 0.00081 0.0008 0.00079 0.00079 0.00078 0.00078 0.00077
# 0.00077 0.00076 0.00076 0.00075 0.00075 0.00074 0.00074 0.00073 0.00073
# 0.00072 0.00072 0.00071 0.0007 0.0007 0.00069 0.00069 0.00068 0.00068
# 0.00067 0.00067 0.00066 0.00066 0.00065 0.00065 0.00064 0.00064 0.00063
# 0.00063 0.00062 0.00062 0.00062 0.00061 0.00061 0.0006 0.0006 0.0006
# 0.00059 0.00059 0.00058 0.00058 0.00057 0.00057 0.00057 0.00056 0.00056
# 0.00055 0.00055 0.00054 0.00054 0.00054 0.00054 0.00054 0.00053 0.00053
# 0.00053 0.00052 0.00052 0.00051 0.00051 0.0005 0.0005 0.0005 0.00049
# 0.00049 0.00049 0.00048 0.00048 0.00048 0.00047 0.00047 0.00047 0.00046
# 0.00046 0.00046 0.00045 0.00045 0.00045 0.00045 0.00045 0.00044 0.00044
# 0.00043 0.00043 0.00043 0.00042 0.00042 0.00042 0.00041 0.00041 0.00041
# 0.0004 0.0004 0.0004 0.0004 0.00039 0.00039 0.00039 0.00038 0.00038
# 0.00038 0.00038 0.00037 0.00037 0.00037 0.00036 0.00036 0.00036 0.00036
# 0.00036 0.00035 0.00035 0.00035 0.00035 0.00034 0.00034 0.00034 0.00034
# 0.00033 0.00033 0.00033 0.00033 0.00032 0.00032 0.00032 0.00032 0.00032
# 0.00031 0.00031 0.00031 0.00031 0.0003 0.0003 0.0003 0.0003 0.00029
# 0.00029 0.00029 0.00029 0.00028 0.00028 0.00028 0.00028 0.00028 0.00028
# 0.00027 0.00027 0.00027 0.00027 0.00027 0.00027 0.00026 0.00026 0.00026
# 0.00026 0.00025 0.00025 0.00025 0.00025 0.00025 0.00024 0.00024 0.00024
# 0.00024 0.00023 0.00023 0.00023 0.00023 0.00023 0.00023 0.00023 0.00022
# 0.00022 0.00022 0.00022 0.00022 0.00021 0.00021 0.00021 0.00021 0.00021
# 0.0002 0.0002 0.0002 0.0002 0.0002 0.0002 0.00019 0.00019 0.00019
# 0.00019 0.00019 0.00019 0.00018 0.00018 0.00018 0.00018 0.00018 0.00018
# 0.00017 0.00017 0.00017 0.00017 0.00017 0.00017 0.00017 0.00016 0.00016
# 0.00016 0.00016 0.00016 0.00016 0.00015 0.00015 0.00015 0.00015 0.00015
# 0.00015 0.00015 0.00015 0.00014 0.00014 0.00014 0.00014 0.00014 0.00013
# 0.00013 0.00013 0.00013 0.00013 0.00013 0.00013 0.00013 0.00013 0.00012
# 0.00012 0.00012 0.00012 0.00012 0.00012 0.00012 0.00011 0.00011 0.00011
# 0.00011 0.00011 0.00011 0.00011 0.0001 0.0001 0.0001 0.0001 0.0001
# 0.0001 0.0001 0.00009 0.00009 0.00009 0.00009 0.00009 0.00009 0.00009
# 0.00008 0.00008 0.00008 0.00008 0.00008 0.00008 0.00008 0.00007 0.00007
# 0.00007 0.00007 0.00007 0.00007 0.00007 0.00007 0.00006 0.00006 0.00006
# 0.00006 0.00006 0.00006 0.00006 0.00005 0.00005 0.00005 0.00005 0.00005
# 0.00005 0.00004 0.00004 0.00004 0.00004 0.00003 0.00003 0.00003 0.00003
# 0.00003 0. ]
print(np.cumsum(pca.explained_variance_ratio_)) # 累積寄与率
# [0.20847 0.28416 0.3463 0.38549 0.42152 0.44116 0.4587 0.47529 0.49012
# 0.50361 0.51626 0.52754 0.53842 0.54887 0.55905 0.56903 0.57831 0.58719
# 0.59553 0.60317 0.61052 0.61755 0.62428 0.63071 0.63691 0.64292 0.64882
# 0.65459 0.66018 0.66547 0.6706 0.67553 0.68033 0.6851 0.68962 0.69386
# 0.69793 0.70195 0.70573 0.70942 0.71289 0.71631 0.71969 0.723 0.72618
# 0.72923 0.73218 0.73508 0.73796 0.74077 0.74353 0.74625 0.74887 0.75143
# 0.75394 0.75644 0.75891 0.7613 0.76362 0.76593 0.7682 0.77044 0.77262
# 0.77476 0.77689 0.779 0.78108 0.78314 0.78516 0.78714 0.78907 0.79095
# 0.79282 0.79464 0.79644 0.79823 0.80001 0.80177 0.8035 0.80521 0.80688
# 0.80854 0.81018 0.81181 0.81341 0.815 0.81658 0.81814 0.81967 0.82118
# 0.82269 0.82417 0.82564 0.8271 0.82854 0.82996 0.83138 0.83277 0.83416
# 0.83554 0.83691 0.83826 0.83961 0.84095 0.84227 0.84358 0.84488 0.84615
# 0.84742 0.84866 0.8499 0.85112 0.85233 0.85353 0.85472 0.85591 0.85708
# 0.85825 0.8594 0.86055 0.86169 0.86281 0.86394 0.86505 0.86615 0.86724
# 0.86833 0.8694 0.87046 0.87151 0.87256 0.8736 0.87462 0.87564 0.87665
# 0.87765 0.87864 0.87963 0.88061 0.88158 0.88255 0.8835 0.88445 0.8854
# 0.88633 0.88726 0.88818 0.8891 0.89 0.8909 0.8918 0.89269 0.89358
# 0.89447 0.89534 0.89621 0.89707 0.89792 0.89876 0.89959 0.90043 0.90126
# 0.90208 0.9029 0.90371 0.90451 0.9053 0.90609 0.90687 0.90765 0.90842
# 0.90919 0.90994 0.9107 0.91145 0.9122 0.91294 0.91368 0.91441 0.91514
# 0.91585 0.91657 0.91728 0.91798 0.91868 0.91937 0.92006 0.92074 0.92142
# 0.92209 0.92276 0.92342 0.92407 0.92472 0.92537 0.92601 0.92665 0.92728
# 0.92791 0.92854 0.92916 0.92978 0.93039 0.93099 0.9316 0.9322 0.9328
# 0.93339 0.93397 0.93455 0.93513 0.9357 0.93627 0.93683 0.93739 0.93795
# 0.9385 0.93905 0.9396 0.94014 0.94068 0.94122 0.94175 0.94228 0.94281
# 0.94334 0.94386 0.94437 0.94488 0.94539 0.94589 0.94638 0.94688 0.94737
# 0.94786 0.94835 0.94883 0.94931 0.94979 0.95026 0.95073 0.9512 0.95166
# 0.95212 0.95258 0.95303 0.95349 0.95393 0.95438 0.95483 0.95527 0.9557
# 0.95613 0.95656 0.95699 0.95741 0.95783 0.95825 0.95867 0.95907 0.95948
# 0.95988 0.96028 0.96068 0.96107 0.96147 0.96186 0.96225 0.96263 0.96301
# 0.96339 0.96377 0.96414 0.96451 0.96488 0.96524 0.96561 0.96597 0.96632
# 0.96668 0.96703 0.96738 0.96773 0.96808 0.96842 0.96876 0.9691 0.96944
# 0.96977 0.9701 0.97043 0.97075 0.97108 0.9714 0.97172 0.97204 0.97235
# 0.97267 0.97298 0.97329 0.97359 0.9739 0.9742 0.9745 0.9748 0.97509
# 0.97538 0.97567 0.97596 0.97624 0.97653 0.97681 0.97709 0.97736 0.97764
# 0.97791 0.97818 0.97845 0.97872 0.97899 0.97925 0.97951 0.97977 0.98003
# 0.98028 0.98054 0.98079 0.98104 0.98129 0.98154 0.98178 0.98202 0.98227
# 0.9825 0.98274 0.98297 0.9832 0.98343 0.98366 0.98389 0.98411 0.98434
# 0.98456 0.98478 0.98499 0.98521 0.98542 0.98564 0.98585 0.98606 0.98627
# 0.98647 0.98667 0.98688 0.98708 0.98728 0.98747 0.98767 0.98786 0.98805
# 0.98823 0.98842 0.98861 0.98879 0.98898 0.98916 0.98934 0.98951 0.98969
# 0.98987 0.99004 0.99021 0.99038 0.99055 0.99072 0.99088 0.99105 0.99121
# 0.99137 0.99153 0.99168 0.99184 0.99199 0.99215 0.9923 0.99245 0.9926
# 0.99274 0.99289 0.99304 0.99318 0.99332 0.99347 0.99361 0.99374 0.99388
# 0.99401 0.99414 0.99427 0.99441 0.99453 0.99466 0.99479 0.99492 0.99504
# 0.99516 0.99528 0.9954 0.99552 0.99564 0.99576 0.99587 0.99598 0.9961
# 0.99621 0.99632 0.99642 0.99653 0.99663 0.99674 0.99684 0.99694 0.99704
# 0.99714 0.99724 0.99733 0.99742 0.99752 0.9976 0.99769 0.99778 0.99786
# 0.99795 0.99803 0.99811 0.99819 0.99827 0.99835 0.99842 0.9985 0.99857
# 0.99864 0.99871 0.99878 0.99885 0.99891 0.99898 0.99904 0.9991 0.99916
# 0.99922 0.99928 0.99933 0.99939 0.99944 0.99949 0.99954 0.99959 0.99964
# 0.99968 0.99973 0.99977 0.99981 0.99984 0.99988 0.99991 0.99994 0.99997
# 1. 1. ]UMAP
次に、UMAPを実行します。パラメータn_neighbors(デフォルトでは15)を少しずつ変えて実行します。
# UMAP
! pip install umap-learn
list_n_neighbors = [2,3,4,5,10,11,12,13,14,15,16,17,18,19,20,
25,30,40,50,75,100,150,200,300,400]
for n_neighbors in list_n_neighbors:
reducer = umap.UMAP(n_components=2, n_neighbors=n_neighbors, random_state=0)
reducer.fit(X)
embedding = reducer.transform(X)
print(embedding.shape) # (470, 2)










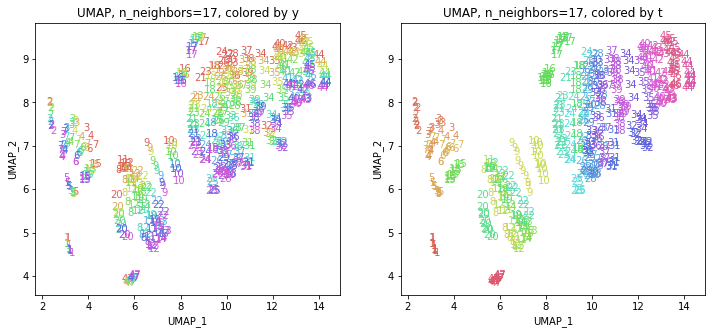












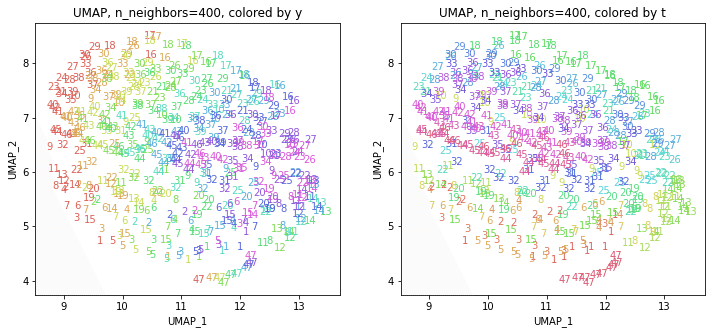
パラメータn_neighborsの値が小さいと、都道府県ごとに分かれていて、パラメータn_neighborsの値を上げていくと、だんだん年度の向きがそろってきて、さらに上げていくと、年度の向きが完全にそろっていくのは、疾病分類のない医療費データでUMAPを実行した以前の記事と同じでした。
中間のn_neighbors=15~20あたりがバランスが取れていてよさそうです。n_neighbors=15の結果を見ると、概ね、左半分に東日本(東北~関東・東海)、右半分に西日本(関西~中国・四国・九州)の都道府県が、上の方に北海道と沖縄がそれぞれ固まっています。



おわりに
今回は、次元削減の手法(PCAとUMAP)を使って、疾病分類を含む1904次元の医療費データを2次元に圧縮してみました。疾病分類を含まない160次元のデータで次元削減を行ったときと傾向としては似たような結果になりました。
最後まで読んでいただき、ありがとうございました。
お気づきの点等ありましたら、コメントいただけますと幸いです。
#医療費 , #医療費の3要素 , #医療費分析 , #医療費の地域差 , #地域差 , #地域間格差 , #疾病分類 , #社会保険表章用疾病分類 , #PCA , #UMAP , #次元削減 , #次元圧縮 , #機械学習 , #Python , #協会けんぽ , #noteで数式
この記事が気に入ったらサポートをしてみませんか?