
[PyCaret]Pythonでの機械学習の自動化

PyCaretってご存じでしょうか?
私は今日知りました。
でも、すごい便利で半端じゃないので共有させてください。
この記事では、大まかなPyCaretの説明と、今すぐにでも実行できる簡易なコードも記載しております。
PyCaretとは?
PyCaretはほんとに最近実装されたフレームワークです。
エクセルのデータファイルを用意して、数行のコードを記入するだけで最適な解析を行うことができます。
特徴としては、前処理・モデルの決定・パラメータの最適化・結果の評価をまとめて行えます。
前処理
・欠損値の補完
・one-hotエンコーディング
・正規化
などを自動で行ってくれます。
モデルの決定
回帰
・線形回帰
・ランダムフォレスト
・決定木
・サポートベクターマシン
など20種類近くの回帰モデルを適用してくれます。
分類
・k近傍
・ロジスティック回帰
・Cat Boost
など20種類近くの分類モデルを適用できます。
僕自身無知なので違いはわかりませんが、きっとすごいでしょう。

上が回帰解析の一例です。このように、あらゆる評価指標を提供してくれます。
パラメータの最適化
一行入力するだけで、自動で最適化してくれます。

このように、k分割交差検証とその平均を出力します。コメントとして、用いたパラメータの値も出力します。
例えば、回帰のランダムフォレストなら、決定木の個数を求めてくれます。(まだ勉強中なのでよくわかっていません。。)
結果の評価
結果はほんとに様々得られます。勉強不足なんで、コメントはできないですが、分析にはうってつけかと思われます。
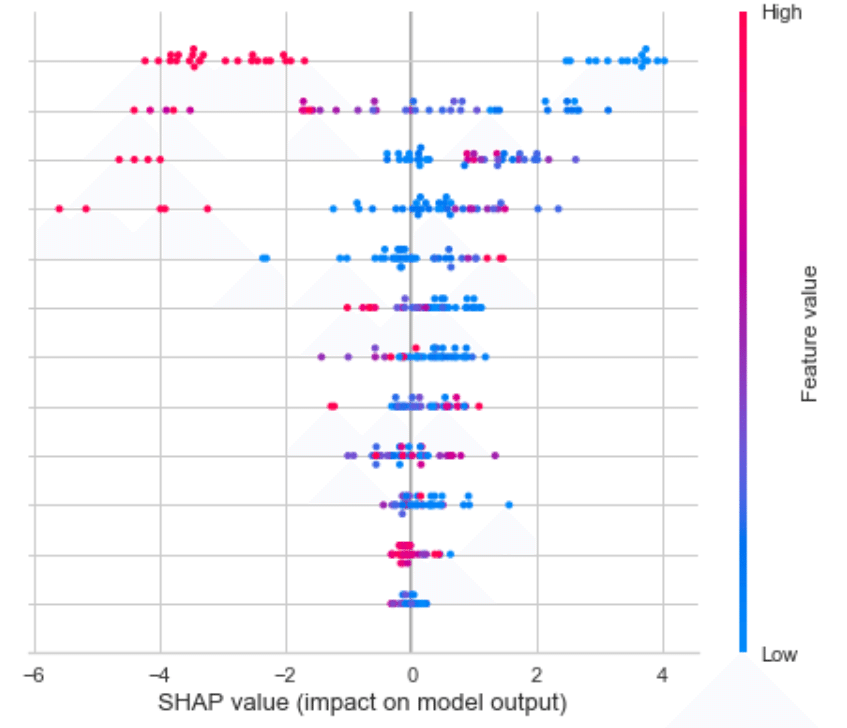

これは、精度の悪い例ですが、このような結果が得られます。エクセルでこれらを作るのは大変だと思うので、すごい便利です。
PyCaretの導入
以下のコードで簡易な回帰解析を行えます。
1. インストールとデータの入力
pip install pycaret
from pycaret.regression import *
import pandas as pd
from pycaret.regression import *
data1 = pd.read_excel(r'C:\Users\myfile\demo.xlsx')2.モデルの構築
model = setup(data1, target = 'value', ignore_features = None)3. モデルの比較
compare_models()4. 使用するモデルの決定と解析
rf = create_model('rf')(今回はランダムフォレストのためrfで出力しています。対応する形はこちらに記載されています。)
5. チューニング
tuned_rf = tune_model('rf')6. 結果の評価
evaluate_model(tuned_rf)interpret_model(tuned_rf)
plot_model(tuned_rf)7. 結果の出力
predictions = predict_model(rf, data=data1)
predictions回帰なら各データの予測結果を出力します。また、data=のところで分けておいたテストデータを用いると上記で作成したモデルに適用することができます。
8. csvへの転記
predictions.to_csv("result.csv")まとめ
機械学習を始めてまもないですが、すごいことは実感してます。また勉強して追記していきます。
この記事が気に入ったらサポートをしてみませんか?