
【MTG x GPTs】 類似カード検索 GPT 作成レポ

はじめに
GPTs のサービスが始まったことで、誰でも簡単に ChatGPT に知識を大量に与えられるようになった。
なんでもいいから試してみたかったのだが、すぐ用意できそうである程度数のあるデータであり、作成者が有用なものかどうかの判別が容易にできるという理由から Magic: The Gathering の全てのカードを知識として与えた GPT を作成した。GPTとしてはまだ改善する点が多く残るが、知識を与えるという当初の目標は達成したのでそのレポートになる。
できたもの
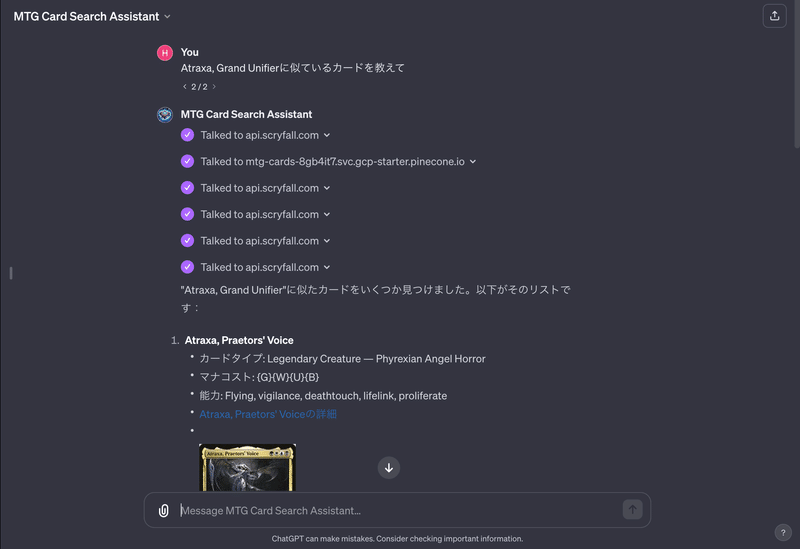
[Share Link](Share Link上では画像は出ません)
普通の GPT-4 に同様の質問をするとこんな感じ

ゆるく GPTs の説明(知ってたら飛ばして OK)
GPT-4 をベースに各自でオリジナルのチャットボットを制作できるサービス。
WebAPI との通信ができるようになったのが一番のメリットで、これができるとよく技術系の記事で「自社資料を GPT に学習させたチャットボットを作成しました」みたいな記事があるが、その構築がより容易にできるようになる。
他にもログイン機能をつけてユーザー独自の...とかもできるようになったが、ログイン機能をつけたことによって起きる面白そうなことを思いつかなかったので思いついたらこっそり教えて欲しい。
利用技術,サービスについて
サービス利用にあたっての選考基準は、「できるだけ楽に、安く、使ったことがないものを」で選んだ。作成費は後述。
ChatGPT Plus (有償版ChatGPT)
GPTs を使うため必要
OpenAI Embeddings API
テキストをベクトル化するために利用
他の技術(BERT)などと比較して導入の技術的コストが少ないため採用
Pinecone
ベクトルデータベースとその検索エンジンのサービス
使ったことがなく、比較対象の中でドキュメントがわかりやすかった為採用
scryfall API & Bulk Data
今回は MTG のカードの取得用に利用している
技術 x MTG 関連で困ったらいつも使っている。ホンマありがとう
できたら ID を使ったカード一括検索ができるともっと嬉しい
node / MySQL
一々書くか迷ったが、一応
nodeでJSONデータを整形したり、それをMySQLに投入したりしている
MySQLはデータの管理用
作業内容
元データを用意しよう
今回は MTG のカードを全種類を GPT に知識として与える事を目標としたので、全種類のカードデータを用意したい。
というわけで利用したのが scryfall の Bulk Data
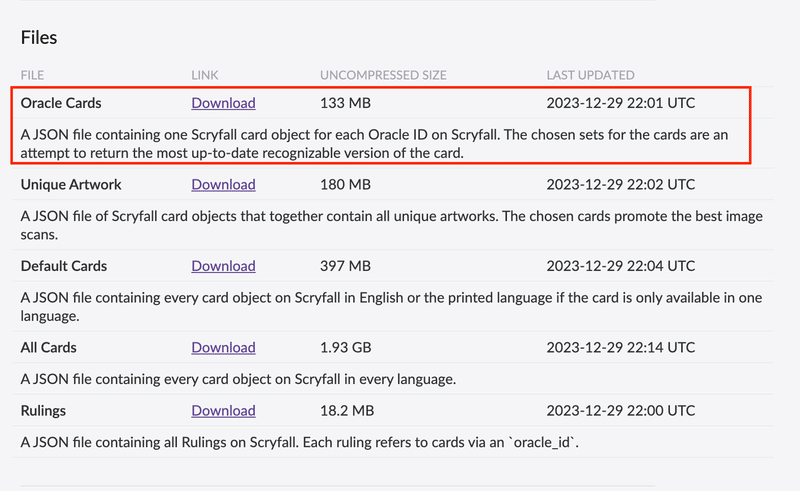
この Oracle Cards を利用した。オラクルごとにカードを 1 つづつ取得していて、再録カードな複数種類があるカードは最新の収録されたものが取得される。このデータを全部処理すれば重複なく全種類のカードデータが処理できる。
取得できるカードデータ例(JSON 形式)←これが 2 万何千件ある感じです。
データをベクトル変換しよう
今回ベクトル変換に利用したのは OpenAI Embeddings API。これはテキストをベクトルに変換してくれるもので、先ほど取得したカードのデータを全てこの API を介してベクトル変換を行うのがこの作業。カードデータの中には各種 ID や scryfall の URL などカードそのものとは関係のない管理のために存在する不必要なデータが大量にあるので、必要なもののみを選び出す作業が存在する。なのでこの作業を細かく分けると、下記のようになる。
管理のためダウンロードした Bulk データを一旦ローカルの DB に保存
カードデータの中から必要なものだけを抽出したテキストを作成する作業
抽出したテキストをベクトル変換
管理のためダウンロードした Bulk データを一旦ローカルの DB に保存
一番面倒だったと言っても過言ではない作業。
ダウンロードデータのサイズがでかいため JSON を直で触り続けることを諦め、docker で MySQL コンテナを建てその中に一度全てのデータを突っ込んだ。大多数のカードは同じように管理して問題はなかったが、両面カードや出来事カード、分割カードなどの管理は個別に設定する必要があったため注意が必要。
今回は [Garruk Relentless // Garruk, the Veil-Cursed]のように、名前やそれぞれのテキストを"//"で分割して保存した。
カードデータの中から必要なものだけを抽出したテキストを作成する作業
まずはカードのテキストのうち必要な物を抽出して一つの文にする。今回は下記のように変換を行った。

このフォーマットに則るとJadar, Ghoulcaller of Nephaliaであれば

このデータを OpenAI の EmbeddingsAPI に渡してやることで、対応するベクトルを取得している。
const apiUrl = "https://api.openai.com/v1/embeddings";
const body = {
input: formattedText,
model: "text-embedding-ada-002",
};
const response = await axios.post(apiUrl, body, {
headers: {
"Content-Type": "application/json",
Authorization: `Bearer XXXXX`,
},
});この response の中にベクトル変換されたデータが入っている。
ベクトルデータベースにデータを配置しよう
先ほど作成したデータをベクトルデータベースに保存していく。その前に、データベースの設定を行う。Pinecone でアカウントを作成し、ダッシュボードから index の作成を行う。設定は画像参照。 metric は Embeddings API 側で推奨されていたのでコサインを設定、Dimentions は Embeddings の出力に合わせて 1536 を設定。
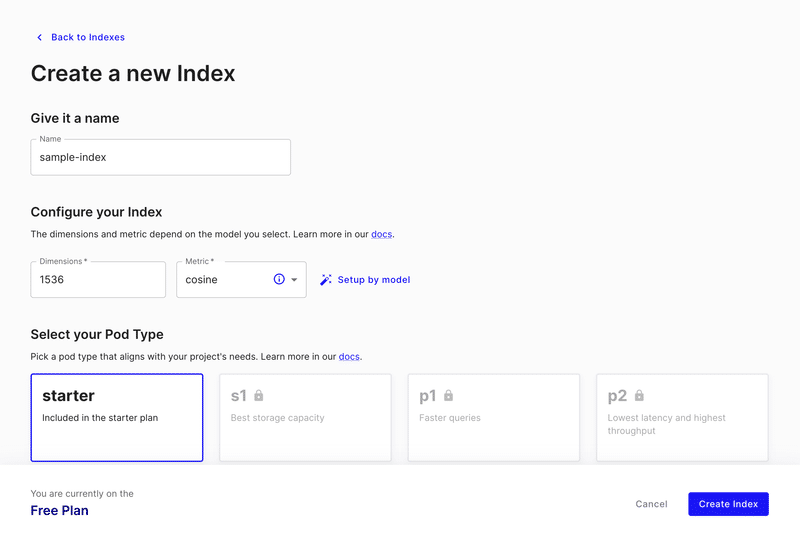
API Key を作成/保存して、node 側から叩いた。
const { Pinecone } = require("@pinecone-database/pinecone");
const pinecone = new Pinecone({
environment: "gcp-starter",
apiKey: "xxxxxx",
});
const index = pinecone.Index("sample-index");
const pineconeData = {
id: data.id, // 一意のID,今回はscryfallのIDと同じものを利用している
values: vector,
};
await index.upsert([pineconeData]);上記のコードは保存のための最低限の実装。ベクトルと一緒に metadata を一緒に保存することができるので、それを活用すると『cmc が 2 以下かつ固有色が青の中から、特定のカードに近いものを検索』や『事前に表示したい内容を入れることで検索結果をscryfall APIでの変換を含めずに取得』ができるようになる。実際には変数 pineconeData の中身は下記のように設定していた。
const pineconeData = {
id: data.id,
values: vector,
metadata: {
name: data.name,
mana_cost: data.mana_cost || "",
cmc: data.cmc || 0,
type_line: data.type_line || "",
oracle_text: data.oracle_text || "",
colors: data.colors || "",
color_identity: data.color_identity || "",
keywords: data.keywords || "",
legalities_legacy: legalities.legacy,
legalities_pioneer: legalities.pioneer,
legalities_standard: legalities.standard,
legalities_modern: legalities.modern,
legalities_commander: legalities.commander,
legalities_explorer: legalities.explorer,
legalities_historic: legalities.historic,
},
};GPTs の設定をしよう
改めて今回の GPT でやりたいことを細分化するとこんな感じ
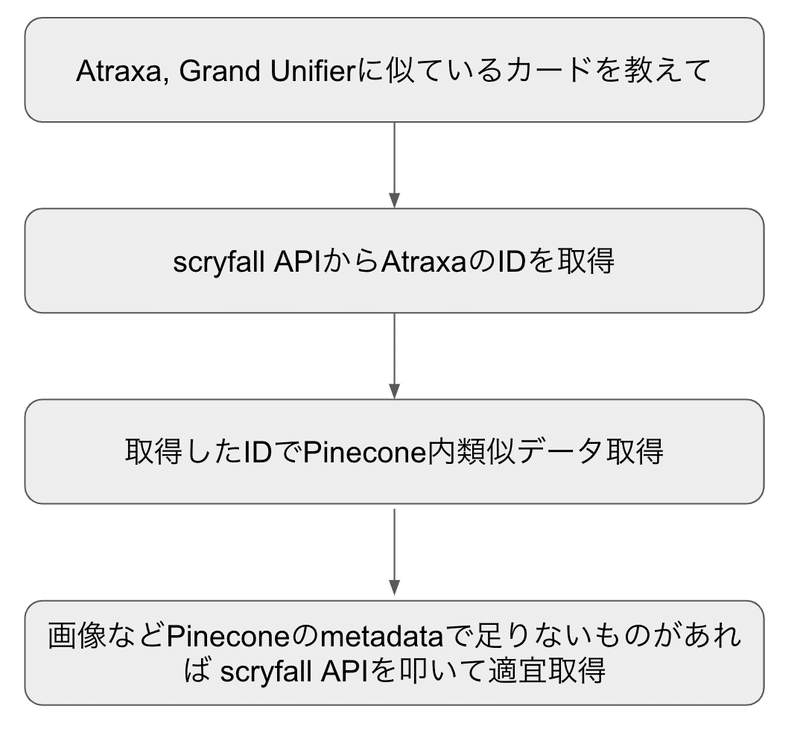
Pinecone を利用することでデータを投入すれば API だけ叩けばデータの検索が行える。 これからは簡単に、GPT の設定について話す。
Configue > Create new Action から利用する API の設定ができる。複数設定可能なので、pinecone API と scryfall API をそれぞれに設定する。 Schema に yaml(OpenAPI) を設定する必要があるのだが、この yaml の作成が面倒。めっちゃ面倒。でも、安心して欲しい。我々には優秀な助手 ChatGPT がついている。書いてもらおう。

今回はこれらが対象なので近いものを作ってみる場合には活用してほしい。右の URL はそれぞれのドキュメントとなっている。
ベクトルDBクエリ:https://docs.pinecone.io/reference/query
改善案諸々
実際作ったのちに「ああすればよかった」とか「これ次触るときに変わってて欲しいな」と感じた点。
出力結果が思ったよりカード名に寄る
カードテキストの抽出の際に思い切ってベクトル生成の対象からカード名をオミットしてしまえばよかったと後悔している。
オリカで検索する機能は追加で API が必要
オリカを用意してそのオリカに近いカードを検索する機能は実現可能
実現するにはオリカのテキストを伝えて、それをベクトルに変換する必要がある
当初 ChatGPT 側でベクトルを利用している都合インターフェース上で「このオリカをベクトル化しろ!!」と伝えればしてくれると思っていたが、出来なかった
上記の理由で今回は実装されていない
実装のためには新しく Action を用意し、そこから Embeddings API またはそれをラップした API を叩くことで実現ができそう
ただしこの形であれば検索のたびに課金をすることになるのでそこには注意
(要望) GPT の git 管理
GPT のプロンプトをちょっといじった後「なんか違うな戻そう」とする処理がとても難しい
手元で description を始めとした構成データを git 管理してしまえばいいのだが、面倒
最終的な費用
最後におまけとして費用の話。
今回利用したサービスの中で課金対象は
ChatGPT Plus
ChatGPT Embeddings API
ChatGPT Plusは月々 $20ドル という支払いが公開されている。
厄介なのは約 2 万 6 千のカードのデータを全部ベクトル化させるために使った Embeddings API の費用の話で、どれだけかかるのかの計算がわかりにくい。こちらのリンクから費用にかかわるToken数が計算できるので参考にしてほしい。結局使用したクレジットは $0.7 で日本円にして 100 円ほどで作成ができた。なので改善案のところで利用料金かかるから注意と書いたが個人で使う分には考える必要はないと認識している。
これのためだけにPlusの月々$20 はちょっとどうなの?って気もするが、すでに契約をしている場合はぜひ一度試してみて欲しい。
その他
何か質問などあれば @amalgam_sv までよろしく。
この記事が気に入ったらサポートをしてみませんか?