
Python(Flask)を使ったAIアプリ「近鉄特急どれかな?」の開発記録 その1~テーマ決め、学習用データの収集と前処理~

AIアプリ「近鉄特急どれかな?」について
AIアプリ「近鉄特急どれかな?」は、画像ファイルを読み込む、または画像のurlを指定すると、10種類の近鉄特急のうち、どれに似ているかを判別します。
12200系 スナックカー
12400系 サニーカー
20000系 楽
21000系 アーバンライナーplus
21020系 アーバンライナーnext
22000系 ACE(エー・シー・イー)
22600系 Ace(エース)
23000系 伊勢志摩ライナー
50000系 しまかぜ
80000系 ひのとり
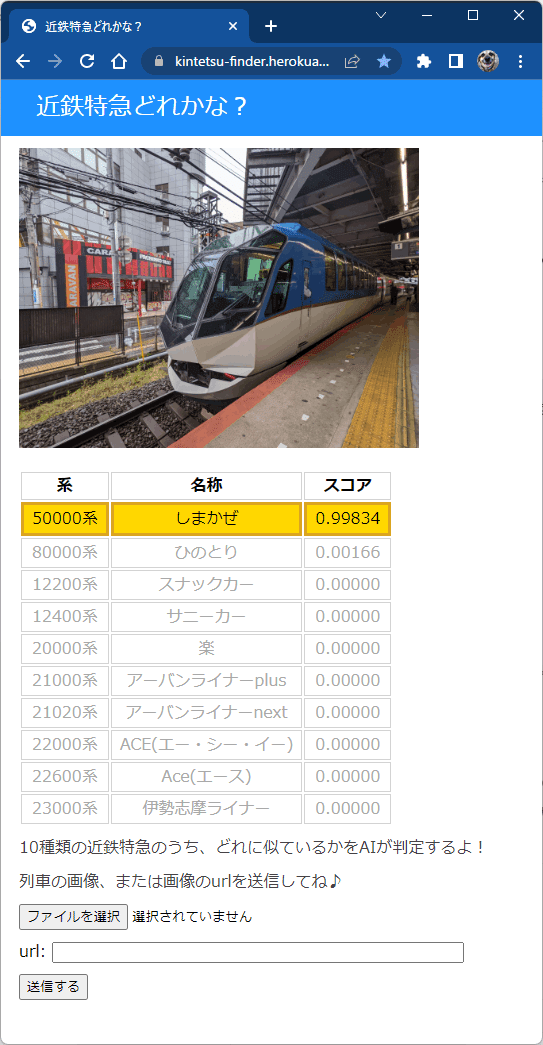
Webアプリ「近鉄特急どれかな?」はこちら
アプリのコンセプト
このアプリでやりたかったことは、近鉄特急以外の車両を読み込んで、10種類の近鉄特急のうちのどれに近いかを判別する、ということでした。
写真からどの特急なのかはGoogle レンズが教えてくれますが、10種類を似ている順に表示するということはGoogleレンズではできないことなので、このアプリの存在価値があるのでは?と思いました。
息子と判別結果が出る前に、どれに近いかを予想しあうゲームをしましたが、なかなか楽しかったです。
AIアプリ作成のきっかけ
機械学習(AI)を使って、面白いアプリをつくれるようになりたい、経験を積んでプログラミングを仕事にしたい、などの思いから、Aidemyの「AIアプリ開発講座(6か月コース)」を受講しました。
この講座では、実践を通じて多くのことを学ぶことができるようになっており、Python(Flask)を用いて、AIアプリ(web)をつくることが最終課題でした。
アプリ開発の流れ
アプリ開発の流れはだいたいこんな感じです。
テーマ決め ←ココ
モデル学習用データを収集(Webスクレイピング)←ココ
学習用データの前処理(データクレンジング)←ココ
モデルの作成と訓練 (tensorflow)
学習済みモデルの軽量化 (.h5から.tfliteへ変換)
Flaskでアプリの作成(ローカル環境)
本番環境の作成と公開(Heroku)
今回のアプリ開発で特に大変だったのは、3.学習用データの前処理と、7.本願環境の作成と公開でした。
学習済みモデルのファイル(.h5)が軽量(~数10 MB)であれば、5.モデルの軽量化は必要ないです。今回の場合では、400 MB近くになってしまい、ローカル環境では動きましたが、本番環境(HerokuやGoogle App Engine)では無理でした。
なので順番的には、7の本番環境の作成でエラーに遭遇して、いろいろ試行錯誤した結果、5. モデル軽量化と6. アプリ作成を行うことで、7. 本番環境作成がうまくいったという感じです。
本番環境を構築するにあたり、いろいろな壁にぶちあたり、Webサイトの運営って大変なんだな、、、というのをちょっと実感できました。
ここでは、1.テーマ決め、2.モデルの学習用データを収集、3.学習用データの前処理の内容を紹介します。
4(その2)はこちら
5(その3)はこちら
6, 7(その4)はこちら
1. テーマ決め
せっかくの機会なので、学んだ知識を生かして子どもたちが喜んでくれそうなアプリを作りたいなと思い、子どもたちが大好きな鉄道をアプリの題材にすることにしました。一から自力で学習用の素材を作成するような時間はとれないため、モデル学習用のデータを集めやすいテーマとしても、Webに素材が豊富にある鉄道は適していると考えました。
Python実行環境
Windows11のWSL2内や、Google Colaboratory ProでPythonを実行しました。
PC1: Dell xps 13 2-in-1
プロセッサ Intel(R) Core(TM) i7-1065G7 CPU @ 1.30GHz 1.50 GHz
PC2: Surfase Laptop Studio
プロセッサ 11th Gen Intel(R) Core(TM) i7-11370H @ 3.30GHz 3.30 GHz
PC1、PC2共通事項
実装 RAM 32.0 GB
システムの種類 64 ビット オペレーティング システム、x64 ベース プロセッサ
エディション Windows 11 Pro
バージョン 21H2OS ビルド 22000.832
Ubuntuバージョン(WSL2): 22.04 LTS または 20.04 LTS
Pythonバージョン: 3.10.4
Pythonを編集、実行したエディター: Visual Studio Code
Python仮想環境について
ローカルPC (Wondiws 11 WSL2内のUbuntu)で開発を行うときは、作業ディレクトリ内に仮想環境を作成し、仮想環境内でスクリプトを実行しました。
ターミナルで作業ディレクトリに移動し、以下を実行すると仮想環境が作成されます。
python3 -m venv env
source ./env/bin/activate仮想環境から抜けるには、以下のコードを実行します。
deactivateGoogle Colaboratory
Googleが提供するPythonを記述できるWebアプリケーションです。
基本的な機能は無料で使えます。より性能が良いPro、Pro+は有料です。
4.モデルの学習はローカルPCやGoogle Colaboratoryでは時間がかかりすぎたり、終わらなかったりしたため、より多くの試行錯誤ができるよう、最終的にGoogle Colaboratory Pro(有料)を利用しました。
5.のモデルの軽量化でも利用しました。
2. モデル学習用データの収集(Webスクレイピング)
Python BeautifulSoupでWebスクレイピング
モデルの学習用データとして、レイルラボ RailLabの鉄道画像を利用させていただきました。レイルラボRailLabは、ユーザー登録をすれば、誰でも鉄道の写真を投稿することができるサイトです。
テキストデータを取得
レイルラボのページには鉄道の写真と一緒に、鉄道会社名、形式、編成、路線、などの情報が載っています。これらのテキストデータを取得し、ラベル付けの判断材料にしようと考え、以下の手順でWebスクレイピングを行いました。
読み込むurlを指定
GETリクエスト実行
Beautiful SoupでWebページの情報を抽出、データフレームに追加
抽出した情報を整形
csvファイルに保存(trains.csv)
3のWebページの情報を抽出するにあたり、予めレイルラボのページを精査して、ほしい情報のセレクタを調べました。
セレクタ例: li.photo-list-max__item > div.row > div.col-md-6:nth-child(1) > a > img
1 ~ 3をfor文で6518回繰り返し処理し、4, 5を行いました。
4では縦持ちデータから横持ちデータへの変換をpandasのpivotを利用しました。2つのデータフレームの結合にpandasのmergeを用いて外部結合しました。
Pythonスクリプト1: Beautiful Soupでレイルラボのテキスト情報を取得
保存したcsvファイルは156430行のデータ(ファイルサイズは52 MB)となり、Excelではすべての行を読み込むことができませんでした。。。
鉄道写真を取得
次のコードを用いて鉄道写真の取得を行いました。保存したテキスト情報のcsvファイルを読み込み、urlを指定して、画像を取得後、photo_idを名前にしてファイルを保存しました。
156430個の写真を取得、ファイルサイズ合計は43.5 GBでした。
Pythonスクリプト2: テキスト情報からレイルラボの画像を取得して保存
3. 学習用データの前処理(データクレンジング)
最終的には、10種類の近鉄特急を判別対象に用いることにしましたが、最初は無知ゆえに、レイルラボから得られたほぼ全ての種類の車両を分析対象にしたいと考えていました。モデルの学習を進めるうちに、PCの性能や時間の制約のため、それは実現困難だと気が付きました。。。
近鉄沿線に住んでいるので、家族みな、特に近鉄特急(しまかぜ♡、ひのとり♡等々)には愛着があります。限られたリソースでアプリ開発を実現するために、近鉄特急に対象を絞ることにしました。
最初から対象を少数に絞って学習用データの前処理をしていれば、もっと楽だったのでしょうが、得られた15, 6万件全てのデータに対して前処理を行ったので、本アプリ開発において最も時間と労力を費やした作業となりました。この作業に1か月半ぐらいかけたと思います。
時間はかかりましたが、Python初心者の私にとっては、Pandasのデータフレームの操作やMatplotlibを使った画像の作成など、とてもよい勉強になりました。
スクレイピングしたテキストデータの精査、修正、ラベルの作成
学習用のラベルをつけることを最終目標に、次のようなデータの精査と修正を繰り返し行いました(順不同)
得られたテキスト情報(trains.csv)のうち、"鉄道会社名(company_name)"、"形式"、"編成"、"路線"、"車両"、"愛称"等の列情報を、Collections.counterを利用して、考察しやすいようにデータを要約(要素名と出現回数の情報が得られる)。ラベル(label)を設定した後は、ラベルに対しても行った(→ Pythonスクリプト3: Collections.counterを利用したtrains.csvデータの要約)。
1.のデータを利用して鉄道会社名を標準化(同じ鉄道会社でも、JR九州、JR九州旅客鉄道、九州旅客鉄道など、違う名前になっている場合が多数あるため、名前を揃えた)。1のcsvファイルに変更後の鉄道会社名を記載した。さらに、鉄道会社名から、日本または外国の鉄道かを判別し、国名情報を追加。(鉄道会社名から判別できないものはWebで調べた。)1のcsvファイルに国名情報を全て日本として追加し、外国の鉄道会社の場合に国名を変更(csvファイルを直接編集 → 鉄道会社名訂正用csv)。
2で得られた鉄道会社の情報のcsvファイルを利用して、trains.csvに国名情報、訂正済み鉄道会社情報を追加(→ Pythonスクリプト4: trains.csvに訂正した鉄道会社名と国名を追加)。
3で追加した国名情報から日本の鉄道会社のみを抜粋(→ Pythonスクリプト5: 日本の鉄道会社のみを抜粋)。
鉄道会社名、形式、編成などの情報を精査し、訓練用ラベルに適しているのは鉄道会社と形式であると判断した。"形式_鉄道会社名"をラベル付けの基本とした(→ Pythonスクリプト6: trains.csvにラベル付け)。
形式には系や形で登録されているものがあったり、同じ形式でも表記方法がバラバラであったりしたため、できるだけ情報を均一化。
間違えた登録情報を訂正。
同じラベルにしたくないもの(同じ系や形でも改造などにより見た目が別物になっているような場合)は、別ラベルを付与。
5, 6, 7については、画像ひとつひとつ確認して、どのように修正するかを判断し、修正内容をcsvに記録(→ 修正情報を記載したcsvファイル: fix_wrong_records2.csv)。csvを読み込み、プログラムで車両データデータの修正を実行(→ Pythonスクリプト7: 修正情報csvを読み込んでtrains.csvを修正)。
前面から電車の顔が映っていないものや、複数種類の車両が映っているもの、車両が小さすぎるものなどを学習対象から省く。省く対象のphoto_idと省いた理由を記載してcsvに保存。保存したcsvはモデル訓練時に利用した。
初めから近鉄特急に絞っていれば、膨大な時間を費やした、2, 5, 7の作業はほとんど手間がかからなかったと思います。。。
次に、前処理に利用したPythonスクリプトを一部紹介します。
Pythonスクリプト3: Collections.counterを利用したtrains.csvデータの要約
鉄道会社名訂正用csv (railway_companies.csv, 一部抜粋)
下表は鉄道会社名を訂正するために使用したcsv(Excelで表示)の一部を抜粋したものです。valueは元の名前、value_rは訂正後の名前です。訂正しない部分のvalue_rは空欄になっています。
Pythonスクリプト4: trains.csvに訂正した鉄道会社名と国名を追加
Pythonスクリプト5: 日本の鉄道会社のみを抜粋
Pythonスクリプト6: trains.csvにラベル付け
Pythonスクリプト7: 修正情報csvを読み込んでtrains.csvを修正
何パターンかtrains.csvを修正するためのスクリプトを作成しました。
以下のスクリプトは該当する列(col_name)の値がvalueに一致(match_typeがpartialの場合は部分一致、perfectの場合は完全一致)した場合、value_rの値に置き換えるというスクリプトです。未処理の列はcheckが1、処理済みの場合は9とし、checkが1の行のみ実行するようにしました。
修正情報を記載したcsvファイル: fix_wrong_records2.csv, 一部抜粋
Python初心者(私)が試行錯誤して書いたため、冗長な部分も多々あると思います。もっとスマートな書き方があれば、ぜひご指摘いただけるとうれしいです!
その2につづきます。
この記事が気に入ったらサポートをしてみませんか?