
Python(Flask)を使ったAIアプリ「近鉄特急どれかな?」の開発記録 その2~ モデルの作成と訓練 (tensorflow) ~

AIアプリ「近鉄特急どれかな?」について
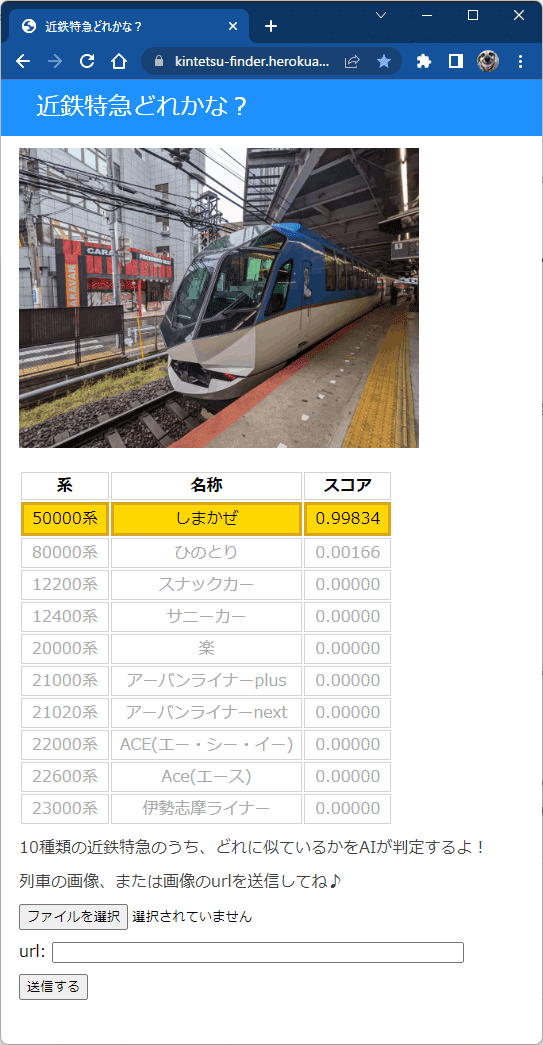
AIアプリ「近鉄特急どれかな?」は、画像ファイルを読み込む、または画像のurlを指定すると、10種類の近鉄特急のうち、どれに似ているかを判別します。
12200系 スナックカー
12400系 サニーカー
20000系 楽
21000系 アーバンライナーplus
21020系 アーバンライナーnext
22000系 ACE(エー・シー・イー)
22600系 Ace(エース)
23000系 伊勢志摩ライナー
50000系 しまかぜ
80000系 ひのとり
Webアプリ「近鉄特急どれかな?」はこちら
アプリ開発の流れ
テーマ決め
モデル学習用データを収集(Webスクレイピング)
学習用データの前処理(データクレンジング)
モデルの作成と訓練 (tensorflow) ←ココ
学習済みモデルの軽量化 (.h5から.tfliteへ変換)
Flaskでアプリの作成(ローカル環境)
本番環境の作成と公開(Heroku)
ここでは4.モデルの作成と学習について紹介します。
1 ~ 3(その1)はこちら
5(その3)はこちら
6, 7(その4)はこちら
Webアプリ「近鉄特急どれかな?」はこちら
Python実行環境
Windows11のWSL2内や、Google Colaboratory ProでPythonを実行しました。
PC1: Dell xps 13 2-in-1
プロセッサ Intel(R) Core(TM) i7-1065G7 CPU @ 1.30GHz 1.50 GHz
PC2: Surfase Laptop Studio
プロセッサ 11th Gen Intel(R) Core(TM) i7-11370H @ 3.30GHz 3.30 GHz
PC1、PC2共通事項
実装 RAM 32.0 GB
システムの種類 64 ビット オペレーティング システム、x64 ベース プロセッサ
エディション Windows 11 Pro
バージョン 21H2OS ビルド 22000.832
Ubuntuバージョン(WSL2): 22.04 LTS または 20.04 LTS
Pythonバージョン: 3.10.4
Pythonを編集、実行したエディター: Visual Studio Code
Python仮想環境について
ローカルPC (Wondiws 11 WSL2内のUbuntu)で開発を行うときは、作業ディレクトリ内に仮想環境を作成し、仮想環境内でスクリプトを実行しました。
ターミナルで作業ディレクトリに移動し、以下を実行すると仮想環境が作成されます。
python3 -m venv env
source ./env/bin/activate仮想環境から抜けるには、以下のコードを実行します。
deactivateGoogle Colaboratory
Googleが提供するPythonを記述できるWebアプリケーションです。
基本的な機能は無料で使えます。より性能が良いPro、Pro+は有料です。
4.モデルの学習は、ローカルPCやGoogle Colaboratoryでは時間がかかりすぎたり、終わらなかったりしたため、より多くの試行錯誤ができるよう、最終的にGoogle Colaboratory Pro(有料)を利用しました。
VGG16を使った転移学習モデル
Aidemyの講座、「男女識別(深層学習発展)」で学んだ手法を採用しました。CNN (Convolutional Neural Network、畳み込みニューラルネットワーク)のアルゴリズムを用いた事前学習済みのモデル(VGG16)に、別の新しいモデルを結合して学習を行う転移学習という手法です。
いちからモデルを定義することも考えましたが、3.学習用データの前処理に時間を使いすぎたので、ここはサクッと終わらせたいと思い、転移学習一択でいくことにしました。
モデルSummary
モデルの訓練時に工夫した点
今回、自分なりに工夫した点は次のとおりです。
学習につかうデータの数をすべてのラベルで同じになるように揃えた
各パラメータを変化させて検討するために繰り返し処理を行った
考察をしやすくするため、学習済みモデルの精度や学習に使用したデータのリストをcsvで保存した
学習用データが重すぎてエラーが出たため、訓練データの読み込みにジェネレータを利用することでエラーを回避した
画像の前処理 (OpenCV)
ライブラリOpenCVを使って画像の前処理をしました。予め前処理済みの画像を準備しておいたほうが、訓練時の負荷は減りますが、画像サイズも検討パラメータの一つだったため、訓練時に毎回前処理を行いました。
元画像を読み込み、正方形に加工した後(元画像のアスペクト比を固定、長いほうの辺の正方形とし、余白は黒とした)、訓練時のサイズにリサイズしました。

モデル訓練における検討内容と訓練結果
画像サイズ、Dense層の入力ユニット数、エポック数、バッチサイズ等のパラメータを変化させて検討しました。メモリの関係か、パラメータのサイズによってはエラーが出て実行できませんでした。
ラベル6種類から始め、いろいろ検討した後、最終的に10種類まで増やして再度検討を重ねました。
1ラベル当たり300枚の画像を学習に使用し、8割を訓練用、2割を検証用データとしました。ラベルの種類で画像の枚数が異ならないように、300枚に満たない種類のものは、ライブラリimbalanced-learnを利用し、予め水増しをして300枚に揃えました。
画像サイズは100 x 100から500 x 500まで100きざみで検討しました。
100や200では精度が上がらず、300, 400, 500はほぼ同等の精度でした。
最終的に、次のパラメータで最高精度(0.913)が得られました。
Dense層入力ユニット数: 1024
画像サイズ: 300 x 300
エポック数: 8
バッチサイズ: 64
モデル(.h5ファイル)のファイルサイズは390 MBでした。。。
モデルの作成と学習で作成したPythonスクリプト
Google Colaboratoryを使う場合
Google Colaboratoryを利用した場合には、解析結果を保存などのために、Google Driveをマウントしました。
from google.colab import drive
drive.mount('/content/drive')パスを通します。
import sys
import os
sys.path.append('/content/drive/My Drive/Colab Notebooks/train_app/scripts')作業フォルダに移動しておきます。
os.chdir("/content/drive/My Drive/Colab Notebooks/train_app/scripts")Pythonスクリプト: モデルの訓練と推測、各結果の保存
モデルの訓練と学習済みモデルの推測、各結果の保存に使用したスクリプトです。
冗長な部分も多々あると思いますがご容赦ください。。。
もっとスマートな書き方をご存じの方は、ぜひアドバイスをいただけるとうれしいです。
その3につづきます
余談
モデルの訓練のため、オーバーナイトでPC (Dell xps)を動かしていたところ、ぶっこわれました。。。なんかガリガリと異音がするぞ、ヒェー!と思っていたら、静かになってホッ。しかし、再起動したタイミングでエラーが。。。
「ファンが応答していません」
静かになったのは回るのをやめたからだったか。。。
結局、修理に出すことになり、マザーボード交換して、まっさらになって返却されてきました。えぇっ、Windows 10になってる。。。一からセットアップやり直し(泣)
しかしSurface Laptop Studio、高かったけど思い切って買っといてヨカッタ。。。
2つのPCでモデルの訓練を行いましたが、CPUの性能の差を実感しました。
SurfaceのほうがDellより2倍ぐらい速かったです。