第181回: 「統計の実務」40 抜け漏れ

◀前の記事へ 次の記事へ▶
≡ はじめに
前回は、「確率分布 その3(ポアソン分布の確率分布を使う)」でした。
内容は、ポアソン分布の確率グラフは「強度(=期待値=平均値=分散)のλのみ」で形が決まるから、数えることができる珍しい事象について、母集団の平均値を知っていれば発生した(もしくは、これから発生する)事象がどのくらい珍しいかを計算できるという話でした。
SQuBOKの下記の記載についても考えてみました。
システムテスト期間に発見される不具合の数や、プログラム1000行あたりの障害数がポアソン分布に従うとき、これらがある値以上となる確率を求めることなどに活用できる。
今回は、この連載を参照しやすいポータルページを作ろうと思っていました。
そして、作り始めたのですが、「記事の前後に移動できないとポータルページを作っても使いにくい」ということに気が付きました。
『そうだ。他のブロガーがやっているように、
【◀前の記事へ 次の記事へ▶】
リンクを全記事の最初と最後に挿入しよう』って思って、チマチマした作業を頑張りました(ほめてー(笑))。
チマチマした作業は大好きなので楽しかったです。
けど、2時間以上かかってしまいました。←毎回少しずつやれ。
前後の記事へのリンクを張るためにはすべてのページを開く必要があり、嫌でも自分の文章が目に入ります。そしたら、気づいてしまったのです。トピックスの抜け漏れに……。
気づいてしまったものは仕方ないので、最終回を次回に延期して、今回は抜けていたけれど大事なあれこれについて書きます。
≡ メトリクスと派生メトリクス
第1回目に「変数の種類」について書きました。そこに書いておくべきことだったのが、この「メトリクスと派生メトリクス」の違いについてです。
「メトリクスと派生メトリクス」のことをCMMIの日本語の教本では「基礎尺度と導出尺度」と訳しています。
基礎尺度: 直接測定で獲得する
導出尺度: 複数の基礎尺度を組み合わせたもの
※ 導出尺度は、比率、複数の指標の変化率を合成して指標にするコンポジットインデックス。またその他に、測定値を集計して要約した尺度として表現されることがよくある。
です。例えば、
基礎尺度: バグ数(件)、行数(行)
導出尺度: バグ密度(件/行)
です。
当たり前すぎて「それがなにか?」だと思うのですが、データを扱う実務において「基礎尺度との導出尺度の違いを頭においておくこと」は、めちゃめちゃ大切です。
例えば、バグ密度は、1000行単位で表し「5件/KLOC」というように表示することが多いものです。
2桁になったとしても、せいぜい、30件/KLOCというように2桁の小さいほうです。
それが、突然、Excelに「250件/KLOC」とかがでてビビるわけです。
バグ密度は導出尺度で「バグ数/開発行数」ですから、バグ修正のときなど、開発行数が少ないと1件のバグによって巨大な値になってしまいます。

≡ 密度、率、比率
上で、バグ密度という言葉を使いました。何も違和感なかったと思います。しかしあらためて「密度と率と比率の違いを教えてください」って新人君から質問を受けたら、困る人がいらっしゃるかもしれません。
「そんなの常識かなあ??」とツイートしたところ「常識じゃないです」とにしさんからリプライがあったので、そういうことにして説明します。
密度:density、ある規模の中に、それが含まれる度合
例: バグ密度(件/行数)、人口密度(人数/面積)
率:rate、何らかの基準値を基に測定した場合の比率や割合
例: この操作でバグが発生する率は1/100だ。
比率(比):ratio、2つの量の大きさの比、同じ単位で比較
例:役員の男女比率は9対1だ。
※ 英語だと「proportion」(全体に対する割合)も知っているといいかも。
日本語だと「率」だけで押し切れる気がしますが、英語だと単語を使い分けた方がいいみたいです。
≡ 変動係数(cv)
細かい話なのですが、
変動係数 = 標準偏差 / 平均です。変動係数は、英語で“Coefficient of Variation”といいますからcvと略されます。
いちいち英語を書いているのはRの出力を見るときに統計用語の英語がわかる方が良いから。
ばらつきを比較したいときに、平均値が大きいと標準偏差も大きいものですから、単純に標準偏差の大小で比較することが出来ません。
そこで、標準偏差を平均で割ったもの(変動係数)でばらつきを比較するというだけです。
Rコマンダーでも、メニューの[統計量]>[要約]>[数値による要約…]で開いたダイアログで[統計量]のタブを開いて「変動係数」にチェックを入れると計算してくれます。
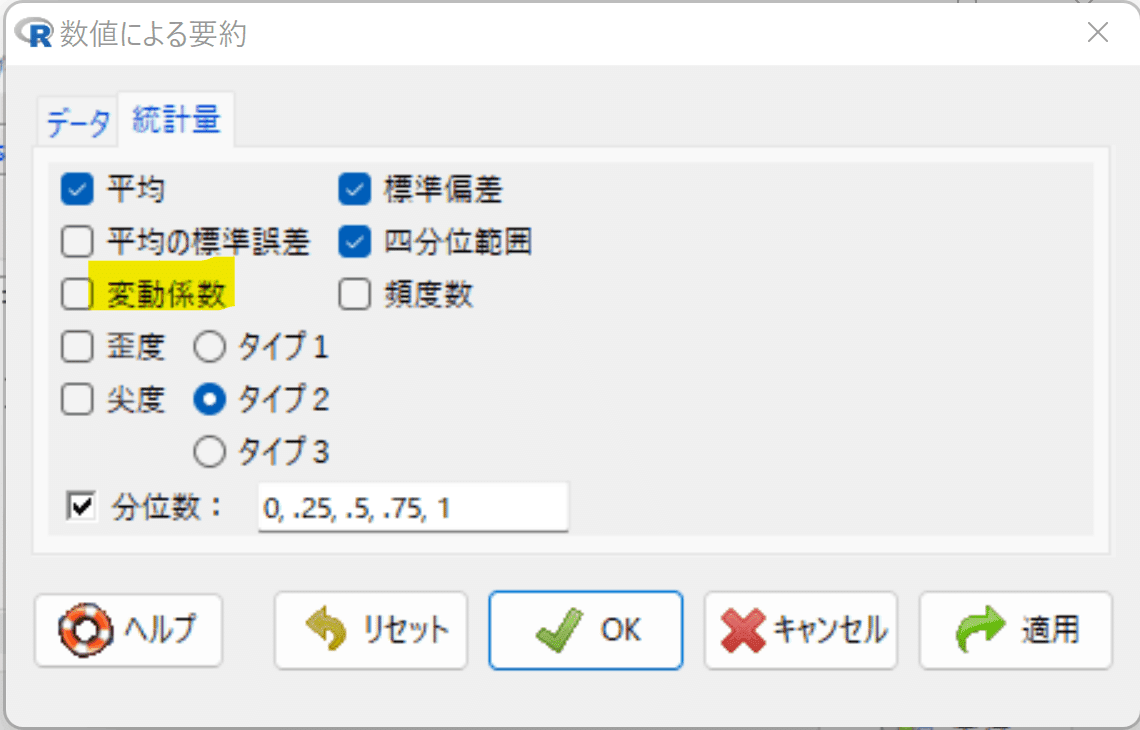
変動係数の目安ですが、「1以上だと、かなりばらついているデータ」であると判断します。
ただ、変動係数を求める前に、平均値と標準偏差が比例関係にある「比例尺度」であることを確認することの方が大切です。間隔尺度では使えません。また、値が負のときには使いません。
Rでも平均値が負の場合はcvは「NA」って出てしまいます。
≡ 歪度(skewness)と尖度(kurtosis)
上のダイアログをみて、『あっ、歪度と尖度の説明を忘れてた』と思いました。どちらも正規分布からのゆがみを数値であらわしたものです。歪度は横方向のゆがみで、尖度は縦方向のゆがみです。ですから、正規分布の歪度と尖度はどちらもゼロです。
歪度:skewness、正規分布からの横方向のひずみ(数値は歪の大きさ)
正:右の裾が長い(左側に山がある)
負:左の裾が長い(右側に山がある)
尖度:kurtosis、正規分布からの縦方向のひずみ
正:正規分布よりも尖っている
(鋭いピークと長く太い裾をもった分布)
負:正規分布よりも尖っていない
(丸みがかったピークと短く細い尾をもつ分布)
※ 元々は、4次の標準化モーメントの値が尖度でした。そして、正規分布の4次の標準化モーメントの値は 3です。
ところが、尖度は、正規分布との比較するときに使うことが多いので、3を引いた値を尖度とすることの方が多いです。英語では、3を引かない尖度をkurtosisといい、3を引く尖度のことをexcess kurtosisといいます。
※ 「尖度」(尖=とがり)と表現するのは誤解しやすいです。参考になる情報は、ウェブ上だと、英語のWikipediaくらいしかみつけられませんでした。
※ 正規分布かどうかを調べるだけならQQプロットを描いたり、シャピロ-ウィルクの正規性の検定を行う方が良いので、今となっては歪度や尖度の使うことはほとんどありません。
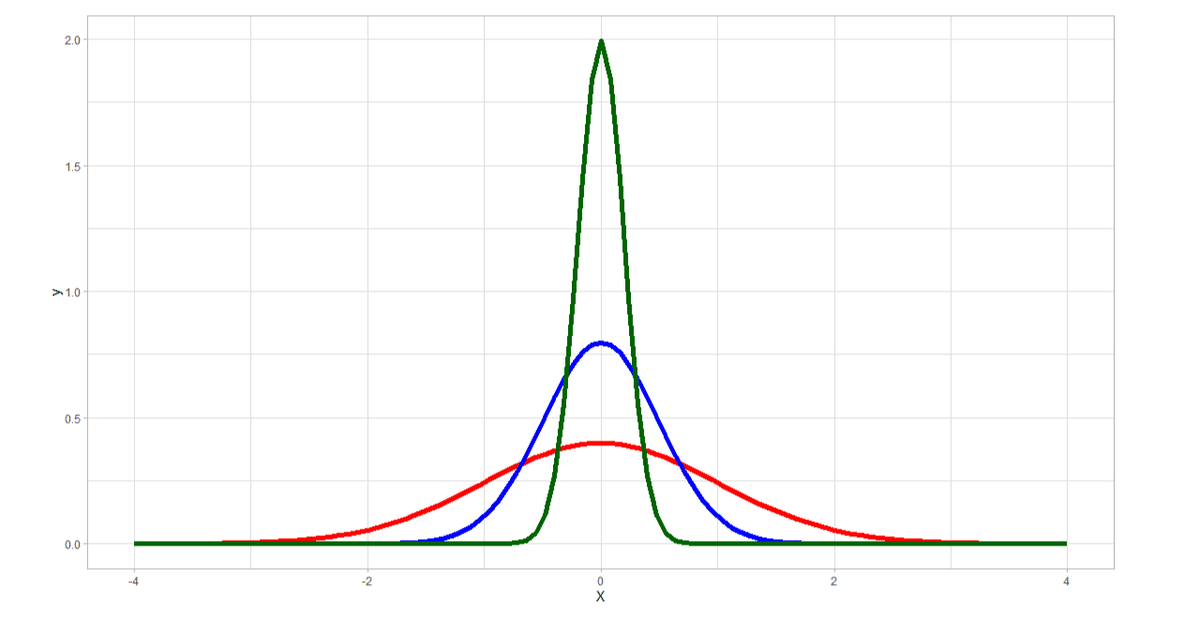
尖度のイメージを持つには、日本語のWikipediaの以下のグラフがわかりやすいと思います。

ちなみに、下グラフはすべて正規分布ですので、尖度はどれもゼロです。(尖って見えるのは緑ですが、スケールを変えたら重なるということは同じ尖度ということです)

上のグラフのソースを載せておきます。
library(tidyverse)
ggplot(data=data.frame(X=c(-4,4)), aes(x=X))+
stat_function(fun=dnorm, args=list(mean=0, sd=1), color="red", size=1.0)+
stat_function(fun=dnorm, args=list(mean=0, sd=.5), color="blue", size=1.0)+
stat_function(fun=dnorm, args=list(mean=0, sd=.2), color="darkgreen", size=1.0)+
theme_light()分かりやすいのは、正規分布とt分布の比較なのでは?と思い、書いてみました。青い線が正規分布で、赤い線がt分布(自由度=1)です。t分布の方が尖度が大きい(正の値)です。
自由度が大きくなれば、t分布は正規分布に重なりますので、尖度も0に収束します。
(t分布の尖度を、自由度を変えながらグラフにするとおもしろいですよ)

ということで、上のグラフのRスクリプトを残しておきます。
library(tidyverse)
ggplot(data=data.frame(X=c(-4,4)), aes(x=X))+
stat_function(fun=dnorm, # 正規分布
args=list(mean=0, sd=1),
color="blue", size=1.0)+
stat_function(fun=dt, # t分布
args = list(df = 1),
color="red",
size = 1.0) +
theme_light()以前出てきた、「カイ二乗分布」は、歪度も尖度も違いますね。
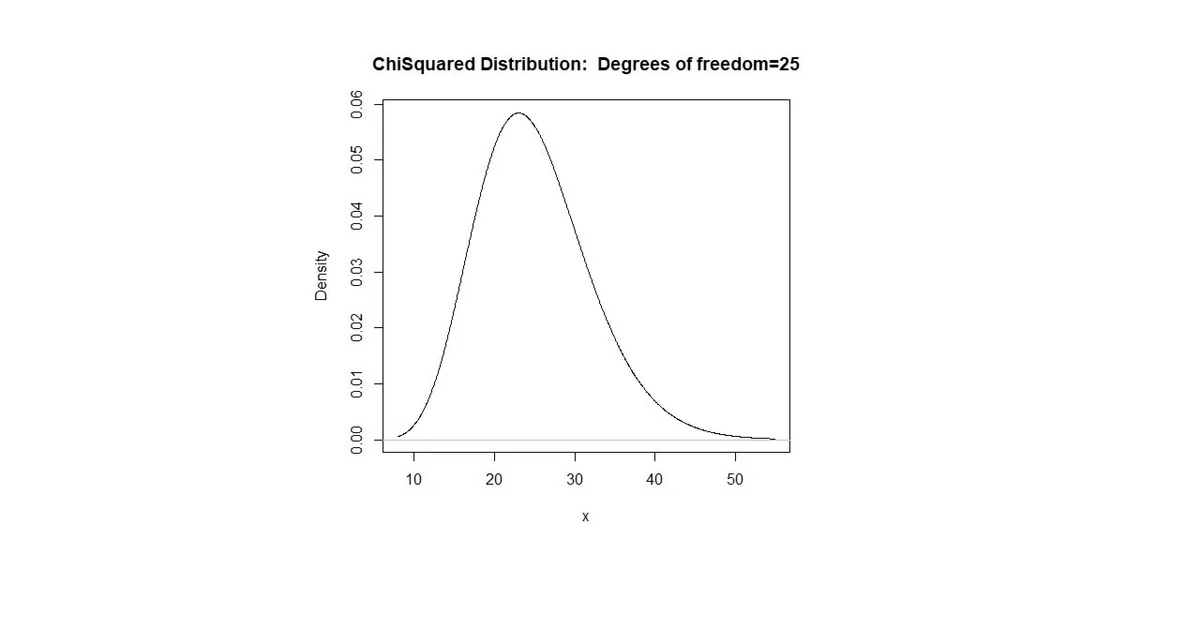
カイ二乗分布は、歪度も尖度も正です。なかなか正規分布に収束しないけど。
≡ AIC
重回帰分析のところで、AICについても書いておいた方が良かったかもと思いました。重回帰分析中に説明変数を増減させたときに、AICの値を見て小さくなっていたらよりモデルに当てはまると思ってください。
≡ おわりに
今回は、抜けていた情報の補足でした。
次回こそ、本連載の最終回です。これまでの連載を参照しやすくなるようにポータルページを作ろうと思っています。
◀前の記事へ 次の記事へ▶
この記事が気に入ったらサポートをしてみませんか?